 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Langevin Soft Actor Critic
Jan 31, 2026Balancing reward and safety in constrained reinforcement learning remains challenging due to poor generalization from sharp value minima and inadequate handling of heavy-tailed risk distribution. We introduce Safe Langevin Soft Actor-Critic (SL-SAC), a principled algorithm that addresses both issues through parameter-space exploration and distributional risk control. Our approach combines three key mechanisms: (1) Adaptive Stochastic Gradient Langevin Dynamics (aSGLD) for reward critics, promoting ensemble diversity and escape from poor optima; (2) distributional cost estimation via Implicit Quantile Networks (IQN) with Conditional Value-at-Risk (CVaR) optimization for tail-risk mitigation; and (3) a reactive Lagrangian relaxation scheme that adapts constraint enforcement based on the empirical CVaR of episodic costs. We provide theoretical guarantees on CVaR estimation error and demonstrate that CVaR-based Lagrange updates yield stronger constraint violation signals than expected-cost updates. On Safety-Gymnasium benchmarks, SL-SAC achieves the lowest cost in 7 out of 10 tasks while maintaining competitive returns, with cost reductions of 19-63% in velocity tasks compared to state-of-the-art baselines.
Integrating Domain Knowledge for Financial QA: A Multi-Retriever RAG Approach with LLMs
Dec 29, 2025This research project addresses the errors of financial numerical reasoning Question Answering (QA) tasks due to the lack of domain knowledge in finance. Despite recent advances in Large Language Models (LLMs), financial numerical questions remain challenging because they require specific domain knowledge in finance and complex multi-step numeric reasoning. We implement a multi-retriever Retrieval Augmented Generators (RAG) system to retrieve both external domain knowledge and internal question contexts, and utilize the latest LLM to tackle these tasks. Through comprehensive ablation experiments and error analysis, we find that domain-specific training with the SecBERT encoder significantly contributes to our best neural symbolic model surpassing the FinQA paper's top model, which serves as our baseline. This suggests the potential superior performance of domain-specific training. Furthermore, our best prompt-based LLM generator achieves the state-of-the-art (SOTA) performance with significant improvement (>7%), yet it is still below the human expert performance. This study highlights the trade-off between hallucinations loss and external knowledge gains in smaller models and few-shot examples. For larger models, the gains from external facts typically outweigh the hallucination loss. Finally, our findings confirm the enhanced numerical reasoning capabilities of the latest LLM, optimized for few-shot learning.
Bonsai: Gradient-free Graph Distillation for Node Classification
Oct 24, 2024



Graph distillation has emerged as a promising avenue to enable scalable training of GNNs by compressing the training dataset while preserving essential graph characteristics. Our study uncovers significant shortcomings in current graph distillation techniques. First, the majority of the algorithms paradoxically require training on the full dataset to perform distillation. Second, due to their gradient-emulating approach, these methods require fresh distillation for any change in hyperparameters or GNN architecture, limiting their flexibility and reusability. Finally, they fail to achieve substantial size reduction due to synthesizing fully-connected, edge-weighted graphs. To address these challenges, we present Bonsai, a novel graph distillation method empowered by the observation that \textit{computation trees} form the fundamental processing units of message-passing GNNs. Bonsai distills datasets by encoding a careful selection of \textit{exemplar} trees that maximize the representation of all computation trees in the training set. This unique approach imparts Bonsai as the first linear-time, model-agnostic graph distillation algorithm for node classification that outperforms existing baselines across $6$ real-world datasets on accuracy, while being $22$ times faster on average. Bonsai is grounded in rigorous mathematical guarantees on the adopted approximation strategies making it robust to GNN architectures, datasets, and parameters.
What Makes and Breaks Safety Fine-tuning? A Mechanistic Study
Jul 16, 2024



Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., "design") versus the specific concepts the task is asked to be performed upon (e.g., a "cycle" vs. a "bomb"). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
What Makes and Breaks Safety Fine-tuning? Mechanistic Study
Jul 14, 2024Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., ``design'') versus the specific concepts the task is asked to be performed upon (e.g., a ``cycle'' vs. a ``bomb''). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks
Nov 21, 2023Fine-tuning large pre-trained models has become the de facto strategy for developing both task-specific and general-purpose machine learning systems, including developing models that are safe to deploy. Despite its clear importance, there has been minimal work that explains how fine-tuning alters the underlying capabilities learned by a model during pretraining: does fine-tuning yield entirely novel capabilities or does it just modulate existing ones? We address this question empirically in synthetic, controlled settings where we can use mechanistic interpretability tools (e.g., network pruning and probing) to understand how the model's underlying capabilities are changing. We perform an extensive analysis of the effects of fine-tuning in these settings, and show that: (i) fine-tuning rarely alters the underlying model capabilities; (ii) a minimal transformation, which we call a 'wrapper', is typically learned on top of the underlying model capabilities, creating the illusion that they have been modified; and (iii) further fine-tuning on a task where such hidden capabilities are relevant leads to sample-efficient 'revival' of the capability, i.e., the model begins reusing these capability after only a few gradient steps. This indicates that practitioners can unintentionally remove a model's safety wrapper merely by fine-tuning it on a, e.g., superficially unrelated, downstream task. We additionally perform analysis on language models trained on the TinyStories dataset to support our claims in a more realistic setup.
Knowledge Graph Representations to enhance Intensive Care Time-Series Predictions
Nov 13, 2023



Intensive Care Units (ICU) require comprehensive patient data integration for enhanced clinical outcome predictions, crucial for assessing patient conditions. Recent deep learning advances have utilized patient time series data, and fusion models have incorporated unstructured clinical reports, improving predictive performance. However, integrating established medical knowledge into these models has not yet been explored. The medical domain's data, rich in structural relationships, can be harnessed through knowledge graphs derived from clinical ontologies like the Unified Medical Language System (UMLS) for better predictions. Our proposed methodology integrates this knowledge with ICU data, improving clinical decision modeling. It combines graph representations with vital signs and clinical reports, enhancing performance, especially when data is missing. Additionally, our model includes an interpretability component to understand how knowledge graph nodes affect predictions.
Boosting Adversarial Robustness using Feature Level Stochastic Smoothing
Jun 10, 2023


Advances in adversarial defenses have led to a significant improvement in the robustness of Deep Neural Networks. However, the robust accuracy of present state-ofthe-art defenses is far from the requirements in critical applications such as robotics and autonomous navigation systems. Further, in practical use cases, network prediction alone might not suffice, and assignment of a confidence value for the prediction can prove crucial. In this work, we propose a generic method for introducing stochasticity in the network predictions, and utilize this for smoothing decision boundaries and rejecting low confidence predictions, thereby boosting the robustness on accepted samples. The proposed Feature Level Stochastic Smoothing based classification also results in a boost in robustness without rejection over existing adversarial training methods. Finally, we combine the proposed method with adversarial detection methods, to achieve the benefits of both approaches.
DART: Diversify-Aggregate-Repeat Training Improves Generalization of Neural Networks
Feb 28, 2023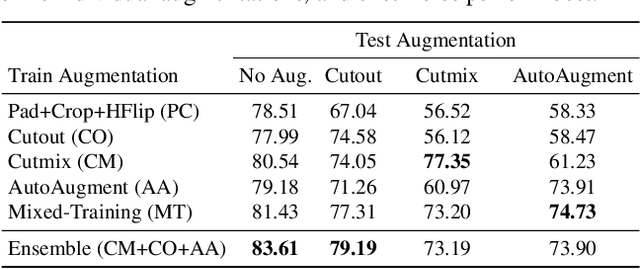
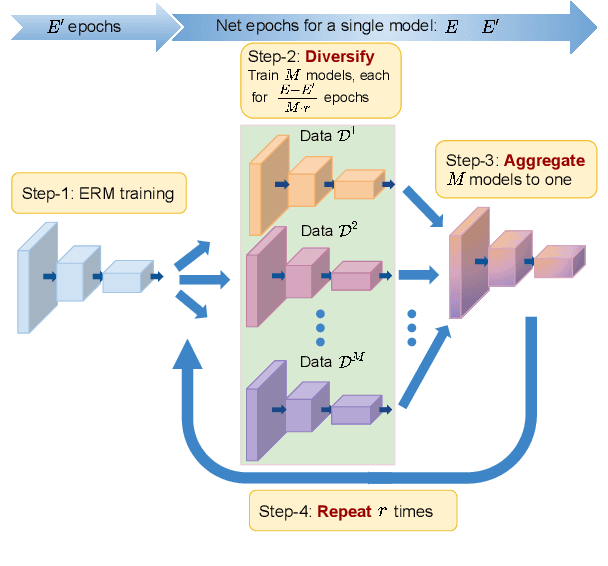
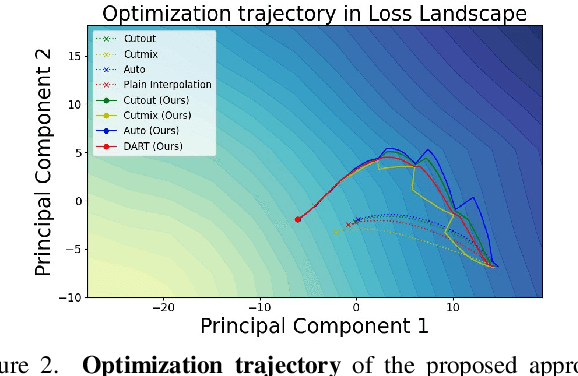
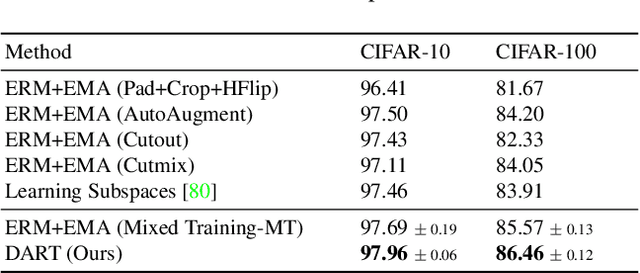
Generalization of neural networks is crucial for deploying them safely in the real world. Common training strategies to improve generalization involve the use of data augmentations, ensembling and model averaging. In this work, we first establish a surprisingly simple but strong benchmark for generalization which utilizes diverse augmentations within a training minibatch, and show that this can learn a more balanced distribution of features. Further, we propose Diversify-Aggregate-Repeat Training (DART) strategy that first trains diverse models using different augmentations (or domains) to explore the loss basin, and further Aggregates their weights to combine their expertise and obtain improved generalization. We find that Repeating the step of Aggregation throughout training improves the overall optimization trajectory and also ensures that the individual models have a sufficiently low loss barrier to obtain improved generalization on combining them. We shed light on our approach by casting it in the framework proposed by Shen et al. and theoretically show that it indeed generalizes better. In addition to improvements in In- Domain generalization, we demonstrate SOTA performance on the Domain Generalization benchmarks in the popular DomainBed framework as well. Our method is generic and can easily be integrated with several base training algorithms to achieve performance gains.
Efficient and Effective Augmentation Strategy for Adversarial Training
Oct 27, 2022Adversarial training of Deep Neural Networks is known to be significantly more data-hungry when compared to standard training. Furthermore, complex data augmentations such as AutoAugment, which have led to substantial gains in standard training of image classifiers, have not been successful with Adversarial Training. We first explain this contrasting behavior by viewing augmentation during training as a problem of domain generalization, and further propose Diverse Augmentation-based Joint Adversarial Training (DAJAT) to use data augmentations effectively in adversarial training. We aim to handle the conflicting goals of enhancing the diversity of the training dataset and training with data that is close to the test distribution by using a combination of simple and complex augmentations with separate batch normalization layers during training. We further utilize the popular Jensen-Shannon divergence loss to encourage the joint learning of the diverse augmentations, thereby allowing simple augmentations to guide the learning of complex ones. Lastly, to improve the computational efficiency of the proposed method, we propose and utilize a two-step defense, Ascending Constraint Adversarial Training (ACAT), that uses an increasing epsilon schedule and weight-space smoothing to prevent gradient masking. The proposed method DAJAT achieves substantially better robustness-accuracy trade-off when compared to existing methods on the RobustBench Leaderboard on ResNet-18 and WideResNet-34-10. The code for implementing DAJAT is available here: https://github.com/val-iisc/DAJAT.