 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonium : A Unified, Efficient Library of Orthogonal and 1-Lipschitz Building Blocks
Jan 20, 2026Orthogonal and 1-Lipschitz neural network layers are essential building blocks in robust deep learning architectures, crucial for certified adversarial robustness, stable generative models, and reliable recurrent networks. Despite significant advancements, existing implementations remain fragmented, limited, and computationally demanding. To address these issues, we introduce Orthogonium , a unified, efficient, and comprehensive PyTorch library providing orthogonal and 1-Lipschitz layers. Orthogonium provides access to standard convolution features-including support for strides, dilation, grouping, and transposed-while maintaining strict mathematical guarantees. Its optimized implementations reduce overhead on large scale benchmarks such as ImageNet. Moreover, rigorous testing within the library has uncovered critical errors in existing implementations, emphasizing the importance of standardized and reliable tools. Orthogonium thus significantly lowers adoption barriers, enabling scalable experimentation and integration across diverse applications requiring orthogonality and robust Lipschitz constraints. Orthogonium is available at https://github.com/deel-ai/orthogonium.
Back to the Baseline: Examining Baseline Effects on Explainability Metrics
Dec 12, 2025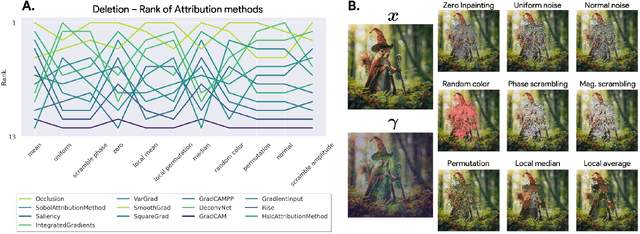
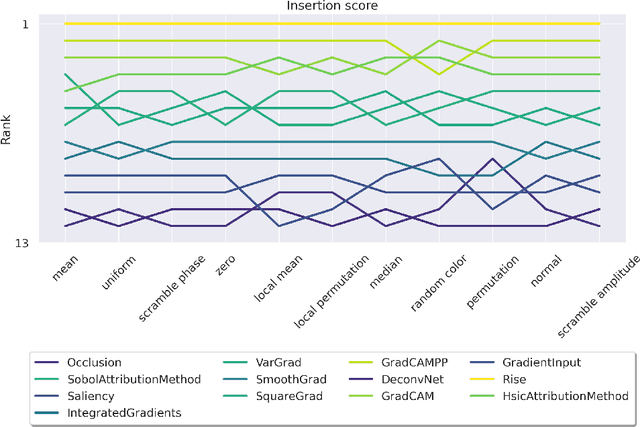
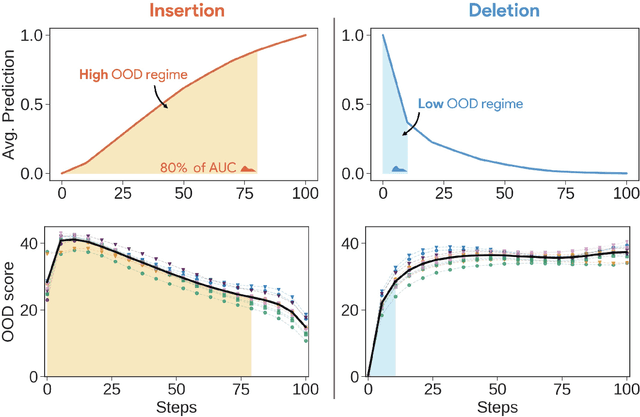
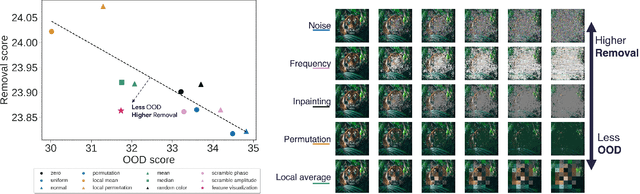
Attribution methods are among the most prevalent techniques in Explainable Artificial Intelligence (XAI) and are usually evaluated and compared using Fidelity metrics, with Insertion and Deletion being the most popular. These metrics rely on a baseline function to alter the pixels of the input image that the attribution map deems most important. In this work, we highlight a critical problem with these metrics: the choice of a given baseline will inevitably favour certain attribution methods over others. More concerningly, even a simple linear model with commonly used baselines contradicts itself by designating different optimal methods. A question then arises: which baseline should we use? We propose to study this problem through two desirable properties of a baseline: (i) that it removes information and (ii) that it does not produce overly out-of-distribution (OOD) images. We first show that none of the tested baselines satisfy both criteria, and there appears to be a trade-off among current baselines: either they remove information or they produce a sequence of OOD images. Finally, we introduce a novel baseline by leveraging recent work in feature visualisation to artificially produce a model-dependent baseline that removes information without being overly OOD, thus improving on the trade-off when compared to other existing baselines. Our code is available at https://github.com/deel-ai-papers/Back-to-the-Baseline
Efficient Robust Conformal Prediction via Lipschitz-Bounded Networks
Jun 05, 2025



Conformal Prediction (CP) has proven to be an effective post-hoc method for improving the trustworthiness of neural networks by providing prediction sets with finite-sample guarantees. However, under adversarial attacks, classical conformal guarantees do not hold anymore: this problem is addressed in the field of Robust Conformal Prediction. Several methods have been proposed to provide robust CP sets with guarantees under adversarial perturbations, but, for large scale problems, these sets are either too large or the methods are too computationally demanding to be deployed in real life scenarios. In this work, we propose a new method that leverages Lipschitz-bounded networks to precisely and efficiently estimate robust CP sets. When combined with a 1-Lipschitz robust network, we demonstrate that our lip-rcp method outperforms state-of-the-art results in both the size of the robust CP sets and computational efficiency in medium and large-scale scenarios such as ImageNet. Taking a different angle, we also study vanilla CP under attack, and derive new worst-case coverage bounds of vanilla CP sets, which are valid simultaneously for all adversarial attack levels. Our lip-rcp method makes this second approach as efficient as vanilla CP while also allowing robustness guarantees.
An Adaptive Orthogonal Convolution Scheme for Efficient and Flexible CNN Architectures
Jan 14, 2025



Orthogonal convolutional layers are the workhorse of multiple areas in machine learning, such as adversarial robustness, normalizing flows, GANs, and Lipschitzconstrained models. Their ability to preserve norms and ensure stable gradient propagation makes them valuable for a large range of problems. Despite their promise, the deployment of orthogonal convolution in large-scale applications is a significant challenge due to computational overhead and limited support for modern features like strides, dilations, group convolutions, and transposed convolutions.In this paper, we introduce AOC (Adaptative Orthogonal Convolution), a scalable method for constructing orthogonal convolutions, effectively overcoming these limitations. This advancement unlocks the construction of architectures that were previously considered impractical. We demonstrate through our experiments that our method produces expressive models that become increasingly efficient as they scale. To foster further advancement, we provide an open-source library implementing this method, available at https://github.com/thib-s/orthogonium.
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
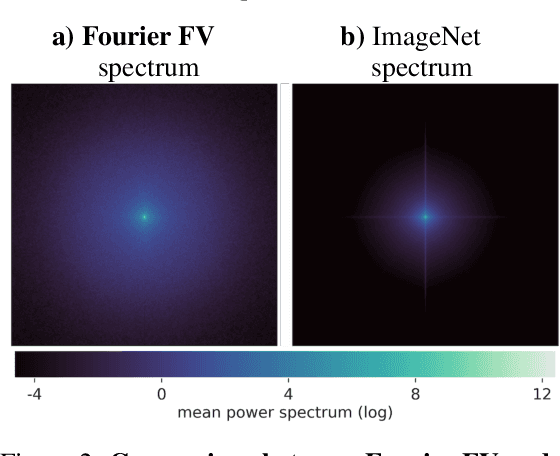
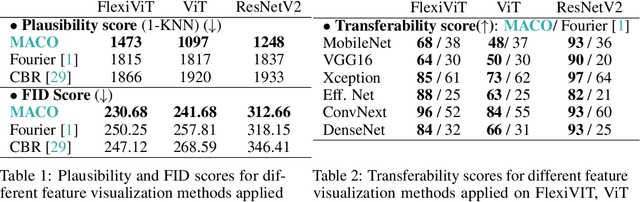
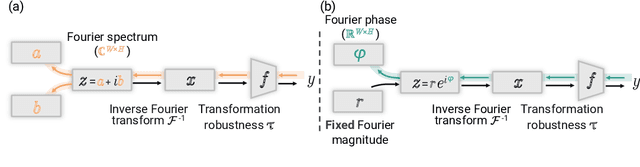
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
Adversarial alignment: Breaking the trade-off between the strength of an attack and its relevance to human perception
Jun 05, 2023
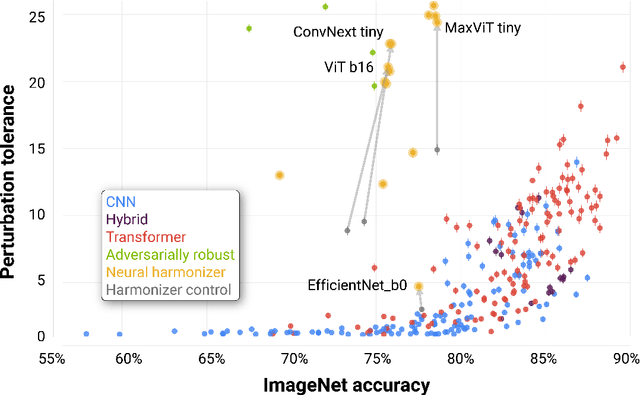
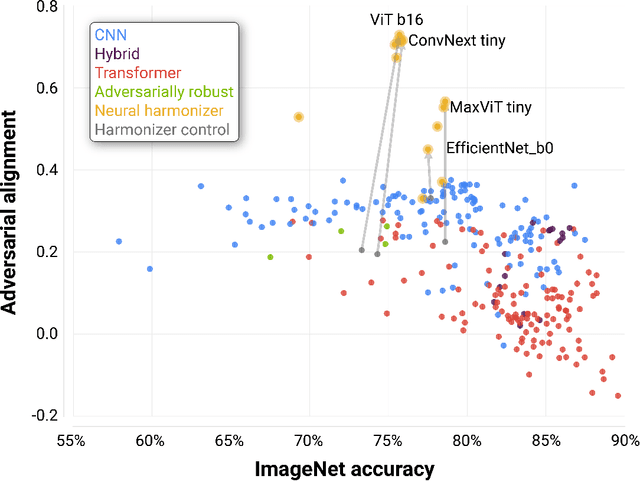
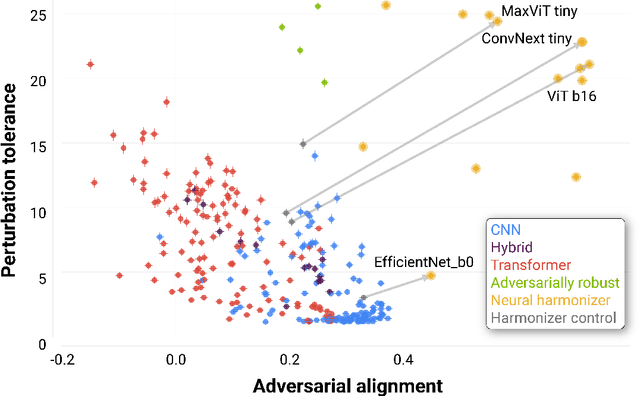
Deep neural networks (DNNs) are known to have a fundamental sensitivity to adversarial attacks, perturbations of the input that are imperceptible to humans yet powerful enough to change the visual decision of a model. Adversarial attacks have long been considered the "Achilles' heel" of deep learning, which may eventually force a shift in modeling paradigms. Nevertheless, the formidable capabilities of modern large-scale DNNs have somewhat eclipsed these early concerns. Do adversarial attacks continue to pose a threat to DNNs? Here, we investigate how the robustness of DNNs to adversarial attacks has evolved as their accuracy on ImageNet has continued to improve. We measure adversarial robustness in two different ways: First, we measure the smallest adversarial attack needed to cause a model to change its object categorization decision. Second, we measure how aligned successful attacks are with the features that humans find diagnostic for object recognition. We find that adversarial attacks are inducing bigger and more easily detectable changes to image pixels as DNNs grow better on ImageNet, but these attacks are also becoming less aligned with features that humans find diagnostic for recognition. To better understand the source of this trade-off, we turn to the neural harmonizer, a DNN training routine that encourages models to leverage the same features as humans to solve tasks. Harmonized DNNs achieve the best of both worlds and experience attacks that are detectable and affect features that humans find diagnostic for recognition, meaning that attacks on these models are more likely to be rendered ineffective by inducing similar effects on human perception. Our findings suggest that the sensitivity of DNNs to adversarial attacks can be mitigated by DNN scale, data scale, and training routines that align models with biological intelligence.
DP-SGD Without Clipping: The Lipschitz Neural Network Way
May 25, 2023



State-of-the-art approaches for training Differentially Private (DP) Deep Neural Networks (DNN) faces difficulties to estimate tight bounds on the sensitivity of the network's layers, and instead rely on a process of per-sample gradient clipping. This clipping process not only biases the direction of gradients but also proves costly both in memory consumption and in computation. To provide sensitivity bounds and bypass the drawbacks of the clipping process, our theoretical analysis of Lipschitz constrained networks reveals an unexplored link between the Lipschitz constant with respect to their input and the one with respect to their parameters. By bounding the Lipschitz constant of each layer with respect to its parameters we guarantee DP training of these networks. This analysis not only allows the computation of the aforementioned sensitivities at scale but also provides leads on to how maximize the gradient-to-noise ratio for fixed privacy guarantees. To facilitate the application of Lipschitz networks and foster robust and certifiable learning under privacy guarantees, we provide a Python package that implements building blocks allowing the construction and private training of such networks.
CRAFT: Concept Recursive Activation FacTorization for Explainability
Nov 17, 2022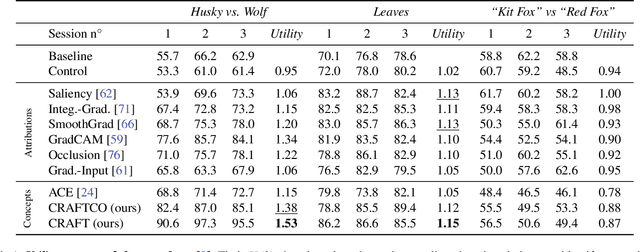

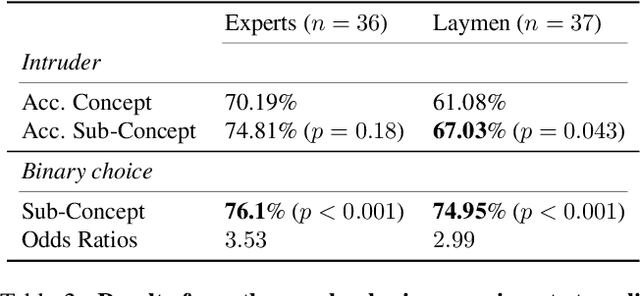
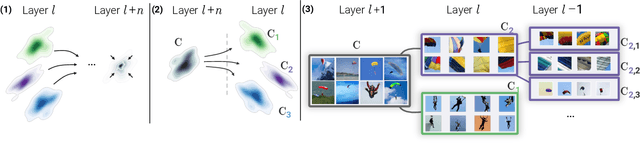
Attribution methods are a popular class of explainability methods that use heatmaps to depict the most important areas of an image that drive a model decision. Nevertheless, recent work has shown that these methods have limited utility in practice, presumably because they only highlight the most salient parts of an image (i.e., 'where' the model looked) and do not communicate any information about 'what' the model saw at those locations. In this work, we try to fill in this gap with CRAFT -- a novel approach to identify both 'what' and 'where' by generating concept-based explanations. We introduce 3 new ingredients to the automatic concept extraction literature: (i) a recursive strategy to detect and decompose concepts across layers, (ii) a novel method for a more faithful estimation of concept importance using Sobol indices, and (iii) the use of implicit differentiation to unlock Concept Attribution Maps. We conduct both human and computer vision experiments to demonstrate the benefits of the proposed approach. We show that our recursive decomposition generates meaningful and accurate concepts and that the proposed concept importance estimation technique is more faithful to the model than previous methods. When evaluating the usefulness of the method for human experimenters on a human-defined utility benchmark, we find that our approach significantly improves on two of the three test scenarios (while none of the current methods including ours help on the third). Overall, our study suggests that, while much work remains toward the development of general explainability methods that are useful in practical scenarios, the identification of meaningful concepts at the proper level of granularity yields useful and complementary information beyond that afforded by attribution methods.
When adversarial attacks become interpretable counterfactual explanations
Jun 14, 2022
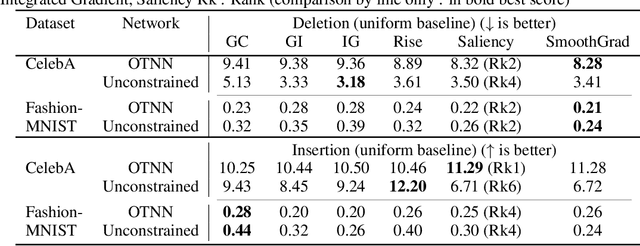
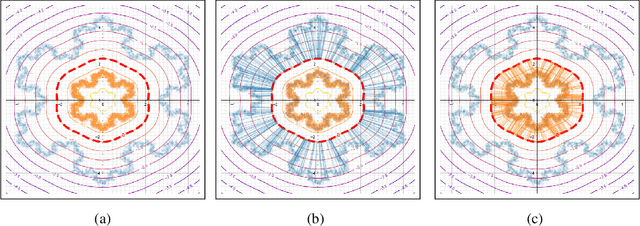
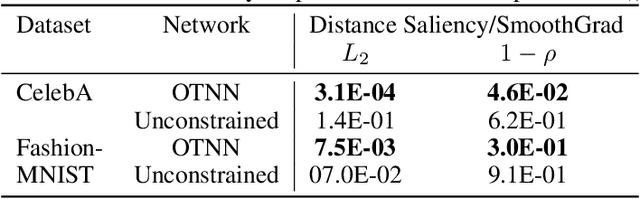
We argue that, when learning a 1-Lipschitz neural network with the dual loss of an optimal transportation problem, the gradient of the model is both the direction of the transportation plan and the direction to the closest adversarial attack. Traveling along the gradient to the decision boundary is no more an adversarial attack but becomes a counterfactual explanation, explicitly transporting from one class to the other. Through extensive experiments on XAI metrics, we find that the simple saliency map method, applied on such networks, becomes a reliable explanation, and outperforms the state-of-the-art explanation approaches on unconstrained models. The proposed networks were already known to be certifiably robust, and we prove that they are also explainable with a fast and simple method.
Xplique: A Deep Learning Explainability Toolbox
Jun 09, 2022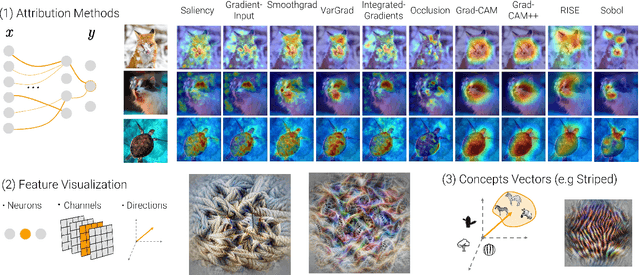
Today's most advanced machine-learning models are hardly scrutable. The key challenge for explainability methods is to help assisting researchers in opening up these black boxes, by revealing the strategy that led to a given decision, by characterizing their internal states or by studying the underlying data representation. To address this challenge, we have developed Xplique: a software library for explainability which includes representative explainability methods as well as associated evaluation metrics. It interfaces with one of the most popular learning libraries: Tensorflow as well as other libraries including PyTorch, scikit-learn and Theano. The code is licensed under the MIT license and is freely available at github.com/deel-ai/xplique.