 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Neural Posterior Estimation and Statistical Model Criticism
Oct 12, 2022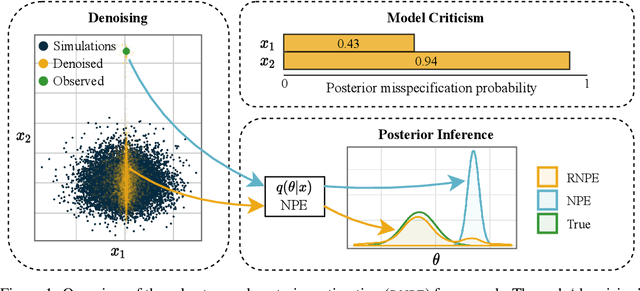
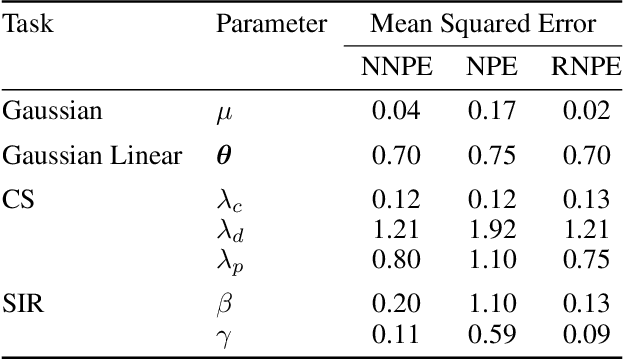
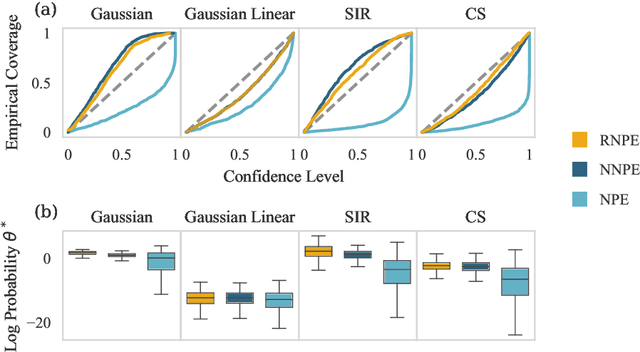
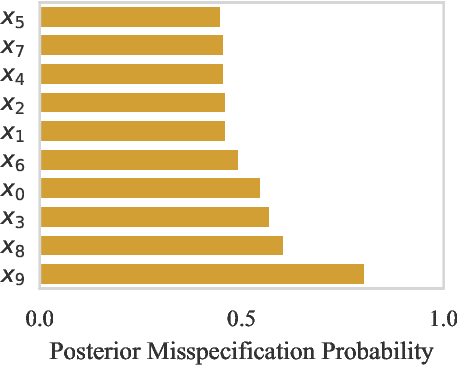
Computer simulations have proven a valuable tool for understanding complex phenomena across the sciences. However, the utility of simulators for modelling and forecasting purposes is often restricted by low data quality, as well as practical limits to model fidelity. In order to circumvent these difficulties, we argue that modellers must treat simulators as idealistic representations of the true data generating process, and consequently should thoughtfully consider the risk of model misspecification. In this work we revisit neural posterior estimation (NPE), a class of algorithms that enable black-box parameter inference in simulation models, and consider the implication of a simulation-to-reality gap. While recent works have demonstrated reliable performance of these methods, the analyses have been performed using synthetic data generated by the simulator model itself, and have therefore only addressed the well-specified case. In this paper, we find that the presence of misspecification, in contrast, leads to unreliable inference when NPE is used naively. As a remedy we argue that principled scientific inquiry with simulators should incorporate a model criticism component, to facilitate interpretable identification of misspecification and a robust inference component, to fit 'wrong but useful' models. We propose robust neural posterior estimation (RNPE), an extension of NPE to simultaneously achieve both these aims, through explicitly modelling the discrepancies between simulations and the observed data. We assess the approach on a range of artificially misspecified examples, and find RNPE performs well across the tasks, whereas naively using NPE leads to misleading and erratic posteriors.
Investigating the Impact of Model Misspecification in Neural Simulation-based Inference
Sep 05, 2022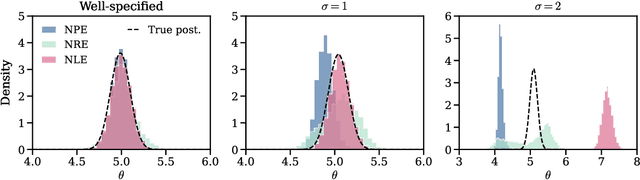
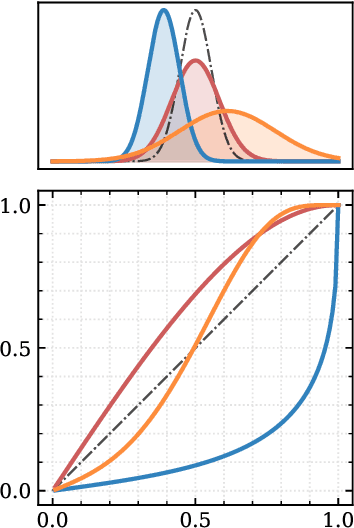
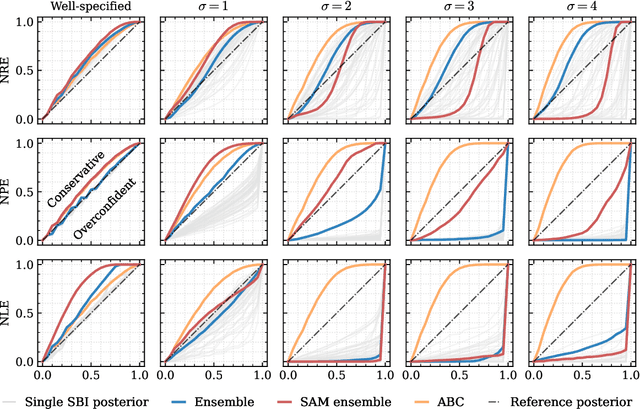
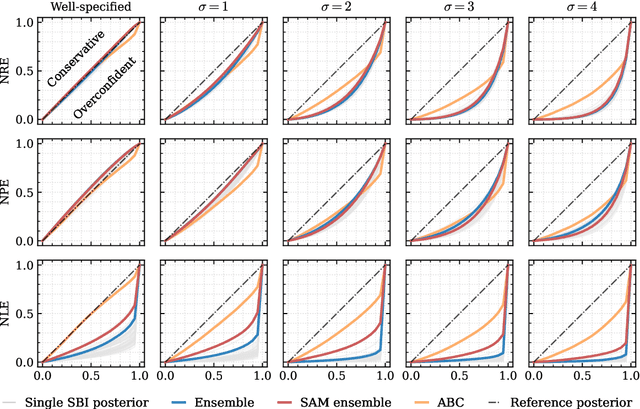
Aided by advances in neural density estimation, considerable progress has been made in recent years towards a suite of simulation-based inference (SBI) methods capable of performing flexible, black-box, approximate Bayesian inference for stochastic simulation models. While it has been demonstrated that neural SBI methods can provide accurate posterior approximations, the simulation studies establishing these results have considered only well-specified problems -- that is, where the model and the data generating process coincide exactly. However, the behaviour of such algorithms in the case of model misspecification has received little attention. In this work, we provide the first comprehensive study of the behaviour of neural SBI algorithms in the presence of various forms of model misspecification. We find that misspecification can have a profoundly deleterious effect on performance. Some mitigation strategies are explored, but no approach tested prevents failure in all cases. We conclude that new approaches are required to address model misspecification if neural SBI algorithms are to be relied upon to derive accurate scientific conclusions.
High Performance Simulation for Scalable Multi-Agent Reinforcement Learning
Jul 08, 2022
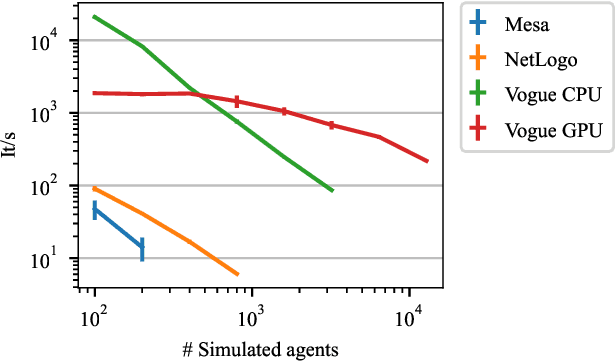
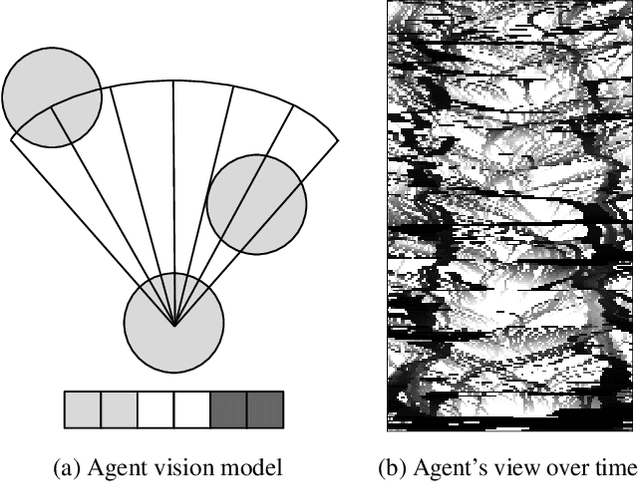
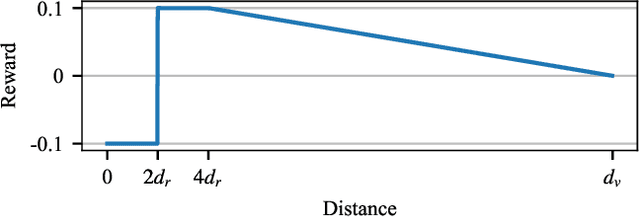
Multi-agent reinforcement learning experiments and open-source training environments are typically limited in scale, supporting tens or sometimes up to hundreds of interacting agents. In this paper we demonstrate the use of Vogue, a high performance agent based model (ABM) framework. Vogue serves as a multi-agent training environment, supporting thousands to tens of thousands of interacting agents while maintaining high training throughput by running both the environment and reinforcement learning (RL) agents on the GPU. High performance multi-agent environments at this scale have the potential to enable the learning of robust and flexible policies for use in ABMs and simulations of complex systems. We demonstrate training performance with two newly developed, large scale multi-agent training environments. Moreover, we show that these environments can train shared RL policies on time-scales of minutes and hours.
Calibrating Agent-based Models to Microdata with Graph Neural Networks
Jun 15, 2022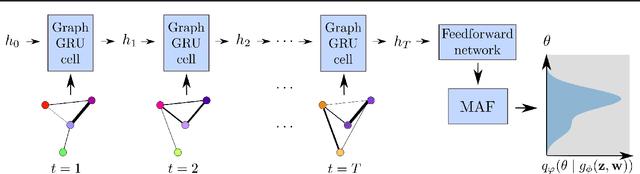
Calibrating agent-based models (ABMs) to data is among the most fundamental requirements to ensure the model fulfils its desired purpose. In recent years, simulation-based inference methods have emerged as powerful tools for performing this task when the model likelihood function is intractable, as is often the case for ABMs. In some real-world use cases of ABMs, both the observed data and the ABM output consist of the agents' states and their interactions over time. In such cases, there is a tension between the desire to make full use of the rich information content of such granular data on the one hand, and the need to reduce the dimensionality of the data to prevent difficulties associated with high-dimensional learning tasks on the other. A possible resolution is to construct lower-dimensional time-series through the use of summary statistics describing the macrostate of the system at each time point. However, a poor choice of summary statistics can result in an unacceptable loss of information from the original dataset, dramatically reducing the quality of the resulting calibration. In this work, we instead propose to learn parameter posteriors associated with granular microdata directly using temporal graph neural networks. We will demonstrate that such an approach offers highly compelling inductive biases for Bayesian inference using the raw ABM microstates as output.
Amortised Likelihood-free Inference for Expensive Time-series Simulators with Signatured Ratio Estimation
Feb 23, 2022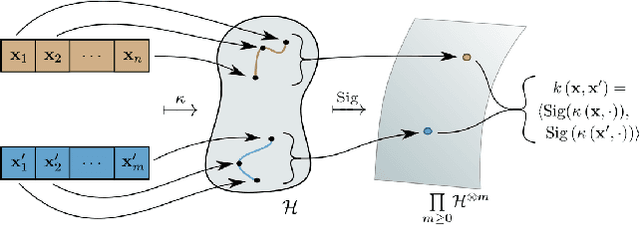

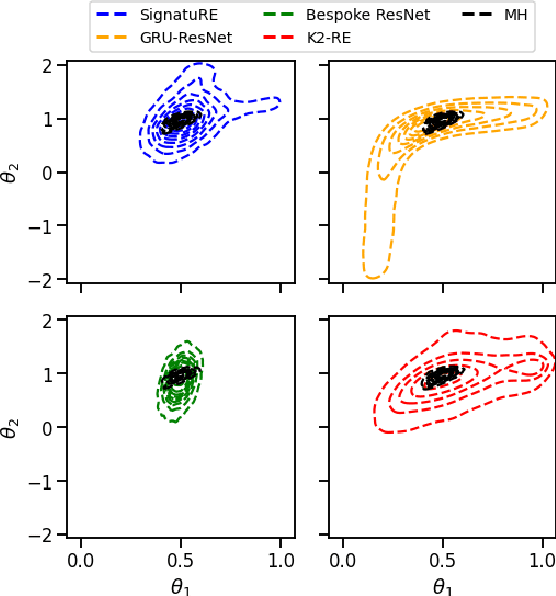
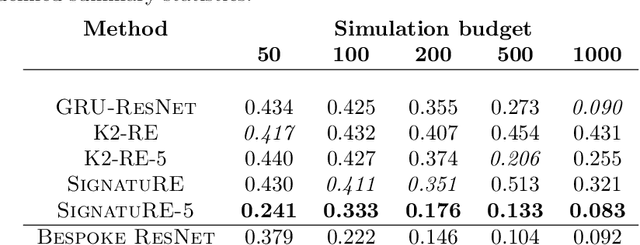
Simulation models of complex dynamics in the natural and social sciences commonly lack a tractable likelihood function, rendering traditional likelihood-based statistical inference impossible. Recent advances in machine learning have introduced novel algorithms for estimating otherwise intractable likelihood functions using a likelihood ratio trick based on binary classifiers. Consequently, efficient likelihood approximations can be obtained whenever good probabilistic classifiers can be constructed. We propose a kernel classifier for sequential data using path signatures based on the recently introduced signature kernel. We demonstrate that the representative power of signatures yields a highly performant classifier, even in the crucially important case where sample numbers are low. In such scenarios, our approach can outperform sophisticated neural networks for common posterior inference tasks.
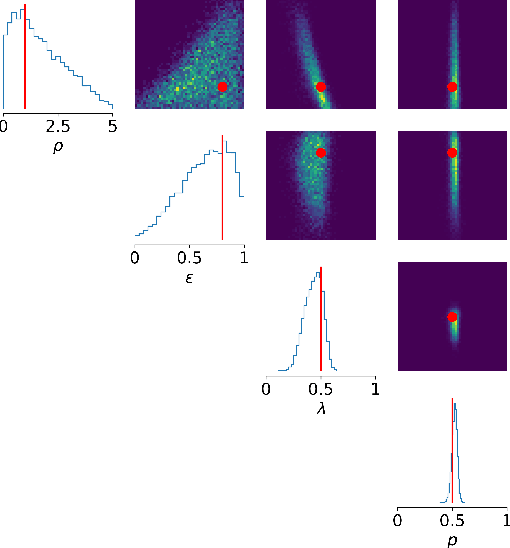
Black-box Bayesian inference for economic agent-based models
Feb 01, 2022



Simulation models, in particular agent-based models, are gaining popularity in economics. The considerable flexibility they offer, as well as their capacity to reproduce a variety of empirically observed behaviours of complex systems, give them broad appeal, and the increasing availability of cheap computing power has made their use feasible. Yet a widespread adoption in real-world modelling and decision-making scenarios has been hindered by the difficulty of performing parameter estimation for such models. In general, simulation models lack a tractable likelihood function, which precludes a straightforward application of standard statistical inference techniques. Several recent works have sought to address this problem through the application of likelihood-free inference techniques, in which parameter estimates are determined by performing some form of comparison between the observed data and simulation output. However, these approaches are (a) founded on restrictive assumptions, and/or (b) typically require many hundreds of thousands of simulations. These qualities make them unsuitable for large-scale simulations in economics and can cast doubt on the validity of these inference methods in such scenarios. In this paper, we investigate the efficacy of two classes of black-box approximate Bayesian inference methods that have recently drawn significant attention within the probabilistic machine learning community: neural posterior estimation and neural density ratio estimation. We present benchmarking experiments in which we demonstrate that neural network based black-box methods provide state of the art parameter inference for economic simulation models, and crucially are compatible with generic multivariate time-series data. In addition, we suggest appropriate assessment criteria for future benchmarking of approximate Bayesian inference procedures for economic simulation models.
Approximate Bayesian Computation with Path Signatures
Jun 23, 2021



Simulation models of scientific interest often lack a tractable likelihood function, precluding standard likelihood-based statistical inference. A popular likelihood-free method for inferring simulator parameters is approximate Bayesian computation, where an approximate posterior is sampled by comparing simulator output and observed data. However, effective measures of closeness between simulated and observed data are generally difficult to construct, particularly for time series data which are often high-dimensional and structurally complex. Existing approaches typically involve manually constructing summary statistics, requiring substantial domain expertise and experimentation, or rely on unrealistic assumptions such as iid data. Others are inappropriate in more complex settings like multivariate or irregularly sampled time series data. In this paper, we introduce the use of path signatures as a natural candidate feature set for constructing distances between time series data for use in approximate Bayesian computation algorithms. Our experiments show that such an approach can generate more accurate approximate Bayesian posteriors than existing techniques for time series models.