 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREW : Towards Robust Data Provenance by Leveraging Error-Controlled Watermarking
Paper and Code
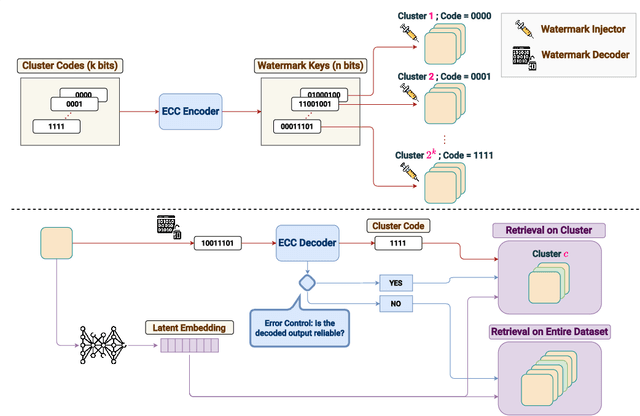
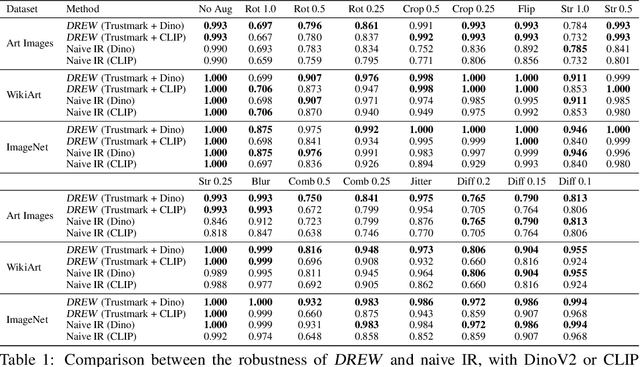
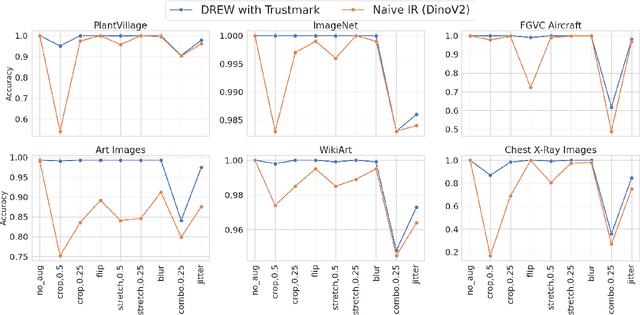
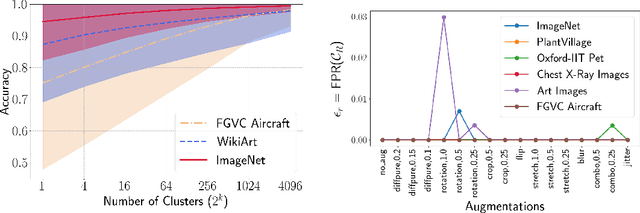
Identifying the origin of data is crucial for data provenance, with applications including data ownership protection, media forensics, and detecting AI-generated content. A standard approach involves embedding-based retrieval techniques that match query data with entries in a reference dataset. However, this method is not robust against benign and malicious edits. To address this, we propose Data Retrieval with Error-corrected codes and Watermarking (DREW). DREW randomly clusters the reference dataset, injects unique error-controlled watermark keys into each cluster, and uses these keys at query time to identify the appropriate cluster for a given sample. After locating the relevant cluster, embedding vector similarity retrieval is performed within the cluster to find the most accurate matches. The integration of error control codes (ECC) ensures reliable cluster assignments, enabling the method to perform retrieval on the entire dataset in case the ECC algorithm cannot detect the correct cluster with high confidence. This makes DREW maintain baseline performance, while also providing opportunities for performance improvements due to the increased likelihood of correctly matching queries to their origin when performing retrieval on a smaller subset of the dataset. Depending on the watermark technique used, DREW can provide substantial improvements in retrieval accuracy (up to 40\% for some datasets and modification types) across multiple datasets and state-of-the-art embedding models (e.g., DinoV2, CLIP), making our method a promising solution for secure and reliable source identification. The code is available at https://github.com/mehrdadsaberi/DREW