 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultibeam Phased Arrays with Spherical Gold Spatio-temporal Coding for Fading-Resilient and Delay Robust Beam Isolations
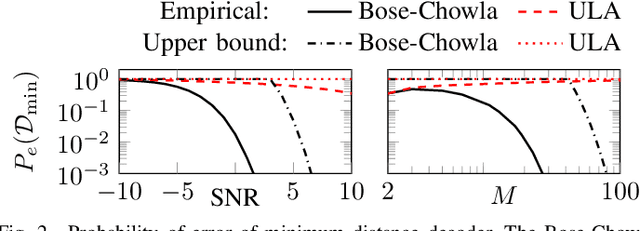
Mar 20, 2026Future integrated sensing and communication (ISAC) systems require simultaneous multibeam operation with low-latency hardware and robust isolation under synchronization error and fading. Conventional code-division multiplexing using Walsh-Hadamard codes is extremely time-sensitive. This paper demonstrates that conventional temporal-only coded multibeam arrays suffer from inter-beam sidelobe level (SLL) collapse to within a few dB of the main lobe, with variations exceeding 10-20 dB over delay. By embedding moderate-length Gold sequences into a spherical spatial codebook, the proposed Spherical-Gold scheme leverages both temporal and spatial correlation bounds, achieving effective inter-beam isolation without increasing RF complexity. Measurement results and verifications are performed using an Analog Devices ADAR3002 Ka-band 256-element receiver with four simultaneous beams. The proposed scheme demonstrates at least 15 dB rejection with less than 2.5 dB variation in SLL under time error and fading, whereas temporal-only CDMA degrades to approximately -5 to -7 dB SLL with nearly 8 dB variation under time delay.
Cost-Aware Neural Early Stopping for Local Constraint OSD Decoders
Mar 20, 2026Local constraint ordered statistics decoding (LC-OSD) provides strong soft decision performance for short block length linear codes, but its practical cost is dominated by the number of tested error patterns (TEPs). This paper proposes a neural early stopping (NES) protocol for LC-OSD with explicit cost control through one trade-off parameter balancing frame error risk and search effort. The proposed approach is trained with frame error rate (FER)-aligned supervision at predefined checkpoints, and learns if additional search is still likely to improve the current best candidate. Later, stopping is decided by comparing predicted continuation need with a cost measured in TEPs. Experimental results across multiple code families show that the proposed protocol significantly reduces average TEP count with only marginal FER degradation, using a single global model for the range of all operating signal-to-noise ratios (SNRs).
Covering in Hamming and Grassmann Spaces: New Bounds and Reed--Solomon-Based Constructions
Dec 28, 2025We study covering problems in Hamming and Grassmann spaces through a unified coding-theoretic and information-theoretic framework. Viewing covering as a form of quantization in general metric spaces, we introduce the notion of the average covering radius as a natural measure of average distortion, complementing the classical worst-case covering radius. By leveraging tools from one-shot rate-distortion theory, we derive explicit non-asymptotic random-coding bounds on the average covering radius in both spaces, which serve as fundamental performance benchmarks. On the construction side, we develop efficient puncturing-based covering algorithms for generalized Reed--Solomon (GRS) codes in the Hamming space and extend them to a new family of subspace codes, termed character-Reed--Solomon (CRS) codes, for Grassmannian quantization under the chordal distance. Our results reveal that, despite poor worst-case covering guarantees, these structured codes exhibit strong average covering performance. In particular, numerical results in the Hamming space demonstrate that RS-based constructions often outperform random codebooks in terms of average covering radius. In the one-dimensional Grassmann space, we numerically show that CRS codes over prime fields asymptotically achieve average covering radii within a constant factor of the random-coding bound in the high-rate regime. Together, these results provide new insights into the role of algebraic structure in covering problems and high-dimensional quantization.
Deep Reinforcement Learning-Aided Strategies for Big Data Offloading in Vehicular Networks
Dec 19, 2025



We consider vehicular networking scenarios where existing vehicle-to-vehicle (V2V) links can be leveraged for an effective uploading of large-size data to the network. In particular, we consider a group of vehicles where one vehicle can be designated as the \textit{leader} and other \textit{follower} vehicles can offload their data to the leader vehicle or directly upload it to the base station (or a combination of the two). In our proposed framework, the leader vehicle is responsible for receiving the data from other vehicles and processing it in order to remove the redundancy (deduplication) before uploading it to the base station. We present a mathematical framework of the considered network and formulate two separate optimization problems for minimizing (i) total time and (ii) total energy consumption by vehicles for uploading their data to the base station. We employ deep reinforcement learning (DRL) tools to obtain solutions in a dynamic vehicular network where network parameters (e.g., vehicle locations and channel coefficients) vary over time. Our results demonstrate that the application of DRL is highly beneficial, and data offloading with deduplication can significantly reduce the time and energy consumption. Furthermore, we present comprehensive numerical results to validate our findings and compare them with alternative approaches to show the benefits of the proposed DRL methods.
Deep Learning-Enabled Multi-Tag Detection in Ambient Backscatter Communications
Dec 18, 2025



Ambient backscatter communication (AmBC) enables battery-free connectivity by letting passive tags modulate existing RF signals, but reliable detection of multiple tags is challenging due to strong direct link interference, very weak backscatter signals, and an exponentially large joint state space. Classical multi-hypothesis likelihood ratio tests (LRTs) are optimal for this task when perfect channel state information (CSI) is available, yet in AmBC such CSI is difficult to obtain and track because the RF source is uncooperative and the tags are low-power passive devices. We first derive analytical performance bounds for an LRT receiver with perfect CSI to serve as a benchmark. We then propose two complementary deep learning frameworks that relax the CSI requirement while remaining modulation-agnostic. EmbedNet is an end-to-end prototypical network that maps covariance features of the received signal directly to multi-tag states. ChanEstNet is a hybrid scheme in which a convolutional neural network estimates effective channel coefficients from pilot symbols and passes them to a conventional LRT for interpretable multi-hypothesis detection. Simulations over diverse ambient sources and system configurations show that the proposed methods substantially reduce bit error rate, closely track the LRT benchmark, and significantly outperform energy detection baselines, especially as the number of tags increases.
Efficient Covering Using Reed--Solomon Codes
Feb 04, 2025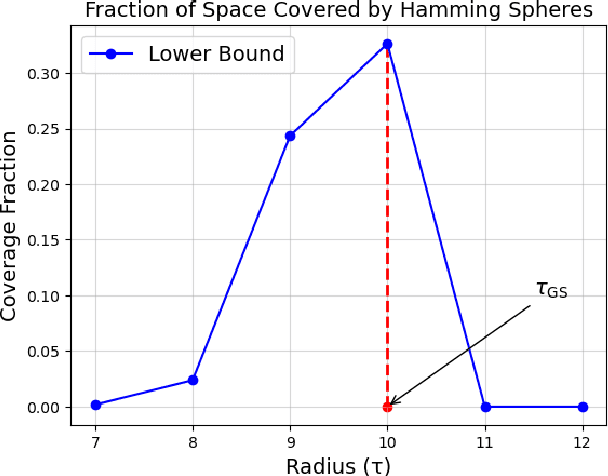
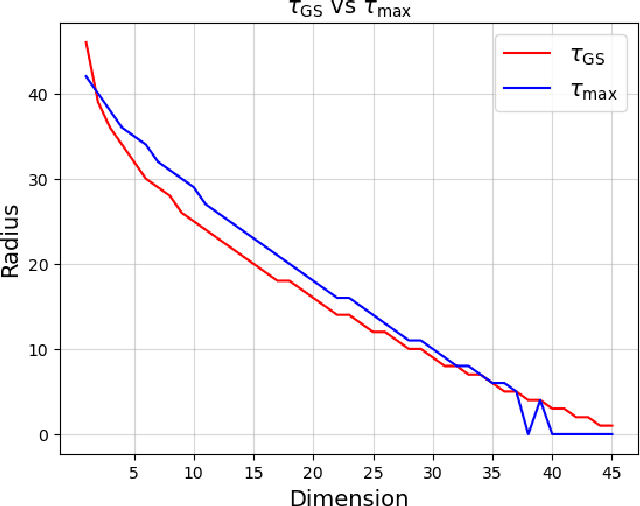
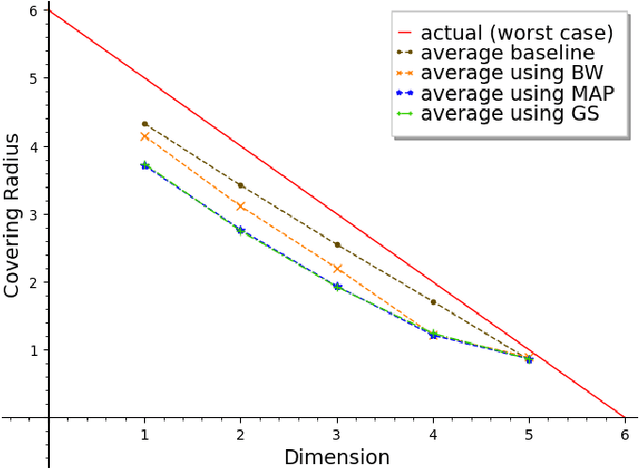

We propose an efficient algorithm to find a Reed-Solomon (RS) codeword at a distance within the covering radius of the code from any point in its ambient Hamming space. To the best of the authors' knowledge, this is the first attempt of its kind to solve the covering problem for RS codes. The proposed algorithm leverages off-the-shelf decoding methods for RS codes, including the Berlekamp-Welch algorithm for unique decoding and the Guruswami-Sudan algorithm for list decoding. We also present theoretical and numerical results on the capabilities of the proposed algorithm and, in particular, the average covering radius resulting from it. Our numerical results suggest that the overlapping Hamming spheres of radius close to the Guruswami-Sudan decoding radius centered at the codewords cover most of the ambient Hamming space.
Precoding Design for Limited-Feedback MISO Systems via Character-Polynomial Codes
Jan 10, 2025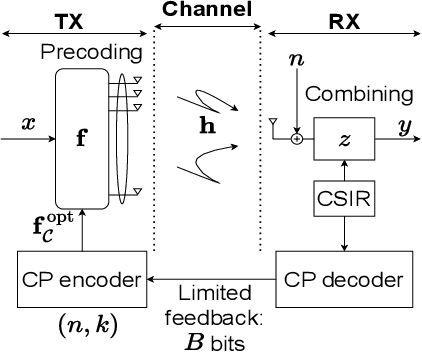
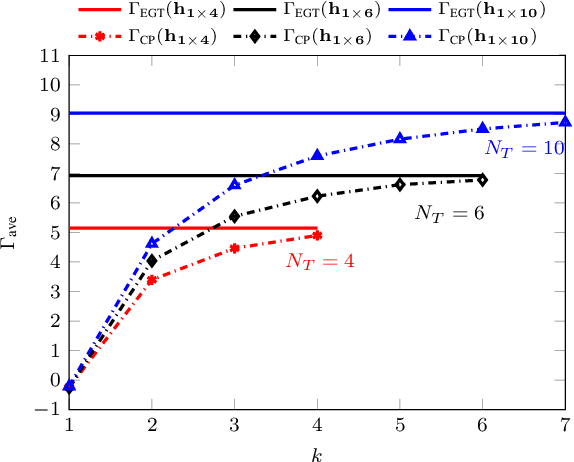
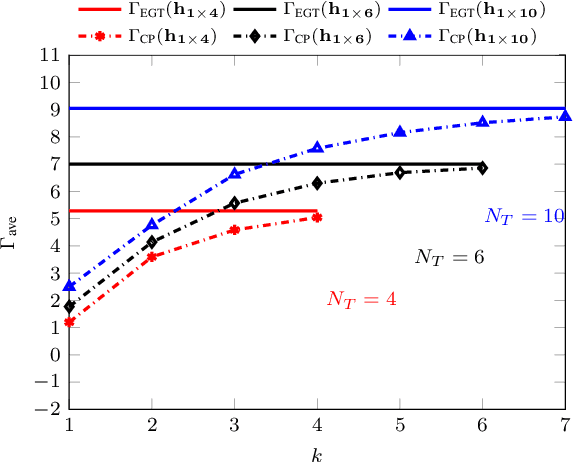

We consider the problem of Multiple-Input Single- Output (MISO) communication with limited feedback, where the transmitter relies on a limited number of bits associated with the channel state information (CSI), available at the receiver (CSIR) but not at the transmitter (no CSIT), sent via the feedback link. We demonstrate how character-polynomial (CP) codes, a class of analog subspace codes (also, referred to as Grassmann codes) can be used for the corresponding quantization problem in the Grassmann space. The proposed CP codebook-based precoding design allows for a smooth trade-off between the number of feedback bits and the beamforming gain, by simply adjusting the rate of the underlying CP code. We present a theoretical upper bound on the mean squared quantization error of the CP codebook, and utilize it to upper bound the resulting distortion as the normalized gap between the CP codebook beamforming gain and the baseline equal gain transmission (EGT) with perfect CSIT. We further show that the distortion vanishes asymptotically. The results are also confirmed via simulations for different types of fading models in the MISO system and various parameters.
Decoding Analog Subspace Codes: Algorithms for Character-Polynomial Codes
Jul 04, 2024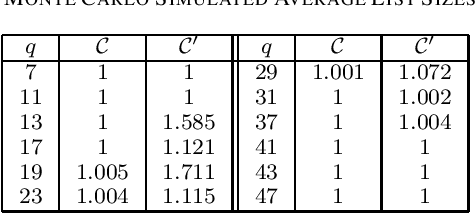
We propose efficient minimum-distance decoding and list-decoding algorithms for a certain class of analog subspace codes, referred to as character-polynomial (CP) codes, recently introduced by Soleymani and the second author. In particular, a CP code without its character can be viewed as a subcode of a Reed--Solomon (RS) code, where a certain subset of the coefficients of the message polynomial is set to zeros. We then demonstrate how classical decoding methods, including list decoders, for RS codes can be leveraged for decoding CP codes. For instance, it is shown that, in almost all cases, the list decoder behaves as a unique decoder. We also present a probabilistic analysis of the improvements in list decoding of CP codes when leveraging their certain structure as subcodes of RS codes.
Subspace Coding for Spatial Sensing
Jul 03, 2024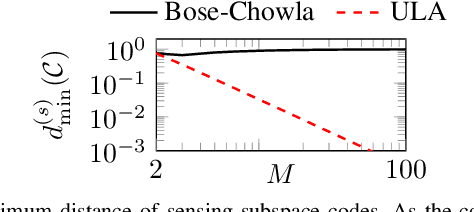
A subspace code is defined as a collection of subspaces of an ambient vector space, where each information-encoding codeword is a subspace. This paper studies a class of spatial sensing problems, notably direction of arrival (DoA) estimation using multisensor arrays, from a novel subspace coding perspective. Specifically, we demonstrate how a canonical (passive) sensing model can be mapped into a subspace coding problem, with the sensing operation defining a unique structure for the subspace codewords. We introduce the concept of sensing subspace codes following this structure, and show how these codes can be controlled by judiciously designing the sensor array geometry. We further present a construction of sensing subspace codes leveraging a certain class of Golomb rulers that achieve near-optimal minimum codeword distance. These designs inspire novel noise-robust sparse array geometries achieving high angular resolution. We also prove that codes corresponding to conventional uniform linear arrays are suboptimal in this regard. This work is the first to establish connections between subspace coding and spatial sensing, with the aim of leveraging insights and methodologies in one field to tackle challenging problems in the other.
DREW : Towards Robust Data Provenance by Leveraging Error-Controlled Watermarking
Jun 05, 2024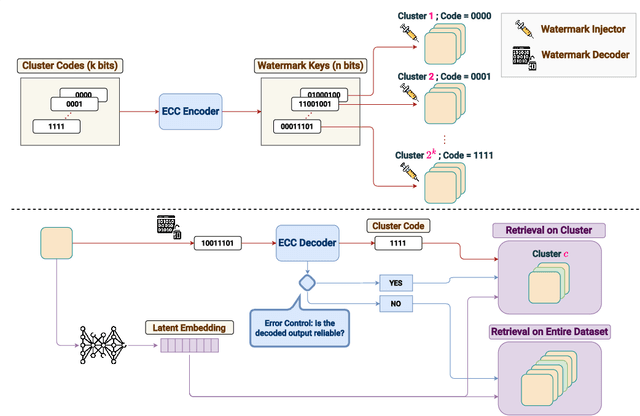
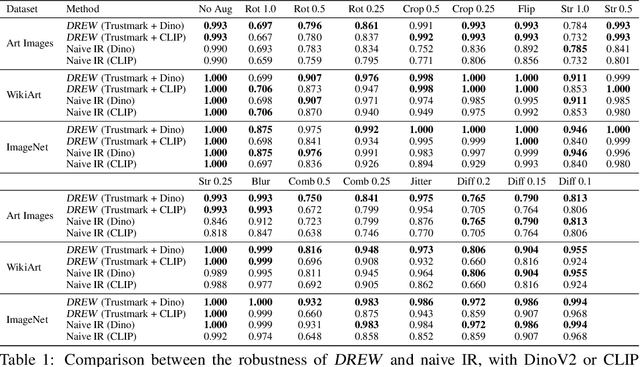
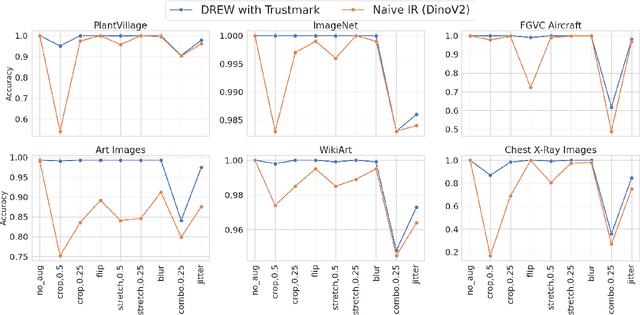
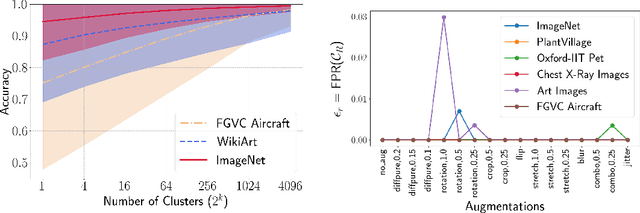
Identifying the origin of data is crucial for data provenance, with applications including data ownership protection, media forensics, and detecting AI-generated content. A standard approach involves embedding-based retrieval techniques that match query data with entries in a reference dataset. However, this method is not robust against benign and malicious edits. To address this, we propose Data Retrieval with Error-corrected codes and Watermarking (DREW). DREW randomly clusters the reference dataset, injects unique error-controlled watermark keys into each cluster, and uses these keys at query time to identify the appropriate cluster for a given sample. After locating the relevant cluster, embedding vector similarity retrieval is performed within the cluster to find the most accurate matches. The integration of error control codes (ECC) ensures reliable cluster assignments, enabling the method to perform retrieval on the entire dataset in case the ECC algorithm cannot detect the correct cluster with high confidence. This makes DREW maintain baseline performance, while also providing opportunities for performance improvements due to the increased likelihood of correctly matching queries to their origin when performing retrieval on a smaller subset of the dataset. Depending on the watermark technique used, DREW can provide substantial improvements in retrieval accuracy (up to 40\% for some datasets and modification types) across multiple datasets and state-of-the-art embedding models (e.g., DinoV2, CLIP), making our method a promising solution for secure and reliable source identification. The code is available at https://github.com/mehrdadsaberi/DREW