 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyePack: Provably Flagging Test Set Contamination in LLMs Using Backdoors
May 29, 2025Open benchmarks are essential for evaluating and advancing large language models, offering reproducibility and transparency. However, their accessibility makes them likely targets of test set contamination. In this work, we introduce DyePack, a framework that leverages backdoor attacks to identify models that used benchmark test sets during training, without requiring access to the loss, logits, or any internal details of the model. Like how banks mix dye packs with their money to mark robbers, DyePack mixes backdoor samples with the test data to flag models that trained on it. We propose a principled design incorporating multiple backdoors with stochastic targets, enabling exact false positive rate (FPR) computation when flagging every model. This provably prevents false accusations while providing strong evidence for every detected case of contamination. We evaluate DyePack on five models across three datasets, covering both multiple-choice and open-ended generation tasks. For multiple-choice questions, it successfully detects all contaminated models with guaranteed FPRs as low as 0.000073% on MMLU-Pro and 0.000017% on Big-Bench-Hard using eight backdoors. For open-ended generation tasks, it generalizes well and identifies all contaminated models on Alpaca with a guaranteed false positive rate of just 0.127% using six backdoors.
Seeing What's Not There: Spurious Correlation in Multimodal LLMs
Mar 11, 2025Unimodal vision models are known to rely on spurious correlations, but it remains unclear to what extent Multimodal Large Language Models (MLLMs) exhibit similar biases despite language supervision. In this paper, we investigate spurious bias in MLLMs and introduce SpurLens, a pipeline that leverages GPT-4 and open-set object detectors to automatically identify spurious visual cues without human supervision. Our findings reveal that spurious correlations cause two major failure modes in MLLMs: (1) over-reliance on spurious cues for object recognition, where removing these cues reduces accuracy, and (2) object hallucination, where spurious cues amplify the hallucination by over 10x. We validate our findings in various MLLMs and datasets. Beyond diagnosing these failures, we explore potential mitigation strategies, such as prompt ensembling and reasoning-based prompting, and conduct ablation studies to examine the root causes of spurious bias in MLLMs. By exposing the persistence of spurious correlations, our study calls for more rigorous evaluation methods and mitigation strategies to enhance the reliability of MLLMs.
Unearthing Skill-Level Insights for Understanding Trade-Offs of Foundation Models
Oct 17, 2024



With models getting stronger, evaluations have grown more complex, testing multiple skills in one benchmark and even in the same instance at once. However, skill-wise performance is obscured when inspecting aggregate accuracy, under-utilizing the rich signal modern benchmarks contain. We propose an automatic approach to recover the underlying skills relevant for any evaluation instance, by way of inspecting model-generated rationales. After validating the relevance of rationale-parsed skills and inferring skills for $46$k instances over $12$ benchmarks, we observe many skills to be common across benchmarks, resulting in the curation of hundreds of skill-slices (i.e. sets of instances testing a common skill). Inspecting accuracy over these slices yields novel insights on model trade-offs: e.g., compared to GPT-4o and Claude 3.5 Sonnet, on average, Gemini 1.5 Pro is $18\%$ more accurate in "computing molar mass", but $19\%$ less accurate in "applying constitutional law", despite the overall accuracies of the three models differing by a mere $0.4\%$. Furthermore, we demonstrate the practical utility of our approach by showing that insights derived from skill slice analysis can generalize to held-out instances: when routing each instance to the model strongest on the relevant skills, we see a $3\%$ accuracy improvement over our $12$ dataset corpus. Our skill-slices and framework open a new avenue in model evaluation, leveraging skill-specific analyses to unlock a more granular and actionable understanding of model capabilities.
Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Jun 12, 2024



Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {\it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Embracing Diversity: Interpretable Zero-shot classification beyond one vector per class
Apr 25, 2024



Vision-language models enable open-world classification of objects without the need for any retraining. While this zero-shot paradigm marks a significant advance, even today's best models exhibit skewed performance when objects are dissimilar from their typical depiction. Real world objects such as pears appear in a variety of forms -- from diced to whole, on a table or in a bowl -- yet standard VLM classifiers map all instances of a class to a \it{single vector based on the class label}. We argue that to represent this rich diversity within a class, zero-shot classification should move beyond a single vector. We propose a method to encode and account for diversity within a class using inferred attributes, still in the zero-shot setting without retraining. We find our method consistently outperforms standard zero-shot classification over a large suite of datasets encompassing hierarchies, diverse object states, and real-world geographic diversity, as well finer-grained datasets where intra-class diversity may be less prevalent. Importantly, our method is inherently interpretable, offering faithful explanations for each inference to facilitate model debugging and enhance transparency. We also find our method scales efficiently to a large number of attributes to account for diversity -- leading to more accurate predictions for atypical instances. Finally, we characterize a principled trade-off between overall and worst class accuracy, which can be tuned via a hyperparameter of our method. We hope this work spurs further research into the promise of zero-shot classification beyond a single class vector for capturing diversity in the world, and building transparent AI systems without compromising performance.
Rethinking Artistic Copyright Infringements in the Era of Text-to-Image Generative Models
Apr 11, 2024



Recent text-to-image generative models such as Stable Diffusion are extremely adept at mimicking and generating copyrighted content, raising concerns amongst artists that their unique styles may be improperly copied. Understanding how generative models copy "artistic style" is more complex than duplicating a single image, as style is comprised by a set of elements (or signature) that frequently co-occurs across a body of work, where each individual work may vary significantly. In our paper, we first reformulate the problem of "artistic copyright infringement" to a classification problem over image sets, instead of probing image-wise similarities. We then introduce ArtSavant, a practical (i.e., efficient and easy to understand) tool to (i) determine the unique style of an artist by comparing it to a reference dataset of works from 372 artists curated from WikiArt, and (ii) recognize if the identified style reappears in generated images. We leverage two complementary methods to perform artistic style classification over image sets, includingTagMatch, which is a novel inherently interpretable and attributable method, making it more suitable for broader use by non-technical stake holders (artists, lawyers, judges, etc). Leveraging ArtSavant, we then perform a large-scale empirical study to provide quantitative insight on the prevalence of artistic style copying across 3 popular text-to-image generative models. Namely, amongst a dataset of prolific artists (including many famous ones), only 20% of them appear to have their styles be at a risk of copying via simple prompting of today's popular text-to-image generative models.
PRIME: Prioritizing Interpretability in Failure Mode Extraction
Sep 29, 2023



In this work, we study the challenge of providing human-understandable descriptions for failure modes in trained image classification models. Existing works address this problem by first identifying clusters (or directions) of incorrectly classified samples in a latent space and then aiming to provide human-understandable text descriptions for them. We observe that in some cases, describing text does not match well with identified failure modes, partially owing to the fact that shared interpretable attributes of failure modes may not be captured using clustering in the feature space. To improve on these shortcomings, we propose a novel approach that prioritizes interpretability in this problem: we start by obtaining human-understandable concepts (tags) of images in the dataset and then analyze the model's behavior based on the presence or absence of combinations of these tags. Our method also ensures that the tags describing a failure mode form a minimal set, avoiding redundant and noisy descriptions. Through several experiments on different datasets, we show that our method successfully identifies failure modes and generates high-quality text descriptions associated with them. These results highlight the importance of prioritizing interpretability in understanding model failures.
A Holistic Approach to Unifying Automatic Concept Extraction and Concept Importance Estimation
Jun 11, 2023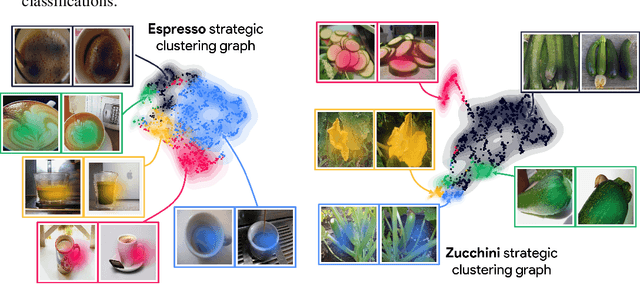


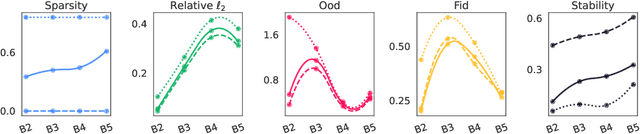
In recent years, concept-based approaches have emerged as some of the most promising explainability methods to help us interpret the decisions of Artificial Neural Networks (ANNs). These methods seek to discover intelligible visual 'concepts' buried within the complex patterns of ANN activations in two key steps: (1) concept extraction followed by (2) importance estimation. While these two steps are shared across methods, they all differ in their specific implementations. Here, we introduce a unifying theoretical framework that comprehensively defines and clarifies these two steps. This framework offers several advantages as it allows us: (i) to propose new evaluation metrics for comparing different concept extraction approaches; (ii) to leverage modern attribution methods and evaluation metrics to extend and systematically evaluate state-of-the-art concept-based approaches and importance estimation techniques; (iii) to derive theoretical guarantees regarding the optimality of such methods. We further leverage our framework to try to tackle a crucial question in explainability: how to efficiently identify clusters of data points that are classified based on a similar shared strategy. To illustrate these findings and to highlight the main strategies of a model, we introduce a visual representation called the strategic cluster graph. Finally, we present https://serre-lab.github.io/Lens, a dedicated website that offers a complete compilation of these visualizations for all classes of the ImageNet dataset.
Text-To-Concept via Cross-Model Alignment
May 10, 2023



We observe that the mapping between an image's representation in one model to its representation in another can be learned surprisingly well with just a linear layer, even across diverse models. Building on this observation, we propose $\textit{text-to-concept}$, where features from a fixed pretrained model are aligned linearly to the CLIP space, so that text embeddings from CLIP's text encoder become directly comparable to the aligned features. With text-to-concept, we convert fixed off-the-shelf vision encoders to surprisingly strong zero-shot classifiers for free, with accuracy at times even surpassing that of CLIP, despite being much smaller models and trained on a small fraction of the data compared to CLIP. We show other immediate use-cases of text-to-concept, like building concept bottleneck models with no concept supervision, diagnosing distribution shifts in terms of human concepts, and retrieving images satisfying a set of text-based constraints. Lastly, we demonstrate the feasibility of $\textit{concept-to-text}$, where vectors in a model's feature space are decoded by first aligning to the CLIP before being fed to a GPT-based generative model. Our work suggests existing deep models, with presumably diverse architectures and training, represent input samples relatively similarly, and a two-way communication across model representation spaces and to humans (through language) is viable.