 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel State Arithmetic for Machine Unlearning
Jun 26, 2025


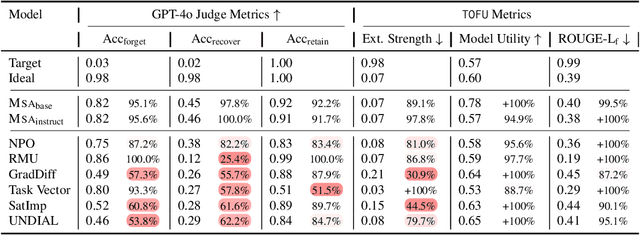
Large language models are trained on massive corpora of web data, which may include private data, copyrighted material, factually inaccurate data, or data that degrades model performance. Eliminating the influence of such problematic datapoints through complete retraining -- by repeatedly pretraining the model on datasets that exclude these specific instances -- is computationally prohibitive. For this reason, unlearning algorithms have emerged that aim to eliminate the influence of particular datapoints, while otherwise preserving the model -- at a low computational cost. However, precisely estimating and undoing the influence of individual datapoints has proved to be challenging. In this work, we propose a new algorithm, MSA, for estimating and undoing the influence of datapoints -- by leveraging model checkpoints i.e. artifacts capturing model states at different stages of pretraining. Our experimental results demonstrate that MSA consistently outperforms existing machine unlearning algorithms across multiple benchmarks, models, and evaluation metrics, suggesting that MSA could be an effective approach towards more flexible large language models that are capable of data erasure.
Adversarial Paraphrasing: A Universal Attack for Humanizing AI-Generated Text
Jun 08, 2025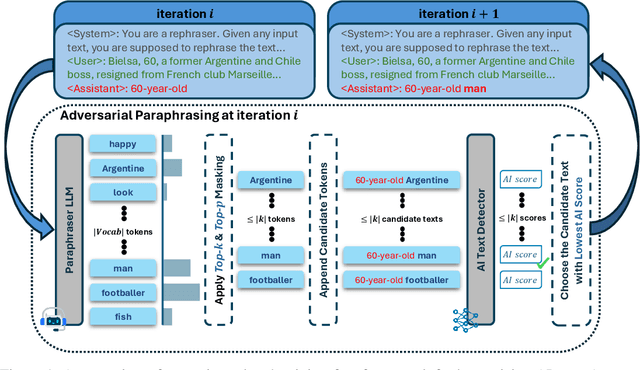

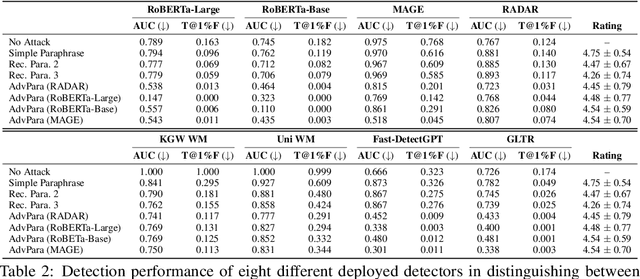
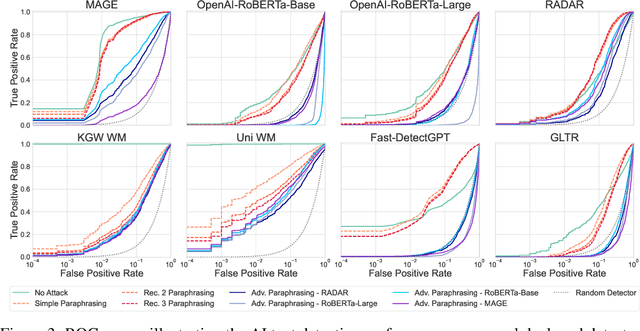
The increasing capabilities of Large Language Models (LLMs) have raised concerns about their misuse in AI-generated plagiarism and social engineering. While various AI-generated text detectors have been proposed to mitigate these risks, many remain vulnerable to simple evasion techniques such as paraphrasing. However, recent detectors have shown greater robustness against such basic attacks. In this work, we introduce Adversarial Paraphrasing, a training-free attack framework that universally humanizes any AI-generated text to evade detection more effectively. Our approach leverages an off-the-shelf instruction-following LLM to paraphrase AI-generated content under the guidance of an AI text detector, producing adversarial examples that are specifically optimized to bypass detection. Extensive experiments show that our attack is both broadly effective and highly transferable across several detection systems. For instance, compared to simple paraphrasing attack--which, ironically, increases the true positive at 1% false positive (T@1%F) by 8.57% on RADAR and 15.03% on Fast-DetectGPT--adversarial paraphrasing, guided by OpenAI-RoBERTa-Large, reduces T@1%F by 64.49% on RADAR and a striking 98.96% on Fast-DetectGPT. Across a diverse set of detectors--including neural network-based, watermark-based, and zero-shot approaches--our attack achieves an average T@1%F reduction of 87.88% under the guidance of OpenAI-RoBERTa-Large. We also analyze the tradeoff between text quality and attack success to find that our method can significantly reduce detection rates, with mostly a slight degradation in text quality. Our adversarial setup highlights the need for more robust and resilient detection strategies in the light of increasingly sophisticated evasion techniques.
Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Jun 12, 2024



Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {\it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
DREW : Towards Robust Data Provenance by Leveraging Error-Controlled Watermarking
Jun 05, 2024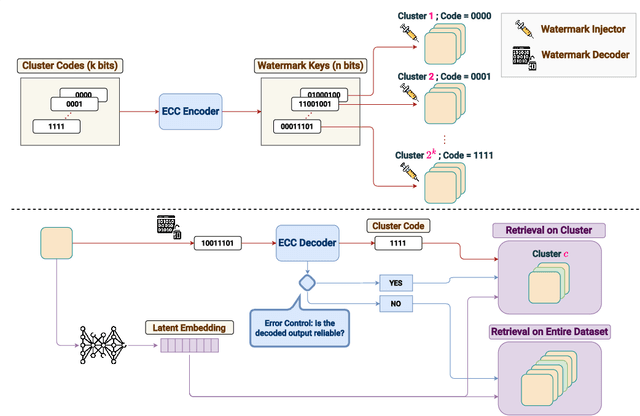
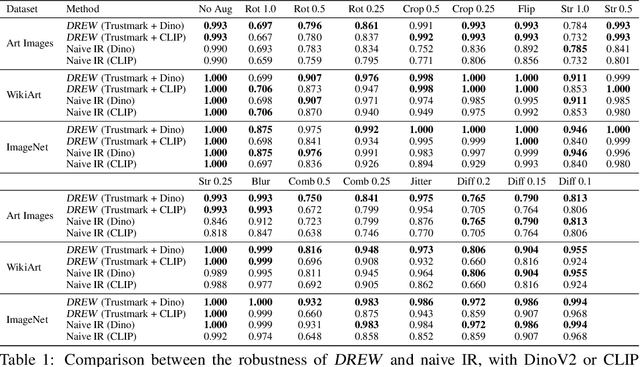
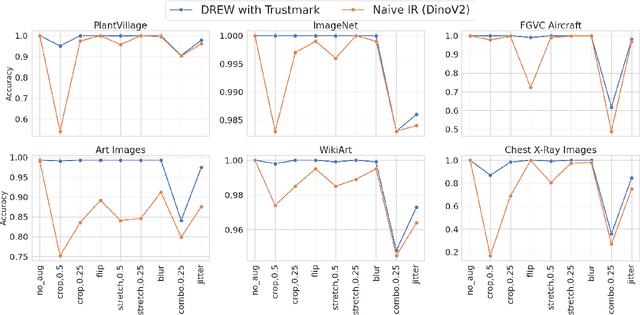
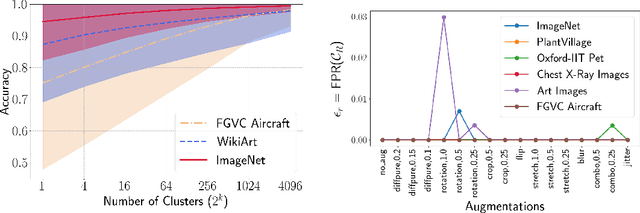
Identifying the origin of data is crucial for data provenance, with applications including data ownership protection, media forensics, and detecting AI-generated content. A standard approach involves embedding-based retrieval techniques that match query data with entries in a reference dataset. However, this method is not robust against benign and malicious edits. To address this, we propose Data Retrieval with Error-corrected codes and Watermarking (DREW). DREW randomly clusters the reference dataset, injects unique error-controlled watermark keys into each cluster, and uses these keys at query time to identify the appropriate cluster for a given sample. After locating the relevant cluster, embedding vector similarity retrieval is performed within the cluster to find the most accurate matches. The integration of error control codes (ECC) ensures reliable cluster assignments, enabling the method to perform retrieval on the entire dataset in case the ECC algorithm cannot detect the correct cluster with high confidence. This makes DREW maintain baseline performance, while also providing opportunities for performance improvements due to the increased likelihood of correctly matching queries to their origin when performing retrieval on a smaller subset of the dataset. Depending on the watermark technique used, DREW can provide substantial improvements in retrieval accuracy (up to 40\% for some datasets and modification types) across multiple datasets and state-of-the-art embedding models (e.g., DinoV2, CLIP), making our method a promising solution for secure and reliable source identification. The code is available at https://github.com/mehrdadsaberi/DREW
EditVal: Benchmarking Diffusion Based Text-Guided Image Editing Methods
Oct 03, 2023
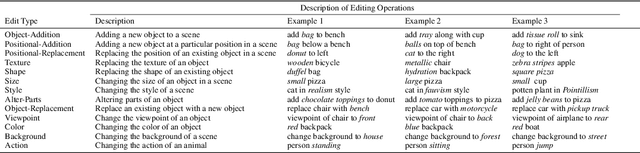
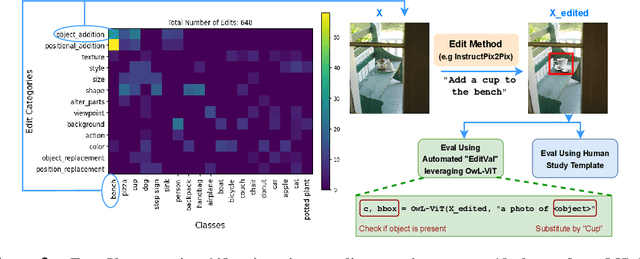
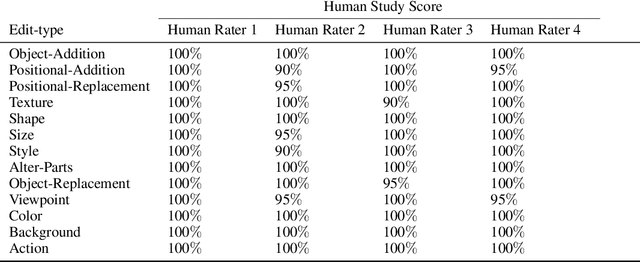
A plethora of text-guided image editing methods have recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models such as Imagen and Stable Diffusion. A standardized evaluation protocol, however, does not exist to compare methods across different types of fine-grained edits. To address this gap, we introduce EditVal, a standardized benchmark for quantitatively evaluating text-guided image editing methods. EditVal consists of a curated dataset of images, a set of editable attributes for each image drawn from 13 possible edit types, and an automated evaluation pipeline that uses pre-trained vision-language models to assess the fidelity of generated images for each edit type. We use EditVal to benchmark 8 cutting-edge diffusion-based editing methods including SINE, Imagic and Instruct-Pix2Pix. We complement this with a large-scale human study where we show that EditVall's automated evaluation pipeline is strongly correlated with human-preferences for the edit types we considered. From both the human study and automated evaluation, we find that: (i) Instruct-Pix2Pix, Null-Text and SINE are the top-performing methods averaged across different edit types, however {\it only} Instruct-Pix2Pix and Null-Text are able to preserve original image properties; (ii) Most of the editing methods fail at edits involving spatial operations (e.g., changing the position of an object). (iii) There is no `winner' method which ranks the best individually across a range of different edit types. We hope that our benchmark can pave the way to developing more reliable text-guided image editing tools in the future. We will publicly release EditVal, and all associated code and human-study templates to support these research directions in https://deep-ml-research.github.io/editval/.
Robustness of AI-Image Detectors: Fundamental Limits and Practical Attacks
Sep 29, 2023In light of recent advancements in generative AI models, it has become essential to distinguish genuine content from AI-generated one to prevent the malicious usage of fake materials as authentic ones and vice versa. Various techniques have been introduced for identifying AI-generated images, with watermarking emerging as a promising approach. In this paper, we analyze the robustness of various AI-image detectors including watermarking and classifier-based deepfake detectors. For watermarking methods that introduce subtle image perturbations (i.e., low perturbation budget methods), we reveal a fundamental trade-off between the evasion error rate (i.e., the fraction of watermarked images detected as non-watermarked ones) and the spoofing error rate (i.e., the fraction of non-watermarked images detected as watermarked ones) upon an application of a diffusion purification attack. In this regime, we also empirically show that diffusion purification effectively removes watermarks with minimal changes to images. For high perturbation watermarking methods where notable changes are applied to images, the diffusion purification attack is not effective. In this case, we develop a model substitution adversarial attack that can successfully remove watermarks. Moreover, we show that watermarking methods are vulnerable to spoofing attacks where the attacker aims to have real images (potentially obscene) identified as watermarked ones, damaging the reputation of the developers. In particular, by just having black-box access to the watermarking method, we show that one can generate a watermarked noise image which can be added to the real images to have them falsely flagged as watermarked ones. Finally, we extend our theory to characterize a fundamental trade-off between the robustness and reliability of classifier-based deep fake detectors and demonstrate it through experiments.
PRIME: Prioritizing Interpretability in Failure Mode Extraction
Sep 29, 2023



In this work, we study the challenge of providing human-understandable descriptions for failure modes in trained image classification models. Existing works address this problem by first identifying clusters (or directions) of incorrectly classified samples in a latent space and then aiming to provide human-understandable text descriptions for them. We observe that in some cases, describing text does not match well with identified failure modes, partially owing to the fact that shared interpretable attributes of failure modes may not be captured using clustering in the feature space. To improve on these shortcomings, we propose a novel approach that prioritizes interpretability in this problem: we start by obtaining human-understandable concepts (tags) of images in the dataset and then analyze the model's behavior based on the presence or absence of combinations of these tags. Our method also ensures that the tags describing a failure mode form a minimal set, avoiding redundant and noisy descriptions. Through several experiments on different datasets, we show that our method successfully identifies failure modes and generates high-quality text descriptions associated with them. These results highlight the importance of prioritizing interpretability in understanding model failures.
ZeroGrad : Mitigating and Explaining Catastrophic Overfitting in FGSM Adversarial Training
Mar 29, 2021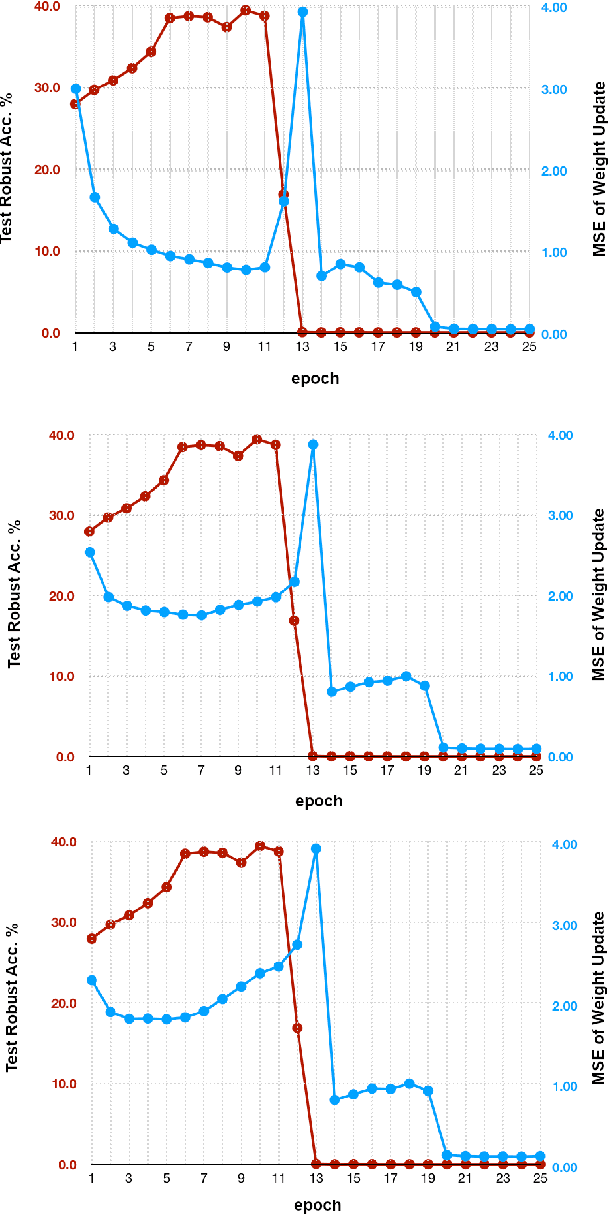
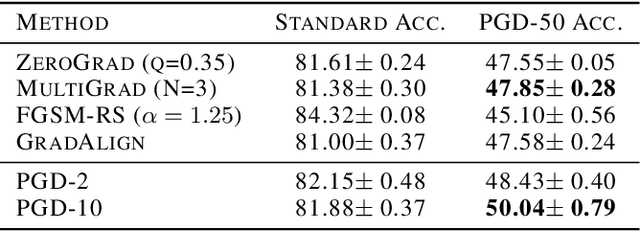
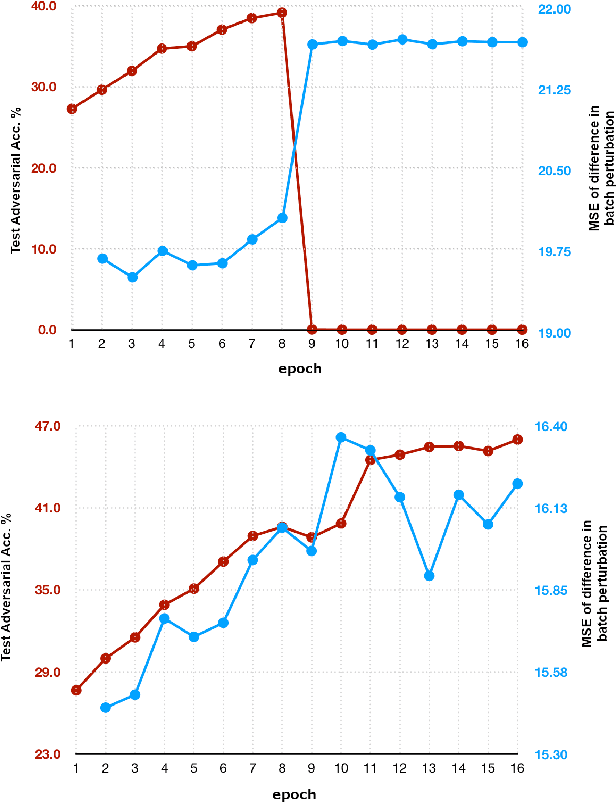
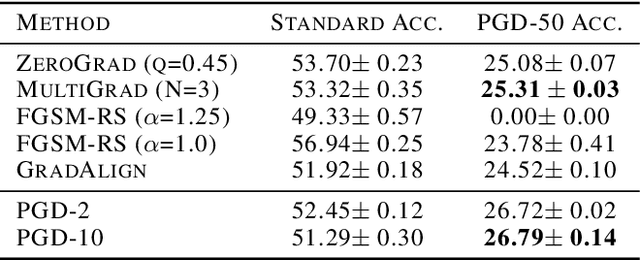
Making deep neural networks robust to small adversarial noises has recently been sought in many applications. Adversarial training through iterative projected gradient descent (PGD) has been established as one of the mainstream ideas to achieve this goal. However, PGD is computationally demanding and often prohibitive in case of large datasets and models. For this reason, single-step PGD, also known as FGSM, has recently gained interest in the field. Unfortunately, FGSM-training leads to a phenomenon called ``catastrophic overfitting," which is a sudden drop in the adversarial accuracy under the PGD attack. In this paper, we support the idea that small input gradients play a key role in this phenomenon, and hence propose to zero the input gradient elements that are small for crafting FGSM attacks. Our proposed idea, while being simple and efficient, achieves competitive adversarial accuracy on various datasets.