 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAViNet: Diving Deep into Audio-Visual Saliency Prediction
Dec 11, 2020



We propose the \textbf{AViNet} architecture for audiovisual saliency prediction. AViNet is a fully convolutional encoder-decoder architecture. The encoder combines visual features learned for action recognition, with audio embeddings learned via an aural network designed to classify objects and scenes. The decoder infers a saliency map via trilinear interpolation and 3D convolutions, combining hierarchical features. The overall architecture is conceptually simple, causal, and runs in real-time (60 fps). AViNet outperforms the state-of-the-art on ten (seven audiovisual and three visual-only) datasets while surpassing human performance on the CC, SIM, and AUC metrics for the AVE dataset. Visual features maximally account for saliency on existing datasets with audio-only contributing to minor gains, except in specific contexts like social events. Our work, therefore, motivates the need to curate saliency datasets reflective of real-life, where both the visual and aural modalities complimentarily drive saliency. Our code and pre-trained models are available at https://github.com/samyak0210/VideoSaliency
Tidying Deep Saliency Prediction Architectures
Mar 10, 2020

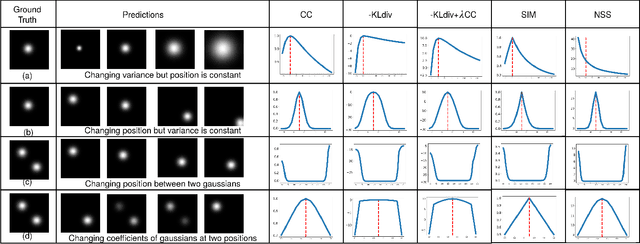

Learning computational models for visual attention (saliency estimation) is an effort to inch machines/robots closer to human visual cognitive abilities. Data-driven efforts have dominated the landscape since the introduction of deep neural network architectures. In deep learning research, the choices in architecture design are often empirical and frequently lead to more complex models than necessary. The complexity, in turn, hinders the application requirements. In this paper, we identify four key components of saliency models, i.e., input features, multi-level integration, readout architecture, and loss functions. We review the existing state of the art models on these four components and propose novel and simpler alternatives. As a result, we propose two novel end-to-end architectures called SimpleNet and MDNSal, which are neater, minimal, more interpretable and achieve state of the art performance on public saliency benchmarks. SimpleNet is an optimized encoder-decoder architecture and brings notable performance gains on the SALICON dataset (the largest saliency benchmark). MDNSal is a parametric model that directly predicts parameters of a GMM distribution and is aimed to bring more interpretability to the prediction maps. The proposed saliency models can be inferred at 25fps, making them suitable for real-time applications. Code and pre-trained models are available at https://github.com/samyak0210/saliency.