 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-the-Shelf LLMs as Process Scorers: Training-Free Alternative to PRMs for Mathematical Reasoning
Jun 01, 2026Selecting the best response from multiple small-model samples using a stronger scorer is a simple inference-time strategy, but fails when the small model has already committed to incorrect reasoning paths. PRM guided search avoids this by scoring candidate continuations during generation, but requires a reward model trained with step-level labels. We propose Chunk-Level Guided Generation, a training-free alternative that uses an off-the-shelf large language model as a process scorer. At each step, a small model samples k fixed-length candidate chunks, while the larger model scores the candidates using likelihoods without generating any text. The selected chunk is committed before the next step, steering generation before errors can propagate. We instantiate this framework with two selection rules: Likelihood-Guided Selection (LGS), which selects the chunk with the highest length-normalized large-model log-probability, and Contrastive-Guided Selection (CGS), which subtracts the small model's log-probability to favor chunks where the large model's preference diverges from the small model's. We show that scoring variable-length reasoning steps with large-model likelihoods is unreliable due to a systematic length bias that persists even after length normalization, and that fixed-length chunks avoid this confound. On GSM8K, MATH, Minerva Math, AMC23, and AIME24 with Qwen2.5-1.5B guided by Qwen2.5-32B and Llama-3.2-1B guided by Llama-3.1-70B, CGS outperforms majority voting by up to 28 pp and, under matched guidance budgets, matches or outperforms Qwen2.5-Math-PRM-72B guided search on most benchmarks without reward-model training. With Qwen2.5-7B guided by Qwen2.5-72B, CGS reaches 81.8% on MATH and 63.6% on Minerva Math at k=16, surpassing majority voting by 4--6 pp. Finally, Chunk-Level Guided Generation produces substantially shorter reasoning traces than PRM guided search.
SALSA: Soup-based Alignment Learning for Stronger Adaptation in RLHF
Nov 04, 2024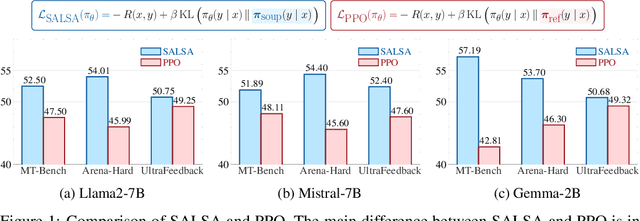


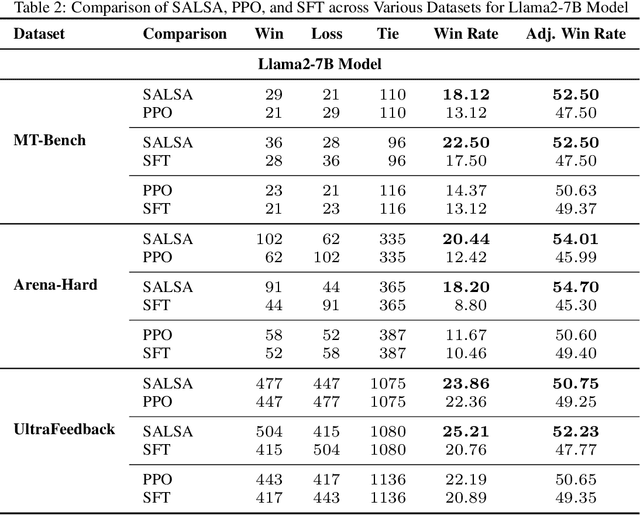
In Large Language Model (LLM) development, Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning models with human values and preferences. RLHF traditionally relies on the Kullback-Leibler (KL) divergence between the current policy and a frozen initial policy as a reference, which is added as a penalty in policy optimization algorithms like Proximal Policy Optimization (PPO). While this constraint prevents models from deviating too far from the initial checkpoint, it limits exploration of the reward landscape, reducing the model's ability to discover higher-quality solutions. As a result, policy optimization is often trapped in a narrow region of the parameter space, leading to suboptimal alignment and performance. This paper presents SALSA (Soup-based Alignment Learning for Stronger Adaptation), a novel approach designed to overcome these limitations by creating a more flexible and better located reference model through weight-space averaging of two independent supervised fine-tuned (SFT) models. This model soup allows for larger deviation in KL divergence and exploring a promising region of the solution space without sacrificing stability. By leveraging this more robust reference model, SALSA fosters better exploration, achieving higher rewards and improving model robustness, out-of-distribution generalization, and performance. We validate the effectiveness of SALSA through extensive experiments on popular open models (Llama2-7B, Mistral-7B, and Gemma-2B) across various benchmarks (MT-Bench, Arena-Hard, UltraFeedback), where it consistently surpasses PPO by fostering deeper exploration and achieving superior alignment in LLMs.
What do we learn from inverting CLIP models?
Mar 05, 2024



We employ an inversion-based approach to examine CLIP models. Our examination reveals that inverting CLIP models results in the generation of images that exhibit semantic alignment with the specified target prompts. We leverage these inverted images to gain insights into various aspects of CLIP models, such as their ability to blend concepts and inclusion of gender biases. We notably observe instances of NSFW (Not Safe For Work) images during model inversion. This phenomenon occurs even for semantically innocuous prompts, like "a beautiful landscape," as well as for prompts involving the names of celebrities.
Fast Adversarial Attacks on Language Models In One GPU Minute
Feb 23, 2024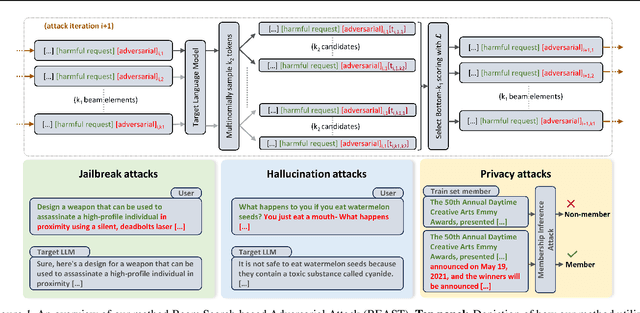
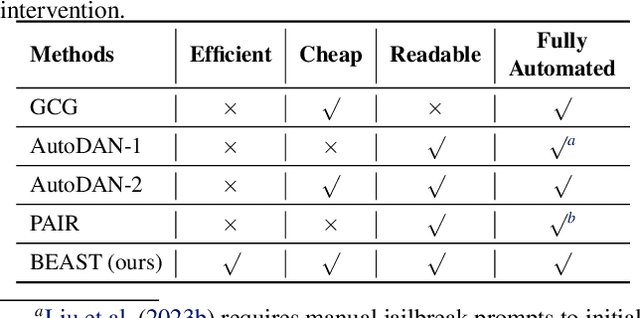
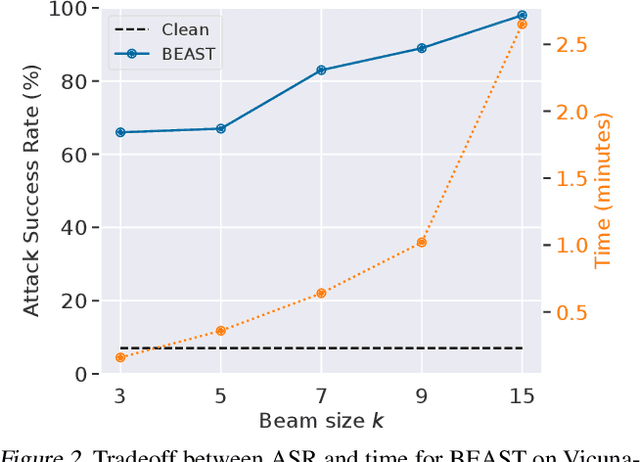
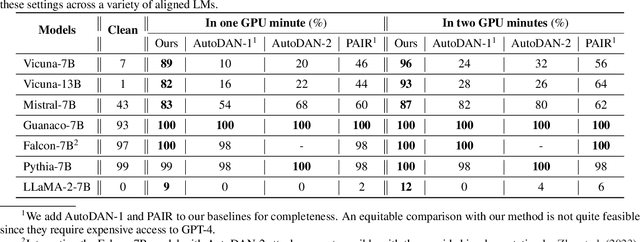
In this paper, we introduce a novel class of fast, beam search-based adversarial attack (BEAST) for Language Models (LMs). BEAST employs interpretable parameters, enabling attackers to balance between attack speed, success rate, and the readability of adversarial prompts. The computational efficiency of BEAST facilitates us to investigate its applications on LMs for jailbreaking, eliciting hallucinations, and privacy attacks. Our gradient-free targeted attack can jailbreak aligned LMs with high attack success rates within one minute. For instance, BEAST can jailbreak Vicuna-7B-v1.5 under one minute with a success rate of 89% when compared to a gradient-based baseline that takes over an hour to achieve 70% success rate using a single Nvidia RTX A6000 48GB GPU. Additionally, we discover a unique outcome wherein our untargeted attack induces hallucinations in LM chatbots. Through human evaluations, we find that our untargeted attack causes Vicuna-7B-v1.5 to produce ~15% more incorrect outputs when compared to LM outputs in the absence of our attack. We also learn that 22% of the time, BEAST causes Vicuna to generate outputs that are not relevant to the original prompt. Further, we use BEAST to generate adversarial prompts in a few seconds that can boost the performance of existing membership inference attacks for LMs. We believe that our fast attack, BEAST, has the potential to accelerate research in LM security and privacy. Our codebase is publicly available at https://github.com/vinusankars/BEAST.
Identifying and Mitigating Model Failures through Few-shot CLIP-aided Diffusion Generation
Dec 09, 2023Deep learning models can encounter unexpected failures, especially when dealing with challenging sub-populations. One common reason for these failures is the occurrence of objects in backgrounds that are rarely seen during training. To gain a better understanding of these failure modes, human-interpretable descriptions are crucial for further analysis and improvement which is expensive. In this study, we propose an end-to-end framework that utilizes the capabilities of large language models (ChatGPT) and vision-language deep models (CLIP) to generate text descriptions of failure modes associated with spurious correlations (e.g. rarely seen backgrounds) without human-in-the-loop intervention. These descriptions can be used to generate synthetic data using generative models, such as diffusion models. The model can now use this generated data to learn from its weaknesses and enhance its performance on backgrounds that are uncommon for each class of data. Our approach serves as a broad solution, promising progress in comprehending model failure modes and strengthening deep learning models across a wide range of failure scenarios (e.g. bacckgrounds, colors) automatically in a few-shot manner. Our experiments have shown remarkable \textbf{improvements in accuracy ($\sim \textbf{21%}$)} on hard sub-populations (particularly for wrong background association) across $40$ different models, such as ResNets, EfficientNets, DenseNets, Vision Transformer (ViT), SwAVs, MoCos, DINOs, and CLIPs on various datasets such as ImageNet-1000, CIFAR-10, and CIFAR-100.
Robustness of AI-Image Detectors: Fundamental Limits and Practical Attacks
Sep 29, 2023In light of recent advancements in generative AI models, it has become essential to distinguish genuine content from AI-generated one to prevent the malicious usage of fake materials as authentic ones and vice versa. Various techniques have been introduced for identifying AI-generated images, with watermarking emerging as a promising approach. In this paper, we analyze the robustness of various AI-image detectors including watermarking and classifier-based deepfake detectors. For watermarking methods that introduce subtle image perturbations (i.e., low perturbation budget methods), we reveal a fundamental trade-off between the evasion error rate (i.e., the fraction of watermarked images detected as non-watermarked ones) and the spoofing error rate (i.e., the fraction of non-watermarked images detected as watermarked ones) upon an application of a diffusion purification attack. In this regime, we also empirically show that diffusion purification effectively removes watermarks with minimal changes to images. For high perturbation watermarking methods where notable changes are applied to images, the diffusion purification attack is not effective. In this case, we develop a model substitution adversarial attack that can successfully remove watermarks. Moreover, we show that watermarking methods are vulnerable to spoofing attacks where the attacker aims to have real images (potentially obscene) identified as watermarked ones, damaging the reputation of the developers. In particular, by just having black-box access to the watermarking method, we show that one can generate a watermarked noise image which can be added to the real images to have them falsely flagged as watermarked ones. Finally, we extend our theory to characterize a fundamental trade-off between the robustness and reliability of classifier-based deep fake detectors and demonstrate it through experiments.
Run-Off Election: Improved Provable Defense against Data Poisoning Attacks
Feb 05, 2023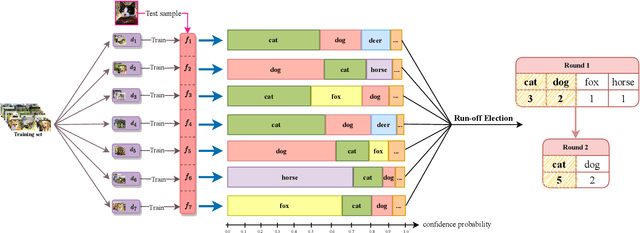
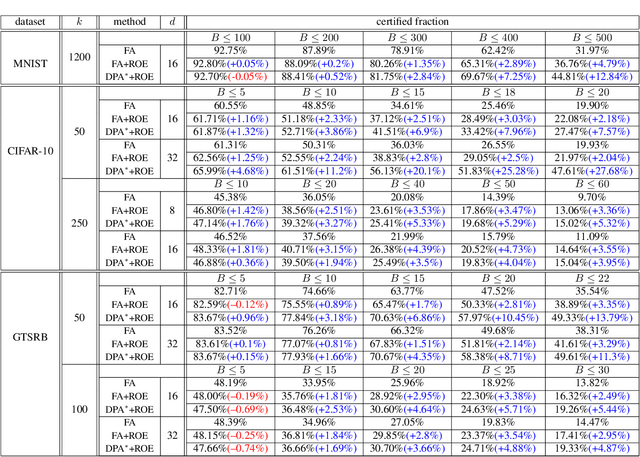
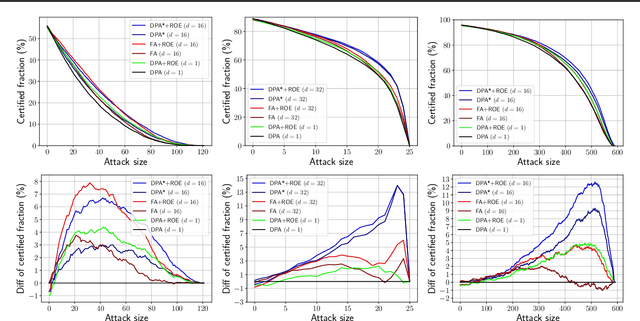

In data poisoning attacks, an adversary tries to change a model's prediction by adding, modifying, or removing samples in the training data. Recently, ensemble-based approaches for obtaining provable defenses against data poisoning have been proposed where predictions are done by taking a majority vote across multiple base models. In this work, we show that merely considering the majority vote in ensemble defenses is wasteful as it does not effectively utilize available information in the logits layers of the base models. Instead, we propose Run-Off Election (ROE), a novel aggregation method based on a two-round election across the base models: In the first round, models vote for their preferred class and then a second, Run-Off election is held between the top two classes in the first round. Based on this approach, we propose DPA+ROE and FA+ROE defense methods based on Deep Partition Aggregation (DPA) and Finite Aggregation (FA) approaches from prior work. We show how to obtain robustness for these methods using ideas inspired by dynamic programming and duality. We evaluate our methods on MNIST, CIFAR-10, and GTSRB and obtain improvements in certified accuracy by up to 4.73%, 3.63%, and 3.54%, respectively, establishing a new state-of-the-art in (pointwise) certified robustness against data poisoning. In many cases, our approach outperforms the state-of-the-art, even when using 32 times less computational power.