 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Impact of Model Misspecification in Neural Simulation-based Inference
Sep 05, 2022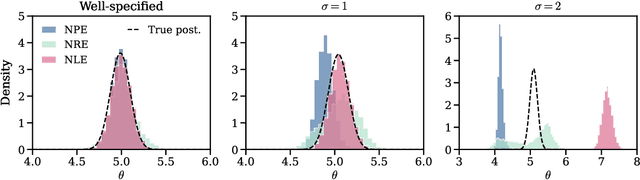
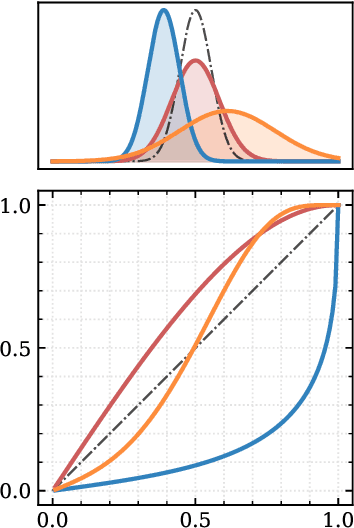
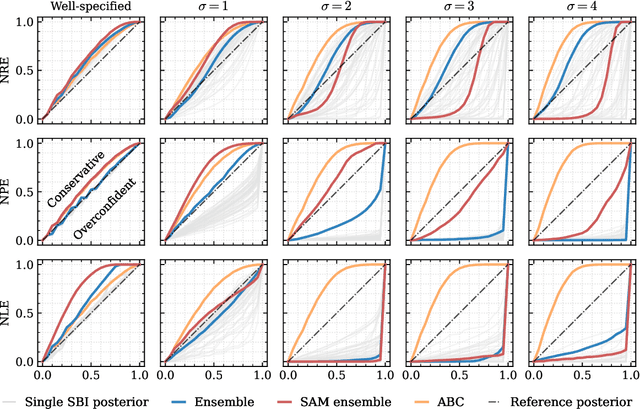
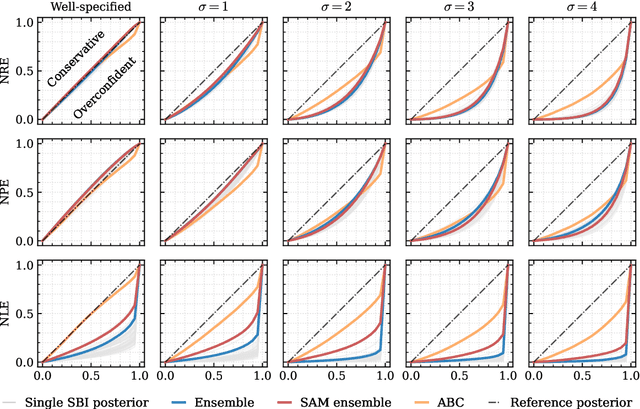
Aided by advances in neural density estimation, considerable progress has been made in recent years towards a suite of simulation-based inference (SBI) methods capable of performing flexible, black-box, approximate Bayesian inference for stochastic simulation models. While it has been demonstrated that neural SBI methods can provide accurate posterior approximations, the simulation studies establishing these results have considered only well-specified problems -- that is, where the model and the data generating process coincide exactly. However, the behaviour of such algorithms in the case of model misspecification has received little attention. In this work, we provide the first comprehensive study of the behaviour of neural SBI algorithms in the presence of various forms of model misspecification. We find that misspecification can have a profoundly deleterious effect on performance. Some mitigation strategies are explored, but no approach tested prevents failure in all cases. We conclude that new approaches are required to address model misspecification if neural SBI algorithms are to be relied upon to derive accurate scientific conclusions.
High Performance Simulation for Scalable Multi-Agent Reinforcement Learning
Jul 08, 2022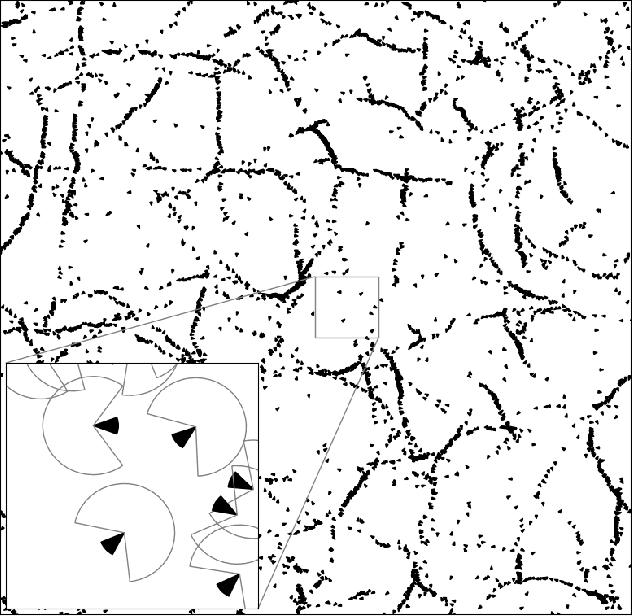
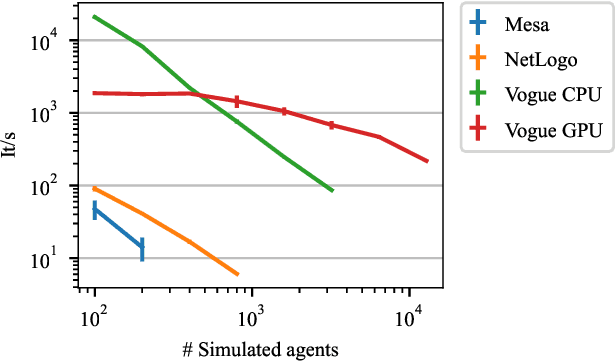
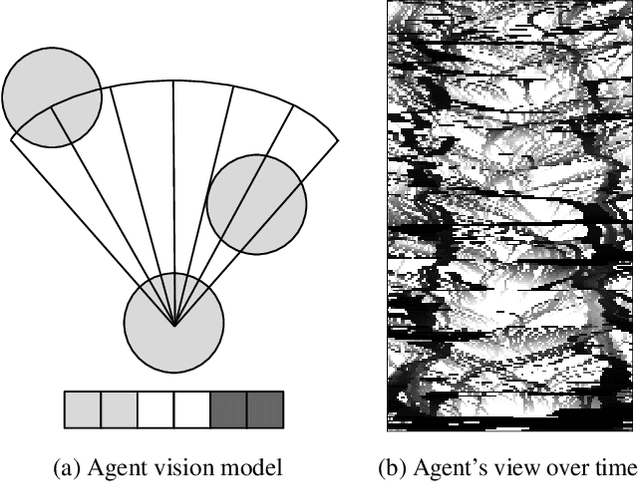
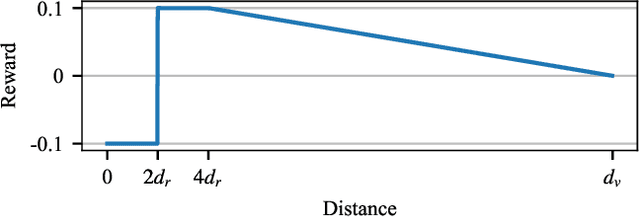
Multi-agent reinforcement learning experiments and open-source training environments are typically limited in scale, supporting tens or sometimes up to hundreds of interacting agents. In this paper we demonstrate the use of Vogue, a high performance agent based model (ABM) framework. Vogue serves as a multi-agent training environment, supporting thousands to tens of thousands of interacting agents while maintaining high training throughput by running both the environment and reinforcement learning (RL) agents on the GPU. High performance multi-agent environments at this scale have the potential to enable the learning of robust and flexible policies for use in ABMs and simulations of complex systems. We demonstrate training performance with two newly developed, large scale multi-agent training environments. Moreover, we show that these environments can train shared RL policies on time-scales of minutes and hours.
Calibrating Agent-based Models to Microdata with Graph Neural Networks
Jun 15, 2022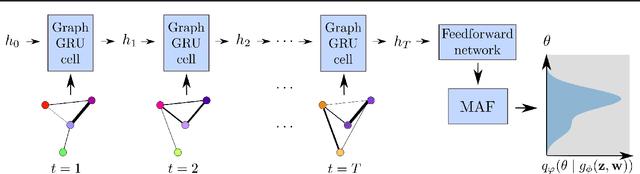
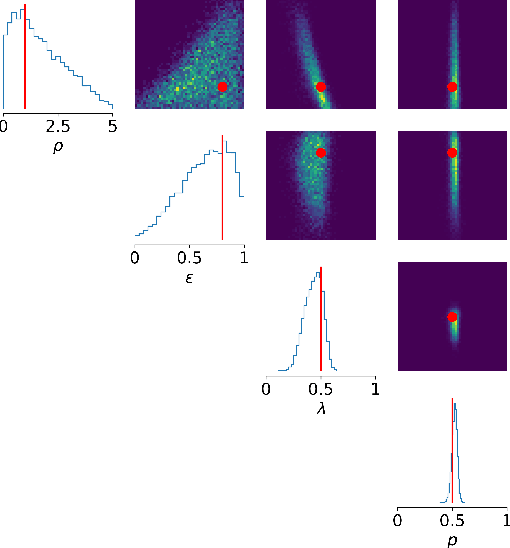
Calibrating agent-based models (ABMs) to data is among the most fundamental requirements to ensure the model fulfils its desired purpose. In recent years, simulation-based inference methods have emerged as powerful tools for performing this task when the model likelihood function is intractable, as is often the case for ABMs. In some real-world use cases of ABMs, both the observed data and the ABM output consist of the agents' states and their interactions over time. In such cases, there is a tension between the desire to make full use of the rich information content of such granular data on the one hand, and the need to reduce the dimensionality of the data to prevent difficulties associated with high-dimensional learning tasks on the other. A possible resolution is to construct lower-dimensional time-series through the use of summary statistics describing the macrostate of the system at each time point. However, a poor choice of summary statistics can result in an unacceptable loss of information from the original dataset, dramatically reducing the quality of the resulting calibration. In this work, we instead propose to learn parameter posteriors associated with granular microdata directly using temporal graph neural networks. We will demonstrate that such an approach offers highly compelling inductive biases for Bayesian inference using the raw ABM microstates as output.
Learning Multimodal VAEs through Mutual Supervision
Jul 01, 2021

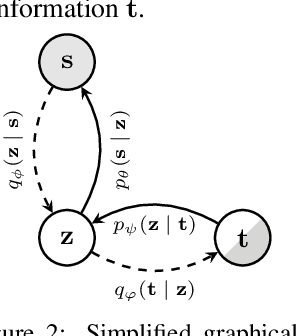

Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.
Rethinking Semi-Supervised Learning in VAEs
Jun 17, 2020
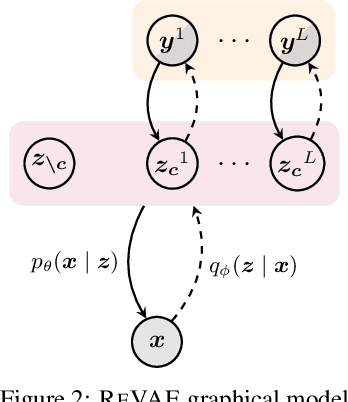

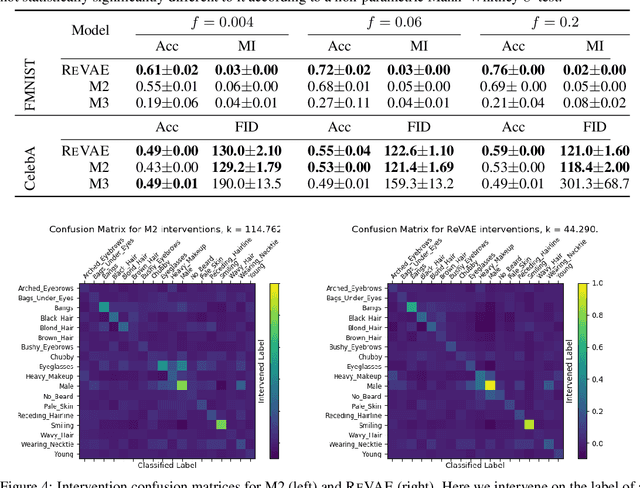
We present an alternative approach to semi-supervision in variational autoencoders(VAEs) that incorporates labels through auxiliary variables rather than directly through the latent variables. Prior work has generally conflated the meaning of labels, i.e. the associated characteristics of interest, with the actual label values themselves-learning latent variables that directly correspond to the label values. We argue that to learn meaningful representations, semi-supervision should instead try to capture these richer characteristics and that the construction of latent variables as label values is not just unnecessary, but actively harmful. To this end, we develop a novel VAE model, the reparameterized VAE (ReVAE), which "reparameterizes" supervision through auxiliary variables and a concomitant variational objective. Through judicious structuring of mappings between latent and auxiliary variables, we show that the ReVAE can effectively learn meaningful representations of data. In particular, we demonstrate that the ReVAE is able to match, and even improve on the classification accuracy of previous approaches, but more importantly, it also allows for more effective and more general interventions to be performed. We include a demo of ReVAE at https://github.com/thwjoy/revae-demo.