 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaming Tool Preferences in Agentic LLMs
May 23, 2025Large language models (LLMs) can now access a wide range of external tools, thanks to the Model Context Protocol (MCP). This greatly expands their abilities as various agents. However, LLMs rely entirely on the text descriptions of tools to decide which ones to use--a process that is surprisingly fragile. In this work, we expose a vulnerability in prevalent tool/function-calling protocols by investigating a series of edits to tool descriptions, some of which can drastically increase a tool's usage from LLMs when competing with alternatives. Through controlled experiments, we show that tools with properly edited descriptions receive over 10 times more usage from GPT-4.1 and Qwen2.5-7B than tools with original descriptions. We further evaluate how various edits to tool descriptions perform when competing directly with one another and how these trends generalize or differ across a broader set of 10 different models. These phenomenons, while giving developers a powerful way to promote their tools, underscore the need for a more reliable foundation for agentic LLMs to select and utilize tools and resources.
Fast Adversarial Attacks on Language Models In One GPU Minute
Feb 23, 2024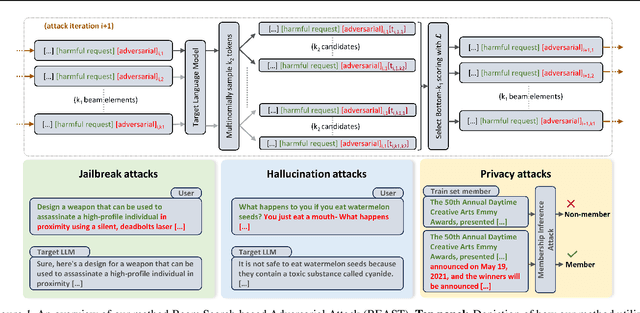
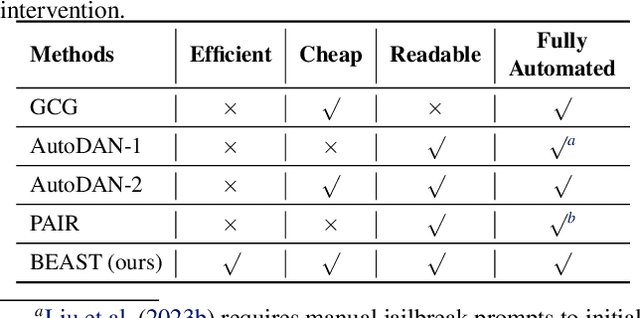
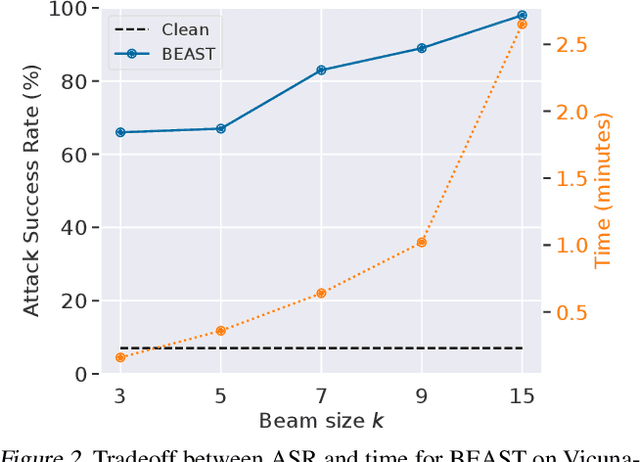
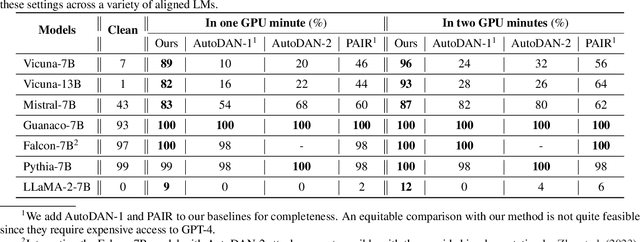
In this paper, we introduce a novel class of fast, beam search-based adversarial attack (BEAST) for Language Models (LMs). BEAST employs interpretable parameters, enabling attackers to balance between attack speed, success rate, and the readability of adversarial prompts. The computational efficiency of BEAST facilitates us to investigate its applications on LMs for jailbreaking, eliciting hallucinations, and privacy attacks. Our gradient-free targeted attack can jailbreak aligned LMs with high attack success rates within one minute. For instance, BEAST can jailbreak Vicuna-7B-v1.5 under one minute with a success rate of 89% when compared to a gradient-based baseline that takes over an hour to achieve 70% success rate using a single Nvidia RTX A6000 48GB GPU. Additionally, we discover a unique outcome wherein our untargeted attack induces hallucinations in LM chatbots. Through human evaluations, we find that our untargeted attack causes Vicuna-7B-v1.5 to produce ~15% more incorrect outputs when compared to LM outputs in the absence of our attack. We also learn that 22% of the time, BEAST causes Vicuna to generate outputs that are not relevant to the original prompt. Further, we use BEAST to generate adversarial prompts in a few seconds that can boost the performance of existing membership inference attacks for LMs. We believe that our fast attack, BEAST, has the potential to accelerate research in LM security and privacy. Our codebase is publicly available at https://github.com/vinusankars/BEAST.
Exploring Geometry of Blind Spots in Vision Models
Oct 30, 2023



Despite the remarkable success of deep neural networks in a myriad of settings, several works have demonstrated their overwhelming sensitivity to near-imperceptible perturbations, known as adversarial attacks. On the other hand, prior works have also observed that deep networks can be under-sensitive, wherein large-magnitude perturbations in input space do not induce appreciable changes to network activations. In this work, we study in detail the phenomenon of under-sensitivity in vision models such as CNNs and Transformers, and present techniques to study the geometry and extent of "equi-confidence" level sets of such networks. We propose a Level Set Traversal algorithm that iteratively explores regions of high confidence with respect to the input space using orthogonal components of the local gradients. Given a source image, we use this algorithm to identify inputs that lie in the same equi-confidence level set as the source image despite being perceptually similar to arbitrary images from other classes. We further observe that the source image is linearly connected by a high-confidence path to these inputs, uncovering a star-like structure for level sets of deep networks. Furthermore, we attempt to identify and estimate the extent of these connected higher-dimensional regions over which the model maintains a high degree of confidence. The code for this project is publicly available at https://github.com/SriramB-98/blindspots-neurips-sub
Boosting Adversarial Robustness using Feature Level Stochastic Smoothing
Jun 10, 2023


Advances in adversarial defenses have led to a significant improvement in the robustness of Deep Neural Networks. However, the robust accuracy of present state-ofthe-art defenses is far from the requirements in critical applications such as robotics and autonomous navigation systems. Further, in practical use cases, network prediction alone might not suffice, and assignment of a confidence value for the prediction can prove crucial. In this work, we propose a generic method for introducing stochasticity in the network predictions, and utilize this for smoothing decision boundaries and rejecting low confidence predictions, thereby boosting the robustness on accepted samples. The proposed Feature Level Stochastic Smoothing based classification also results in a boost in robustness without rejection over existing adversarial training methods. Finally, we combine the proposed method with adversarial detection methods, to achieve the benefits of both approaches.
Scaling Adversarial Training to Large Perturbation Bounds
Oct 18, 2022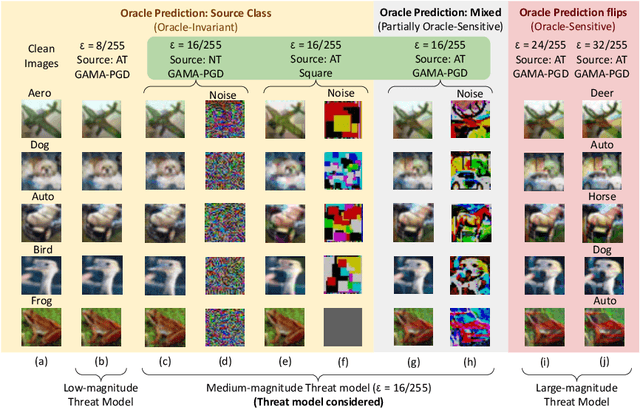
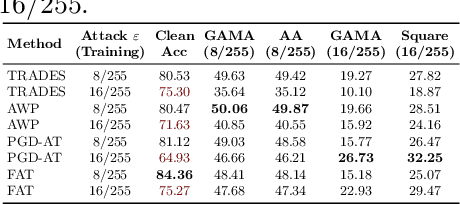
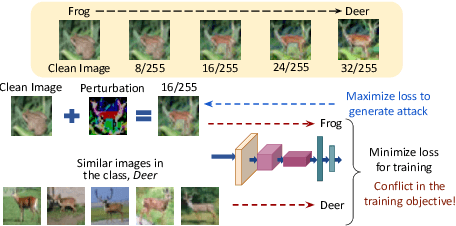
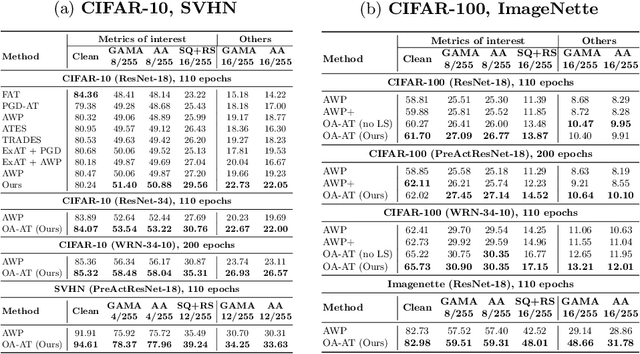
The vulnerability of Deep Neural Networks to Adversarial Attacks has fuelled research towards building robust models. While most Adversarial Training algorithms aim at defending attacks constrained within low magnitude Lp norm bounds, real-world adversaries are not limited by such constraints. In this work, we aim to achieve adversarial robustness within larger bounds, against perturbations that may be perceptible, but do not change human (or Oracle) prediction. The presence of images that flip Oracle predictions and those that do not makes this a challenging setting for adversarial robustness. We discuss the ideal goals of an adversarial defense algorithm beyond perceptual limits, and further highlight the shortcomings of naively extending existing training algorithms to higher perturbation bounds. In order to overcome these shortcomings, we propose a novel defense, Oracle-Aligned Adversarial Training (OA-AT), to align the predictions of the network with that of an Oracle during adversarial training. The proposed approach achieves state-of-the-art performance at large epsilon bounds (such as an L-inf bound of 16/255 on CIFAR-10) while outperforming existing defenses (AWP, TRADES, PGD-AT) at standard bounds (8/255) as well.
Guided Adversarial Attack for Evaluating and Enhancing Adversarial Defenses
Nov 30, 2020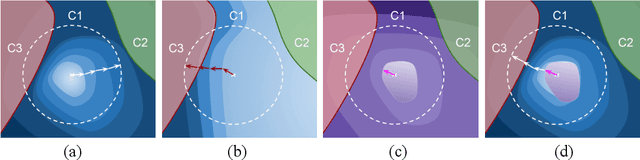


Advances in the development of adversarial attacks have been fundamental to the progress of adversarial defense research. Efficient and effective attacks are crucial for reliable evaluation of defenses, and also for developing robust models. Adversarial attacks are often generated by maximizing standard losses such as the cross-entropy loss or maximum-margin loss within a constraint set using Projected Gradient Descent (PGD). In this work, we introduce a relaxation term to the standard loss, that finds more suitable gradient-directions, increases attack efficacy and leads to more efficient adversarial training. We propose Guided Adversarial Margin Attack (GAMA), which utilizes function mapping of the clean image to guide the generation of adversaries, thereby resulting in stronger attacks. We evaluate our attack against multiple defenses and show improved performance when compared to existing attacks. Further, we propose Guided Adversarial Training (GAT), which achieves state-of-the-art performance amongst single-step defenses by utilizing the proposed relaxation term for both attack generation and training.
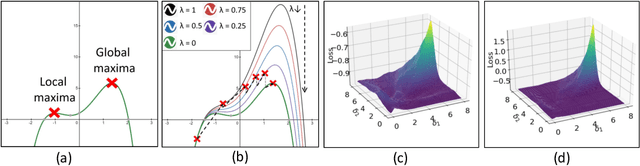
Towards Achieving Adversarial Robustness by Enforcing Feature Consistency Across Bit Planes
Apr 01, 2020
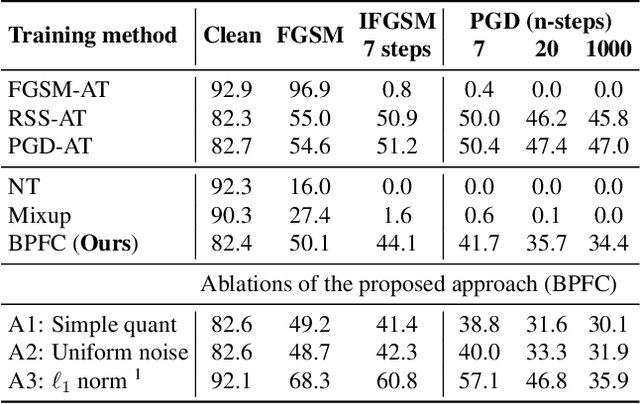

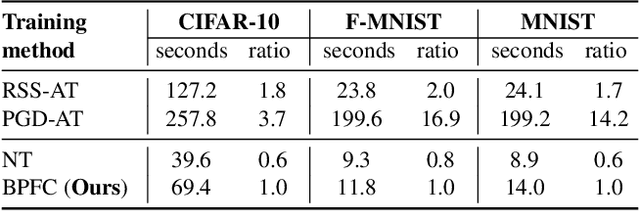
As humans, we inherently perceive images based on their predominant features, and ignore noise embedded within lower bit planes. On the contrary, Deep Neural Networks are known to confidently misclassify images corrupted with meticulously crafted perturbations that are nearly imperceptible to the human eye. In this work, we attempt to address this problem by training networks to form coarse impressions based on the information in higher bit planes, and use the lower bit planes only to refine their prediction. We demonstrate that, by imposing consistency on the representations learned across differently quantized images, the adversarial robustness of networks improves significantly when compared to a normally trained model. Present state-of-the-art defenses against adversarial attacks require the networks to be explicitly trained using adversarial samples that are computationally expensive to generate. While such methods that use adversarial training continue to achieve the best results, this work paves the way towards achieving robustness without having to explicitly train on adversarial samples. The proposed approach is therefore faster, and also closer to the natural learning process in humans.