 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes and Breaks Safety Fine-tuning? A Mechanistic Study
Jul 16, 2024



Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., "design") versus the specific concepts the task is asked to be performed upon (e.g., a "cycle" vs. a "bomb"). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
What Makes and Breaks Safety Fine-tuning? Mechanistic Study
Jul 14, 2024Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., ``design'') versus the specific concepts the task is asked to be performed upon (e.g., a ``cycle'' vs. a ``bomb''). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
MoCaE: Mixture of Calibrated Experts Significantly Improves Object Detection
Sep 27, 2023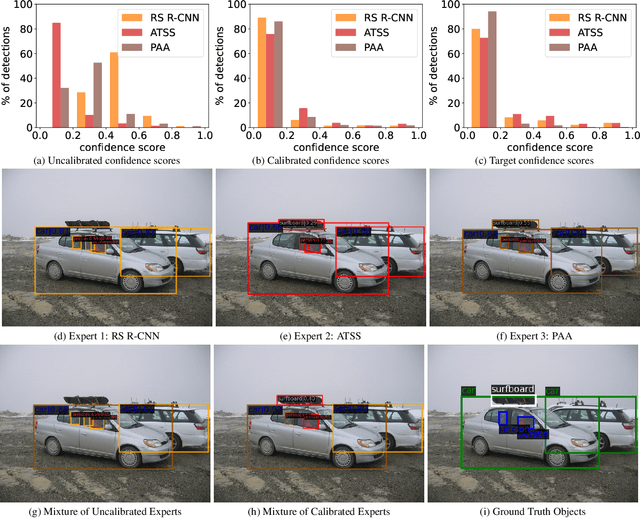
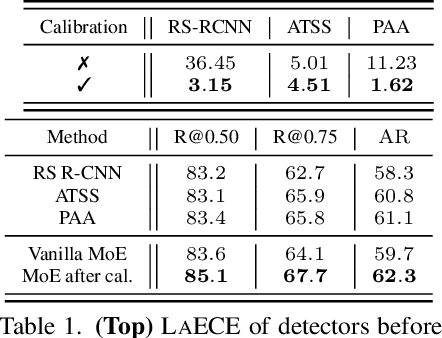
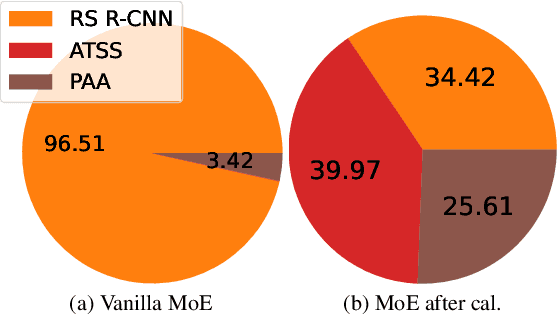
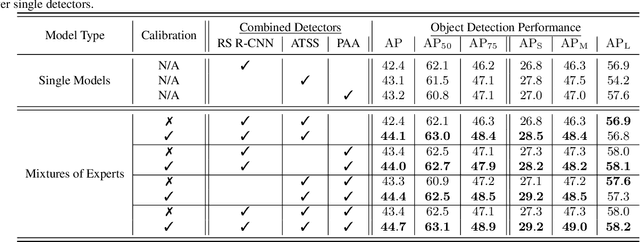
We propose an extremely simple and highly effective approach to faithfully combine different object detectors to obtain a Mixture of Experts (MoE) that has a superior accuracy to the individual experts in the mixture. We find that naively combining these experts in a similar way to the well-known Deep Ensembles (DEs), does not result in an effective MoE. We identify the incompatibility between the confidence score distribution of different detectors to be the primary reason for such failure cases. Therefore, to construct the MoE, our proposal is to first calibrate each individual detector against a target calibration function. Then, filter and refine all the predictions from different detectors in the mixture. We term this approach as MoCaE and demonstrate its effectiveness through extensive experiments on object detection, instance segmentation and rotated object detection tasks. Specifically, MoCaE improves (i) three strong object detectors on COCO test-dev by $2.4$ $\mathrm{AP}$ by reaching $59.0$ $\mathrm{AP}$; (ii) instance segmentation methods on the challenging long-tailed LVIS dataset by $2.3$ $\mathrm{AP}$; and (iii) all existing rotated object detectors by reaching $82.62$ $\mathrm{AP_{50}}$ on DOTA dataset, establishing a new state-of-the-art (SOTA). Code will be made public.
Towards Building Self-Aware Object Detectors via Reliable Uncertainty Quantification and Calibration
Jul 03, 2023



The current approach for testing the robustness of object detectors suffers from serious deficiencies such as improper methods of performing out-of-distribution detection and using calibration metrics which do not consider both localisation and classification quality. In this work, we address these issues, and introduce the Self-Aware Object Detection (SAOD) task, a unified testing framework which respects and adheres to the challenges that object detectors face in safety-critical environments such as autonomous driving. Specifically, the SAOD task requires an object detector to be: robust to domain shift; obtain reliable uncertainty estimates for the entire scene; and provide calibrated confidence scores for the detections. We extensively use our framework, which introduces novel metrics and large scale test datasets, to test numerous object detectors in two different use-cases, allowing us to highlight critical insights into their robustness performance. Finally, we introduce a simple baseline for the SAOD task, enabling researchers to benchmark future proposed methods and move towards robust object detectors which are fit for purpose. Code is available at https://github.com/fiveai/saod
Sample-dependent Adaptive Temperature Scaling for Improved Calibration
Jul 22, 2022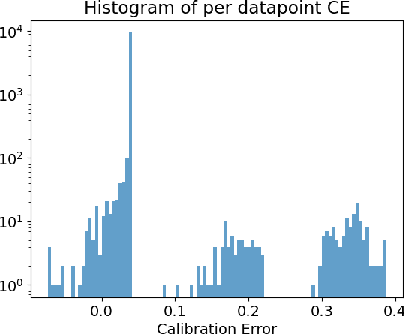
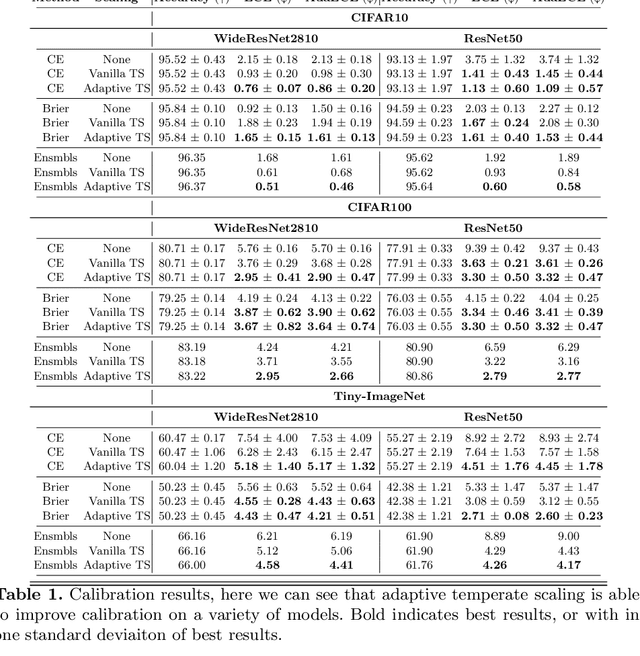
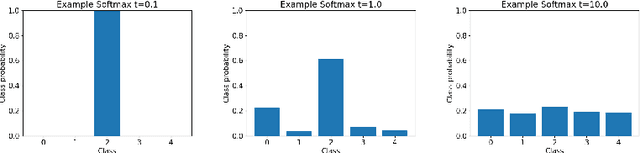
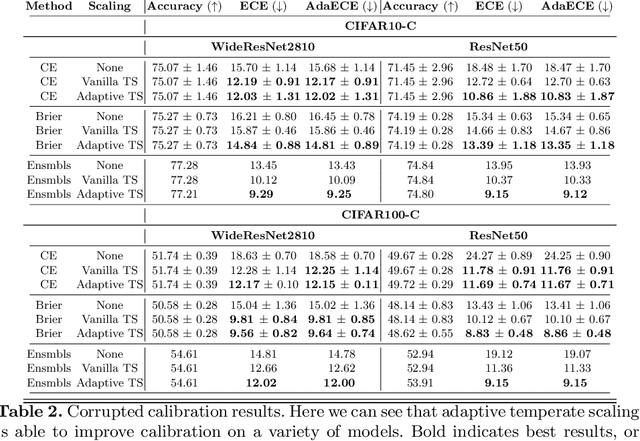
It is now well known that neural networks can be wrong with high confidence in their predictions, leading to poor calibration. The most common post-hoc approach to compensate for this is to perform temperature scaling, which adjusts the confidences of the predictions on any input by scaling the logits by a fixed value. Whilst this approach typically improves the average calibration across the whole test dataset, this improvement typically reduces the individual confidences of the predictions irrespective of whether the classification of a given input is correct or incorrect. With this insight, we base our method on the observation that different samples contribute to the calibration error by varying amounts, with some needing to increase their confidence and others needing to decrease it. Therefore, for each input, we propose to predict a different temperature value, allowing us to adjust the mismatch between confidence and accuracy at a finer granularity. Furthermore, we observe improved results on OOD detection and can also extract a notion of hardness for the data-points. Our method is applied post-hoc, consequently using very little computation time and with a negligible memory footprint and is applied to off-the-shelf pre-trained classifiers. We test our method on the ResNet50 and WideResNet28-10 architectures using the CIFAR10/100 and Tiny-ImageNet datasets, showing that producing per-data-point temperatures is beneficial also for the expected calibration error across the whole test set. Code is available at: https://github.com/thwjoy/adats.
Learning Multimodal VAEs through Mutual Supervision
Jul 01, 2021

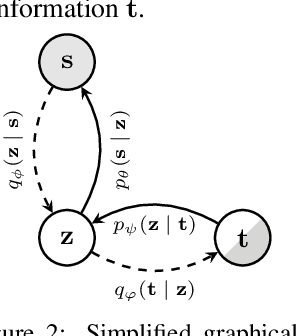

Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.
Rethinking Semi-Supervised Learning in VAEs
Jun 17, 2020
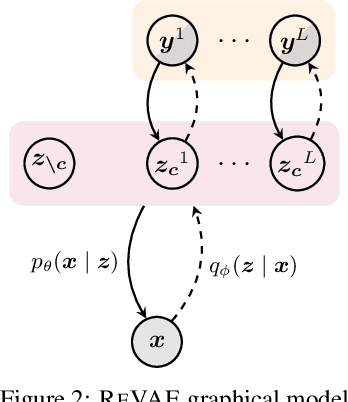

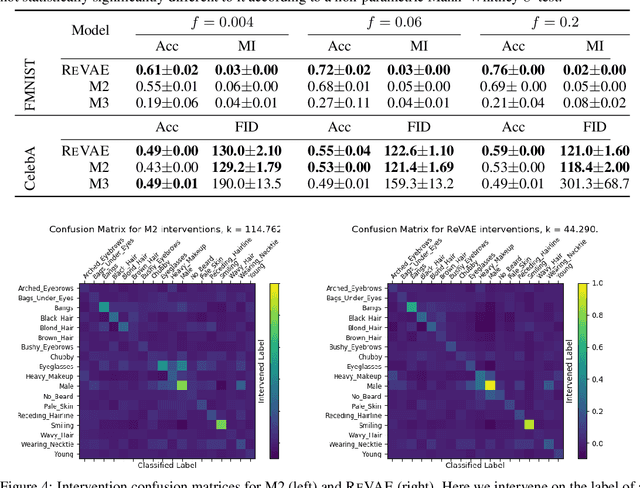
We present an alternative approach to semi-supervision in variational autoencoders(VAEs) that incorporates labels through auxiliary variables rather than directly through the latent variables. Prior work has generally conflated the meaning of labels, i.e. the associated characteristics of interest, with the actual label values themselves-learning latent variables that directly correspond to the label values. We argue that to learn meaningful representations, semi-supervision should instead try to capture these richer characteristics and that the construction of latent variables as label values is not just unnecessary, but actively harmful. To this end, we develop a novel VAE model, the reparameterized VAE (ReVAE), which "reparameterizes" supervision through auxiliary variables and a concomitant variational objective. Through judicious structuring of mappings between latent and auxiliary variables, we show that the ReVAE can effectively learn meaningful representations of data. In particular, we demonstrate that the ReVAE is able to match, and even improve on the classification accuracy of previous approaches, but more importantly, it also allows for more effective and more general interventions to be performed. We include a demo of ReVAE at https://github.com/thwjoy/revae-demo.