 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Baseline: Examining Baseline Effects on Explainability Metrics
Dec 12, 2025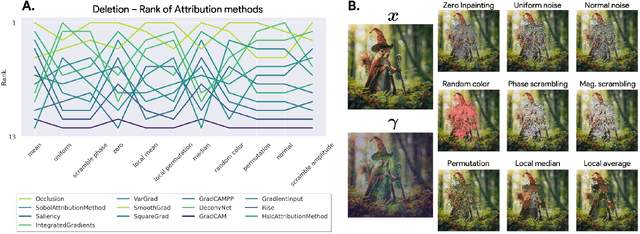
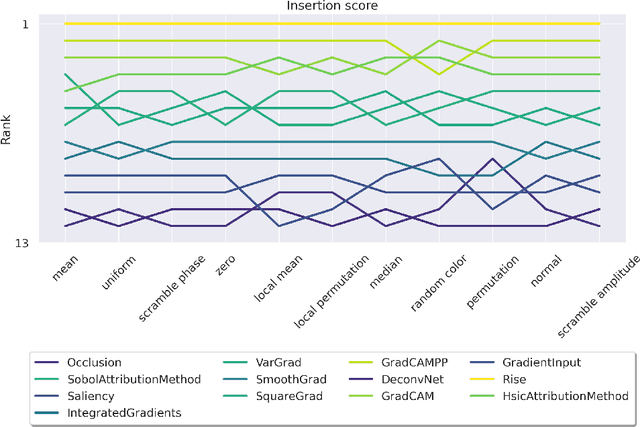
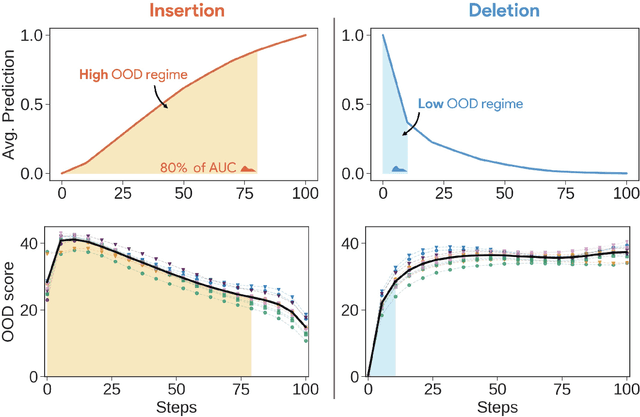
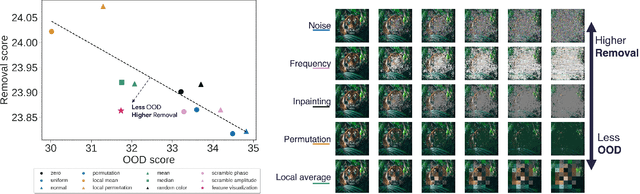
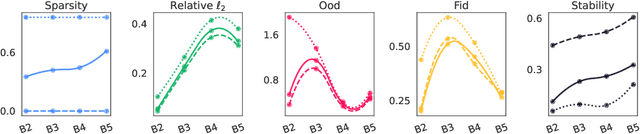
Attribution methods are among the most prevalent techniques in Explainable Artificial Intelligence (XAI) and are usually evaluated and compared using Fidelity metrics, with Insertion and Deletion being the most popular. These metrics rely on a baseline function to alter the pixels of the input image that the attribution map deems most important. In this work, we highlight a critical problem with these metrics: the choice of a given baseline will inevitably favour certain attribution methods over others. More concerningly, even a simple linear model with commonly used baselines contradicts itself by designating different optimal methods. A question then arises: which baseline should we use? We propose to study this problem through two desirable properties of a baseline: (i) that it removes information and (ii) that it does not produce overly out-of-distribution (OOD) images. We first show that none of the tested baselines satisfy both criteria, and there appears to be a trade-off among current baselines: either they remove information or they produce a sequence of OOD images. Finally, we introduce a novel baseline by leveraging recent work in feature visualisation to artificially produce a model-dependent baseline that removes information without being overly OOD, thus improving on the trade-off when compared to other existing baselines. Our code is available at https://github.com/deel-ai-papers/Back-to-the-Baseline
A Holistic Approach to Unifying Automatic Concept Extraction and Concept Importance Estimation
Jun 11, 2023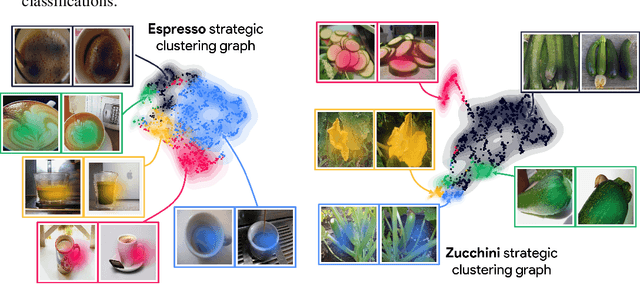


In recent years, concept-based approaches have emerged as some of the most promising explainability methods to help us interpret the decisions of Artificial Neural Networks (ANNs). These methods seek to discover intelligible visual 'concepts' buried within the complex patterns of ANN activations in two key steps: (1) concept extraction followed by (2) importance estimation. While these two steps are shared across methods, they all differ in their specific implementations. Here, we introduce a unifying theoretical framework that comprehensively defines and clarifies these two steps. This framework offers several advantages as it allows us: (i) to propose new evaluation metrics for comparing different concept extraction approaches; (ii) to leverage modern attribution methods and evaluation metrics to extend and systematically evaluate state-of-the-art concept-based approaches and importance estimation techniques; (iii) to derive theoretical guarantees regarding the optimality of such methods. We further leverage our framework to try to tackle a crucial question in explainability: how to efficiently identify clusters of data points that are classified based on a similar shared strategy. To illustrate these findings and to highlight the main strategies of a model, we introduce a visual representation called the strategic cluster graph. Finally, we present https://serre-lab.github.io/Lens, a dedicated website that offers a complete compilation of these visualizations for all classes of the ImageNet dataset.
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
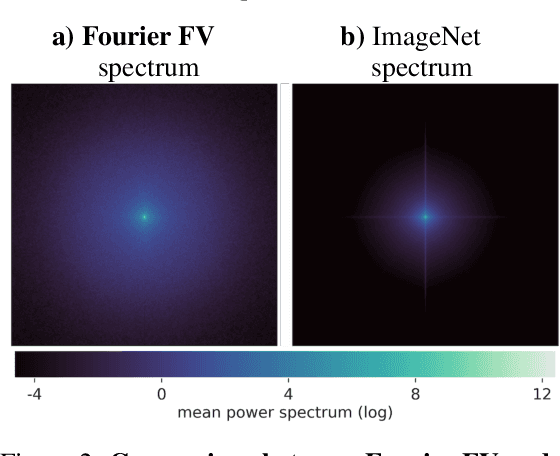
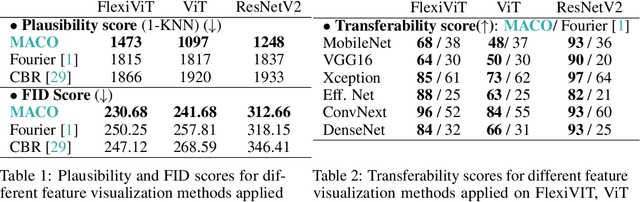
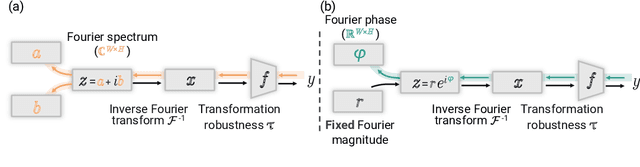
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
CRAFT: Concept Recursive Activation FacTorization for Explainability
Nov 17, 2022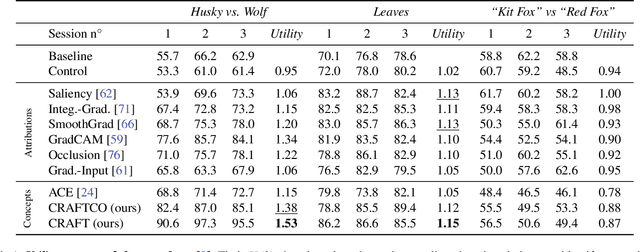

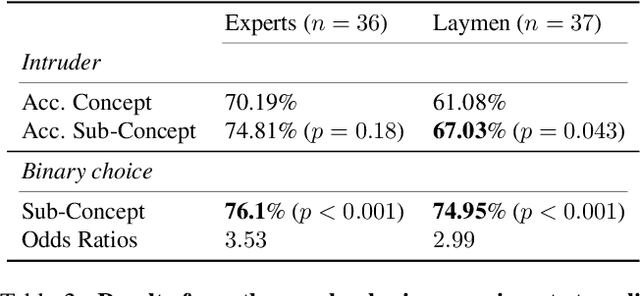
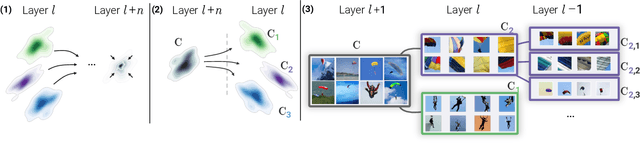
Attribution methods are a popular class of explainability methods that use heatmaps to depict the most important areas of an image that drive a model decision. Nevertheless, recent work has shown that these methods have limited utility in practice, presumably because they only highlight the most salient parts of an image (i.e., 'where' the model looked) and do not communicate any information about 'what' the model saw at those locations. In this work, we try to fill in this gap with CRAFT -- a novel approach to identify both 'what' and 'where' by generating concept-based explanations. We introduce 3 new ingredients to the automatic concept extraction literature: (i) a recursive strategy to detect and decompose concepts across layers, (ii) a novel method for a more faithful estimation of concept importance using Sobol indices, and (iii) the use of implicit differentiation to unlock Concept Attribution Maps. We conduct both human and computer vision experiments to demonstrate the benefits of the proposed approach. We show that our recursive decomposition generates meaningful and accurate concepts and that the proposed concept importance estimation technique is more faithful to the model than previous methods. When evaluating the usefulness of the method for human experimenters on a human-defined utility benchmark, we find that our approach significantly improves on two of the three test scenarios (while none of the current methods including ours help on the third). Overall, our study suggests that, while much work remains toward the development of general explainability methods that are useful in practical scenarios, the identification of meaningful concepts at the proper level of granularity yields useful and complementary information beyond that afforded by attribution methods.
Images & Recipes: Retrieval in the cooking context
May 02, 2018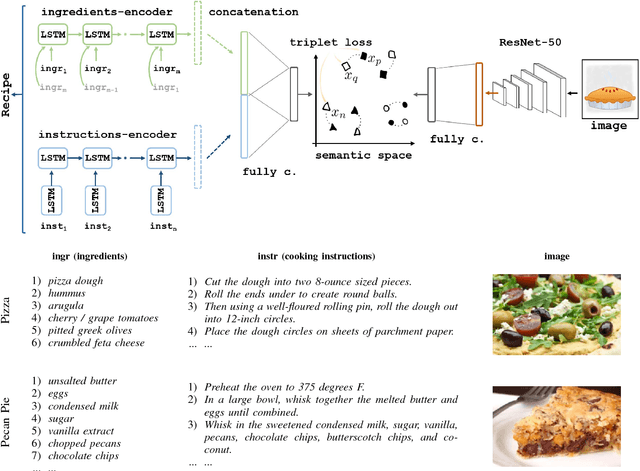



Recent advances in the machine learning community allowed different use cases to emerge, as its association to domains like cooking which created the computational cuisine. In this paper, we tackle the picture-recipe alignment problem, having as target application the large-scale retrieval task (finding a recipe given a picture, and vice versa). Our approach is validated on the Recipe1M dataset, composed of one million image-recipe pairs and additional class information, for which we achieve state-of-the-art results.
Cross-Modal Retrieval in the Cooking Context: Learning Semantic Text-Image Embeddings
Apr 30, 2018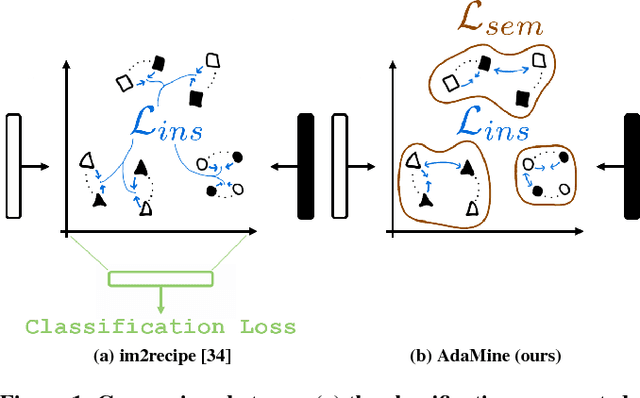

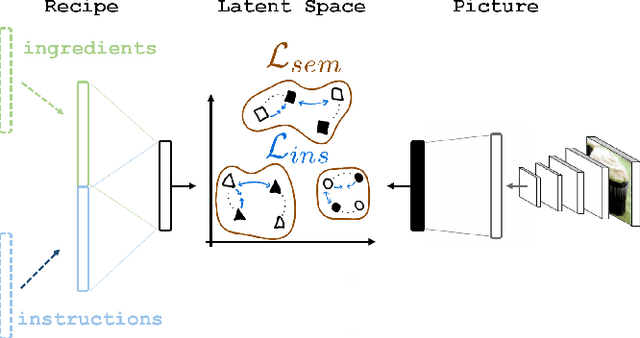
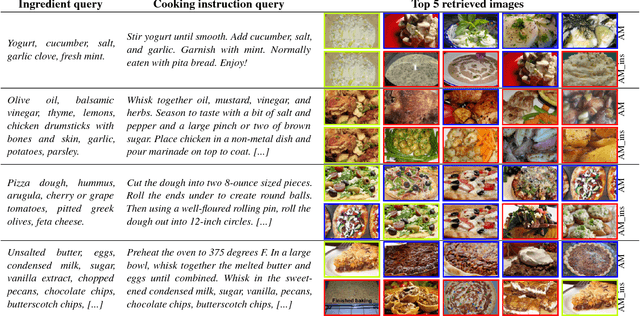
Designing powerful tools that support cooking activities has rapidly gained popularity due to the massive amounts of available data, as well as recent advances in machine learning that are capable of analyzing them. In this paper, we propose a cross-modal retrieval model aligning visual and textual data (like pictures of dishes and their recipes) in a shared representation space. We describe an effective learning scheme, capable of tackling large-scale problems, and validate it on the Recipe1M dataset containing nearly 1 million picture-recipe pairs. We show the effectiveness of our approach regarding previous state-of-the-art models and present qualitative results over computational cooking use cases.
M2CAI Workflow Challenge: Convolutional Neural Networks with Time Smoothing and Hidden Markov Model for Video Frames Classification
Dec 02, 2016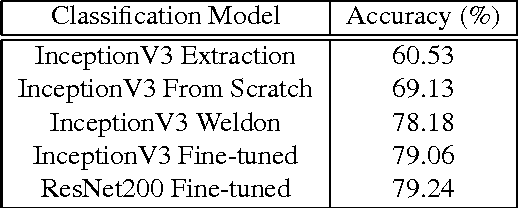
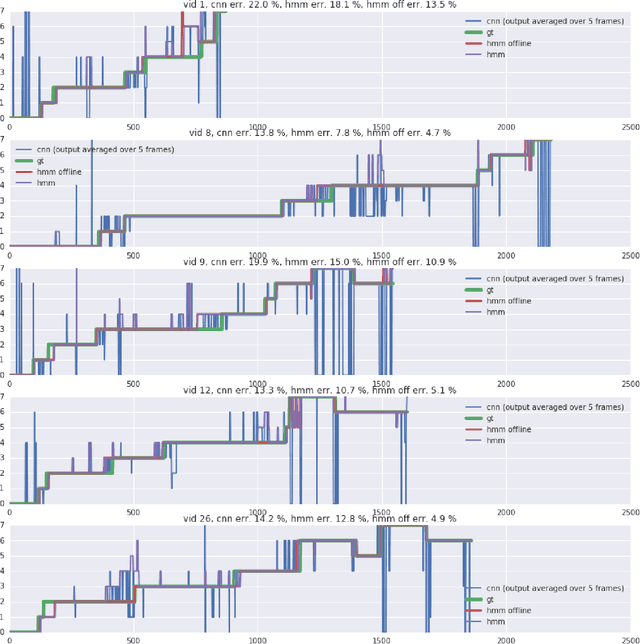

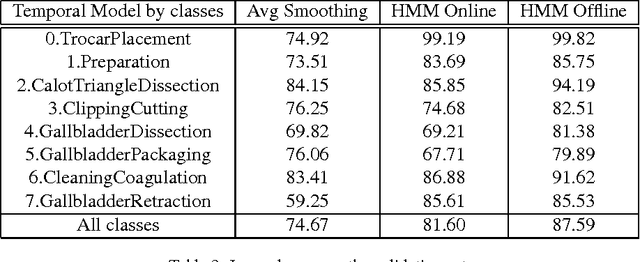
Our approach is among the three best to tackle the M2CAI Workflow challenge. The latter consists in recognizing the operation phase for each frames of endoscopic videos. In this technical report, we compare several classification models and temporal smoothing methods. Our submitted solution is a fine tuned Residual Network-200 on 80% of the training set with temporal smoothing using simple temporal averaging of the predictions and a Hidden Markov Model modeling the sequence.
Master's Thesis : Deep Learning for Visual Recognition
Oct 18, 2016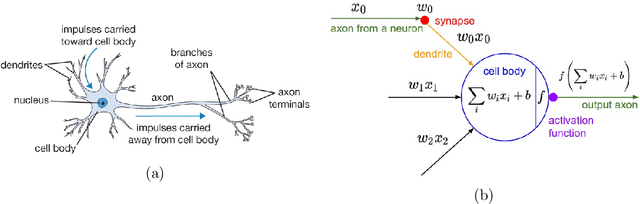



The goal of our research is to develop methods advancing automatic visual recognition. In order to predict the unique or multiple labels associated to an image, we study different kind of Deep Neural Networks architectures and methods for supervised features learning. We first draw up a state-of-the-art review of the Convolutional Neural Networks aiming to understand the history behind this family of statistical models, the limit of modern architectures and the novel techniques currently used to train deep CNNs. The originality of our work lies in our approach focusing on tasks with a low amount of data. We introduce different models and techniques to achieve the best accuracy on several kind of datasets, such as a medium dataset of food recipes (100k images) for building a web API, or a small dataset of satellite images (6,000) for the DSG online challenge that we've won. We also draw up the state-of-the-art in Weakly Supervised Learning, introducing different kind of CNNs able to localize regions of interest. Our last contribution is a framework, build on top of Torch7, for training and testing deep models on any visual recognition tasks and on datasets of any scale.