 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteEmbed: Adapting CLIP to Rare Classes
Jan 14, 2026Large-scale vision-language models such as CLIP achieve strong zero-shot recognition but struggle with classes that are rarely seen during pretraining, including newly emerging entities and culturally specific categories. We introduce LiteEmbed, a lightweight framework for few-shot personalization of CLIP that enables new classes to be added without retraining its encoders. LiteEmbed performs subspace-guided optimization of text embeddings within CLIP's vocabulary, leveraging a PCA-based decomposition that disentangles coarse semantic directions from fine-grained variations. Two complementary objectives, coarse alignment and fine separation, jointly preserve global semantic consistency while enhancing discriminability among visually similar classes. Once optimized, the embeddings are plug-and-play, seamlessly substituting CLIP's original text features across classification, retrieval, segmentation, and detection tasks. Extensive experiments demonstrate substantial gains over prior methods, establishing LiteEmbed as an effective approach for adapting CLIP to underrepresented, rare, or unseen classes.
Concept Regions Matter: Benchmarking CLIP with a New Cluster-Importance Approach
Nov 17, 2025Contrastive vision-language models (VLMs) such as CLIP achieve strong zero-shot recognition yet remain vulnerable to spurious correlations, particularly background over-reliance. We introduce Cluster-based Concept Importance (CCI), a novel interpretability method that uses CLIP's own patch embeddings to group spatial patches into semantically coherent clusters, mask them, and evaluate relative changes in model predictions. CCI sets a new state of the art on faithfulness benchmarks, surpassing prior methods by large margins; for example, it yields more than a twofold improvement on the deletion-AUC metric for MS COCO retrieval. We further propose that CCI, when combined with GroundedSAM, automatically categorizes predictions as foreground- or background-driven, providing a crucial diagnostic ability. Existing benchmarks such as CounterAnimals, however, rely solely on accuracy and implicitly attribute all performance degradation to background correlations. Our analysis shows this assumption to be incomplete, since many errors arise from viewpoint variation, scale shifts, and fine-grained object confusions. To disentangle these effects, we introduce COVAR, a benchmark that systematically varies object foregrounds and backgrounds. Leveraging CCI with COVAR, we present a comprehensive evaluation of eighteen CLIP variants, offering methodological advances and empirical evidence that chart a path toward more robust VLMs.
Investigating Mechanisms for In-Context Vision Language Binding
May 28, 2025To understand a prompt, Vision-Language models (VLMs) must perceive the image, comprehend the text, and build associations within and across both modalities. For instance, given an 'image of a red toy car', the model should associate this image to phrases like 'car', 'red toy', 'red object', etc. Feng and Steinhardt propose the Binding ID mechanism in LLMs, suggesting that the entity and its corresponding attribute tokens share a Binding ID in the model activations. We investigate this for image-text binding in VLMs using a synthetic dataset and task that requires models to associate 3D objects in an image with their descriptions in the text. Our experiments demonstrate that VLMs assign a distinct Binding ID to an object's image tokens and its textual references, enabling in-context association.
EditIQ: Automated Cinematic Editing of Static Wide-Angle Videos via Dialogue Interpretation and Saliency Cues
Feb 04, 2025We present EditIQ, a completely automated framework for cinematically editing scenes captured via a stationary, large field-of-view and high-resolution camera. From the static camera feed, EditIQ initially generates multiple virtual feeds, emulating a team of cameramen. These virtual camera shots termed rushes are subsequently assembled using an automated editing algorithm, whose objective is to present the viewer with the most vivid scene content. To understand key scene elements and guide the editing process, we employ a two-pronged approach: (1) a large language model (LLM)-based dialogue understanding module to analyze conversational flow, coupled with (2) visual saliency prediction to identify meaningful scene elements and camera shots therefrom. We then formulate cinematic video editing as an energy minimization problem over shot selection, where cinematic constraints determine shot choices, transitions, and continuity. EditIQ synthesizes an aesthetically and visually compelling representation of the original narrative while maintaining cinematic coherence and a smooth viewing experience. Efficacy of EditIQ against competing baselines is demonstrated via a psychophysical study involving twenty participants on the BBC Old School dataset plus eleven theatre performance videos. Video samples from EditIQ can be found at https://editiq-ave.github.io/.
MRI2Speech: Speech Synthesis from Articulatory Movements Recorded by Real-time MRI
Dec 25, 2024



Previous real-time MRI (rtMRI)-based speech synthesis models depend heavily on noisy ground-truth speech. Applying loss directly over ground truth mel-spectrograms entangles speech content with MRI noise, resulting in poor intelligibility. We introduce a novel approach that adapts the multi-modal self-supervised AV-HuBERT model for text prediction from rtMRI and incorporates a new flow-based duration predictor for speaker-specific alignment. The predicted text and durations are then used by a speech decoder to synthesize aligned speech in any novel voice. We conduct thorough experiments on two datasets and demonstrate our method's generalization ability to unseen speakers. We assess our framework's performance by masking parts of the rtMRI video to evaluate the impact of different articulators on text prediction. Our method achieves a $15.18\%$ Word Error Rate (WER) on the USC-TIMIT MRI corpus, marking a huge improvement over the current state-of-the-art. Speech samples are available at \url{https://mri2speech.github.io/MRI2Speech/}
Advancing NAM-to-Speech Conversion with Novel Methods and the MultiNAM Dataset
Dec 25, 2024Current Non-Audible Murmur (NAM)-to-speech techniques rely on voice cloning to simulate ground-truth speech from paired whispers. However, the simulated speech often lacks intelligibility and fails to generalize well across different speakers. To address this issue, we focus on learning phoneme-level alignments from paired whispers and text and employ a Text-to-Speech (TTS) system to simulate the ground-truth. To reduce dependence on whispers, we learn phoneme alignments directly from NAMs, though the quality is constrained by the available training data. To further mitigate reliance on NAM/whisper data for ground-truth simulation, we propose incorporating the lip modality to infer speech and introduce a novel diffusion-based method that leverages recent advancements in lip-to-speech technology. Additionally, we release the MultiNAM dataset with over $7.96$ hours of paired NAM, whisper, video, and text data from two speakers and benchmark all methods on this dataset. Speech samples and the dataset are available at \url{https://diff-nam.github.io/DiffNAM/}
TIDE: Training Locally Interpretable Domain Generalization Models Enables Test-time Correction
Nov 25, 2024
We consider the problem of single-source domain generalization. Existing methods typically rely on extensive augmentations to synthetically cover diverse domains during training. However, they struggle with semantic shifts (e.g., background and viewpoint changes), as they often learn global features instead of local concepts that tend to be domain invariant. To address this gap, we propose an approach that compels models to leverage such local concepts during prediction. Given no suitable dataset with per-class concepts and localization maps exists, we first develop a novel pipeline to generate annotations by exploiting the rich features of diffusion and large-language models. Our next innovation is TIDE, a novel training scheme with a concept saliency alignment loss that ensures model focus on the right per-concept regions and a local concept contrastive loss that promotes learning domain-invariant concept representations. This not only gives a robust model but also can be visually interpreted using the predicted concept saliency maps. Given these maps at test time, our final contribution is a new correction algorithm that uses the corresponding local concept representations to iteratively refine the prediction until it aligns with prototypical concept representations that we store at the end of model training. We evaluate our approach extensively on four standard DG benchmark datasets and substantially outperform the current state-ofthe-art (12% improvement on average) while also demonstrating that our predictions can be visually interpreted
IdentifyMe: A Challenging Long-Context Mention Resolution Benchmark
Nov 12, 2024



Recent evaluations of LLMs on coreference resolution have revealed that traditional output formats and evaluation metrics do not fully capture the models' referential understanding. To address this, we introduce IdentifyMe, a new benchmark for mention resolution presented in a multiple-choice question (MCQ) format, commonly used for evaluating LLMs. IdentifyMe features long narratives and employs heuristics to exclude easily identifiable mentions, creating a more challenging task. The benchmark also consists of a curated mixture of different mention types and corresponding entities, allowing for a fine-grained analysis of model performance. We evaluate both closed- and open source LLMs on IdentifyMe and observe a significant performance gap (20-30%) between the state-of-the-art sub-10B open models vs. closed ones. We observe that pronominal mentions, which have limited surface information, are typically much harder for models to resolve than nominal mentions. Additionally, we find that LLMs often confuse entities when their mentions overlap in nested structures. The highest-scoring model, GPT-4o, achieves 81.9% accuracy, highlighting the strong referential capabilities of state-of-the-art LLMs while also indicating room for further improvement.
Towards Improving NAM-to-Speech Synthesis Intelligibility using Self-Supervised Speech Models
Jul 26, 2024


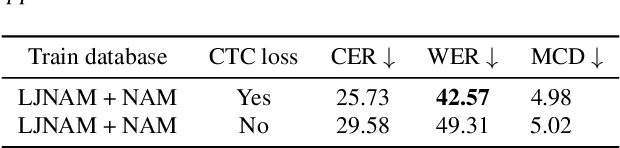
We propose a novel approach to significantly improve the intelligibility in the Non-Audible Murmur (NAM)-to-speech conversion task, leveraging self-supervision and sequence-to-sequence (Seq2Seq) learning techniques. Unlike conventional methods that explicitly record ground-truth speech, our methodology relies on self-supervision and speech-to-speech synthesis to simulate ground-truth speech. Despite utilizing simulated speech, our method surpasses the current state-of-the-art (SOTA) by 29.08% improvement in the Mel-Cepstral Distortion (MCD) metric. Additionally, we present error rates and demonstrate our model's proficiency to synthesize speech in novel voices of interest. Moreover, we present a methodology for augmenting the existing CSTR NAM TIMIT Plus corpus, setting a benchmark with a Word Error Rate (WER) of 42.57% to gauge the intelligibility of the synthesized speech. Speech samples can be found at https://nam2speech.github.io/NAM2Speech/
Major Entity Identification: A Generalizable Alternative to Coreference Resolution
Jun 20, 2024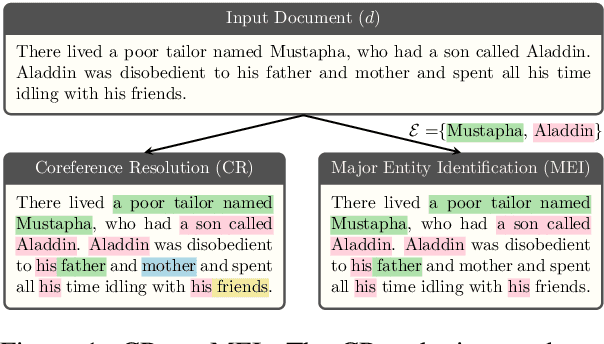
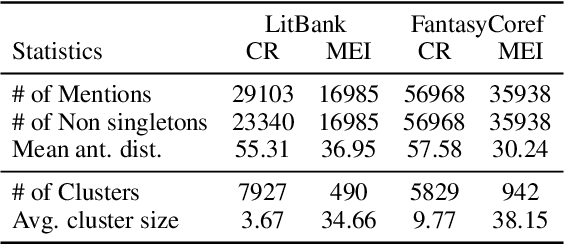
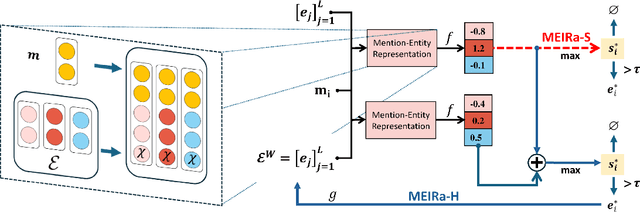

The limited generalization of coreference resolution (CR) models has been a major bottleneck in the task's broad application. Prior work has identified annotation differences, especially for mention detection, as one of the main reasons for the generalization gap and proposed using additional annotated target domain data. Rather than relying on this additional annotation, we propose an alternative formulation of the CR task, Major Entity Identification (MEI), where we: (a) assume the target entities to be specified in the input, and (b) limit the task to only the frequent entities. Through extensive experiments, we demonstrate that MEI models generalize well across domains on multiple datasets with supervised models and LLM-based few-shot prompting. Additionally, the MEI task fits the classification framework, which enables the use of classification-based metrics that are more robust than the current CR metrics. Finally, MEI is also of practical use as it allows a user to search for all mentions of a particular entity or a group of entities of interest.