 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers
Feb 13, 2026Mixture-of-Experts (MoE) architectures are often considered a natural fit for continual learning because sparse routing should localize updates and reduce interference, yet MoE Transformers still forget substantially even with sparse, well-balanced expert utilization. We attribute this gap to a pre-routing bottleneck: multi-head attention concatenates head-specific signals into a single post-attention router input, forcing routing to act on co-occurring feature compositions rather than separable head channels. We show that this router input simultaneously encodes multiple separately decodable semantic and structural factors with uneven head support, and that different feature compositions induce weakly aligned parameter-gradient directions; as a result, routing maps many distinct compositions to the same route. We quantify this collision effect via a route-wise effective composition number $N_{eff}$ and find that higher $N_{eff}$ is associated with larger old-task loss increases after continual training. Motivated by these findings, we propose MH-MoE, which performs head-wise routing over sub-representations to increase routing granularity and reduce composition collisions. On TRACE with Qwen3-0.6B/8B, MH-MoE effectively mitigates forgetting, reducing BWT on Qwen3-0.6B from 11.2% (LoRAMoE) to 4.5%.
SD-MoE: Spectral Decomposition for Effective Expert Specialization
Feb 13, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.
A Percolation Model of Emergence: Analyzing Transformers Trained on a Formal Language
Aug 22, 2024Increase in data, size, or compute can lead to sudden learning of specific capabilities by a neural network -- a phenomenon often called "emergence". Beyond scientific understanding, establishing the causal factors underlying such emergent capabilities is crucial to enable risk regulation frameworks for AI. In this work, we seek inspiration from study of emergent properties in other fields and propose a phenomenological definition for the concept in the context of neural networks. Our definition implicates the acquisition of specific structures underlying the data-generating process as a cause of sudden performance growth for specific, narrower tasks. We empirically investigate this definition by proposing an experimental system grounded in a context-sensitive formal language and find that Transformers trained to perform tasks on top of strings from this language indeed exhibit emergent capabilities. Specifically, we show that once the language's underlying grammar and context-sensitivity inducing structures are learned by the model, performance on narrower tasks suddenly begins to improve. We then analogize our network's learning dynamics with the process of percolation on a bipartite graph, establishing a formal phase transition model that predicts the shift in the point of emergence observed in experiment when changing the data structure. Overall, our experimental and theoretical frameworks yield a step towards better defining, characterizing, and predicting emergence in neural networks.
Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models
May 13, 2024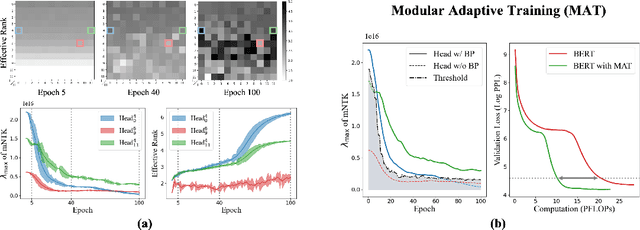

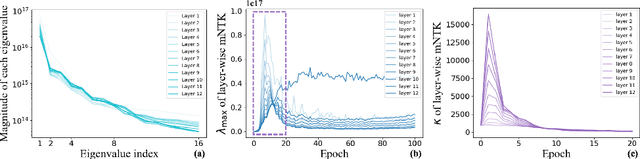

Despite their prevalence in deep-learning communities, over-parameterized models convey high demands of computational costs for proper training. This work studies the fine-grained, modular-level learning dynamics of over-parameterized models to attain a more efficient and fruitful training strategy. Empirical evidence reveals that when scaling down into network modules, such as heads in self-attention models, we can observe varying learning patterns implicitly associated with each module's trainability. To describe such modular-level learning capabilities, we introduce a novel concept dubbed modular neural tangent kernel (mNTK), and we demonstrate that the quality of a module's learning is tightly associated with its mNTK's principal eigenvalue $\lambda_{\max}$. A large $\lambda_{\max}$ indicates that the module learns features with better convergence, while those miniature ones may impact generalization negatively. Inspired by the discovery, we propose a novel training strategy termed Modular Adaptive Training (MAT) to update those modules with their $\lambda_{\max}$ exceeding a dynamic threshold selectively, concentrating the model on learning common features and ignoring those inconsistent ones. Unlike most existing training schemes with a complete BP cycle across all network modules, MAT can significantly save computations by its partially-updating strategy and can further improve performance. Experiments show that MAT nearly halves the computational cost of model training and outperforms the accuracy of baselines.
How Capable Can a Transformer Become? A Study on Synthetic, Interpretable Tasks
Nov 21, 2023Transformers trained on huge text corpora exhibit a remarkable set of capabilities, e.g., performing simple logical operations. Given the inherent compositional nature of language, one can expect the model to learn to compose these capabilities, potentially yielding a combinatorial explosion of what operations it can perform on an input. Motivated by the above, we aim to assess in this paper "how capable can a transformer become?". Specifically, we train autoregressive Transformer models on a data-generating process that involves compositions of a set of well-defined monolithic capabilities. Through a series of extensive and systematic experiments on this data-generating process, we show that: (1) autoregressive Transformers can learn compositional structures from the training data and generalize to exponentially or even combinatorially many functions; (2) composing functions by generating intermediate outputs is more effective at generalizing to unseen compositions, compared to generating no intermediate outputs; (3) the training data has a significant impact on the model's ability to compose unseen combinations of functions; and (4) the attention layers in the latter half of the model are critical to compositionality.
Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks
Nov 21, 2023Fine-tuning large pre-trained models has become the de facto strategy for developing both task-specific and general-purpose machine learning systems, including developing models that are safe to deploy. Despite its clear importance, there has been minimal work that explains how fine-tuning alters the underlying capabilities learned by a model during pretraining: does fine-tuning yield entirely novel capabilities or does it just modulate existing ones? We address this question empirically in synthetic, controlled settings where we can use mechanistic interpretability tools (e.g., network pruning and probing) to understand how the model's underlying capabilities are changing. We perform an extensive analysis of the effects of fine-tuning in these settings, and show that: (i) fine-tuning rarely alters the underlying model capabilities; (ii) a minimal transformation, which we call a 'wrapper', is typically learned on top of the underlying model capabilities, creating the illusion that they have been modified; and (iii) further fine-tuning on a task where such hidden capabilities are relevant leads to sample-efficient 'revival' of the capability, i.e., the model begins reusing these capability after only a few gradient steps. This indicates that practitioners can unintentionally remove a model's safety wrapper merely by fine-tuning it on a, e.g., superficially unrelated, downstream task. We additionally perform analysis on language models trained on the TinyStories dataset to support our claims in a more realistic setup.
In-Context Learning Dynamics with Random Binary Sequences
Oct 26, 2023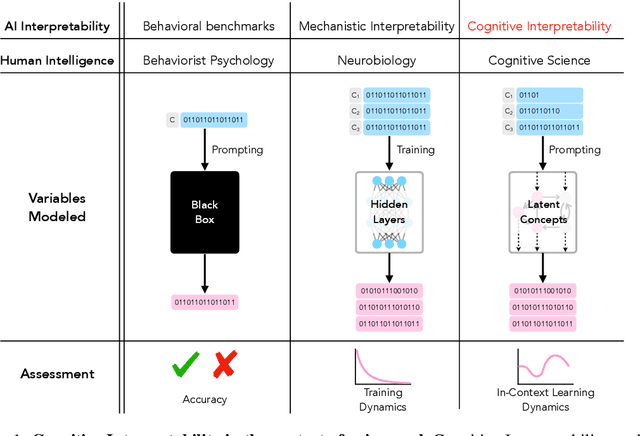
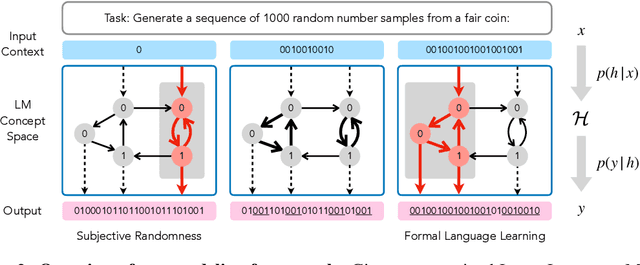
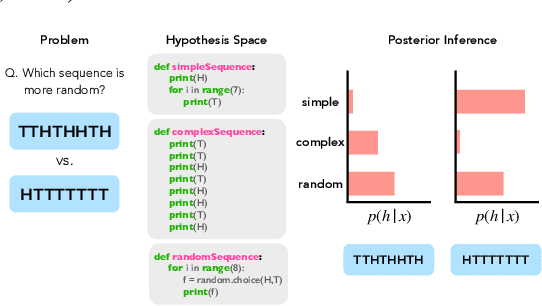
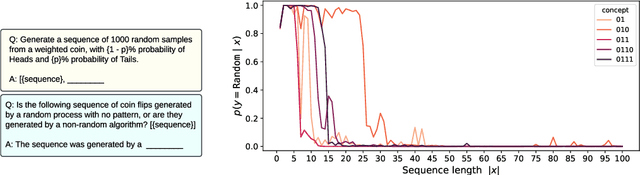
Large language models (LLMs) trained on huge corpora of text datasets demonstrate complex, emergent capabilities, achieving state-of-the-art performance on tasks they were not explicitly trained for. The precise nature of LLM capabilities is often mysterious, and different prompts can elicit different capabilities through in-context learning. We propose a Cognitive Interpretability framework that enables us to analyze in-context learning dynamics to understand latent concepts in LLMs underlying behavioral patterns. This provides a more nuanced understanding than success-or-failure evaluation benchmarks, but does not require observing internal activations as a mechanistic interpretation of circuits would. Inspired by the cognitive science of human randomness perception, we use random binary sequences as context and study dynamics of in-context learning by manipulating properties of context data, such as sequence length. In the latest GPT-3.5+ models, we find emergent abilities to generate pseudo-random numbers and learn basic formal languages, with striking in-context learning dynamics where model outputs transition sharply from pseudo-random behaviors to deterministic repetition.
Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task
Oct 13, 2023
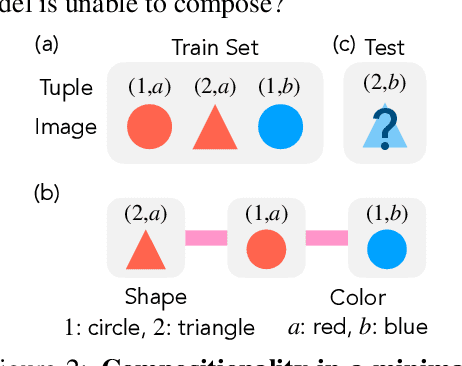
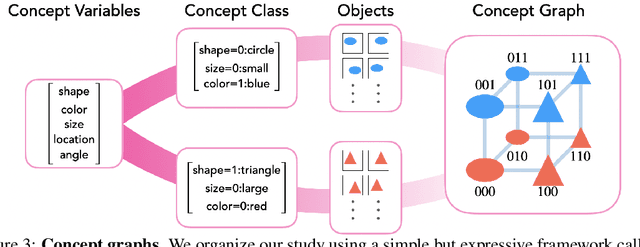
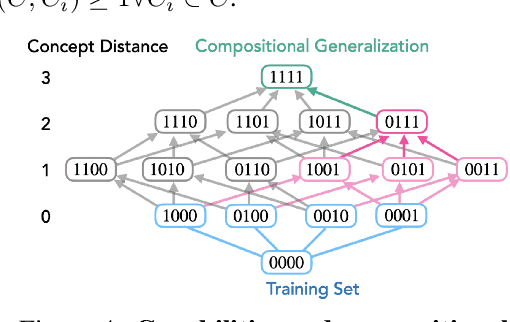
Modern generative models exhibit unprecedented capabilities to generate extremely realistic data. However, given the inherent compositionality of the real world, reliable use of these models in practical applications requires that they exhibit the capability to compose a novel set of concepts to generate outputs not seen in the training data set. Prior work demonstrates that recent diffusion models do exhibit intriguing compositional generalization abilities, but also fail unpredictably. Motivated by this, we perform a controlled study for understanding compositional generalization in conditional diffusion models in a synthetic setting, varying different attributes of the training data and measuring the model's ability to generate samples out-of-distribution. Our results show: (i) the order in which the ability to generate samples from a concept and compose them emerges is governed by the structure of the underlying data-generating process; (ii) performance on compositional tasks exhibits a sudden ``emergence'' due to multiplicative reliance on the performance of constituent tasks, partially explaining emergent phenomena seen in generative models; and (iii) composing concepts with lower frequency in the training data to generate out-of-distribution samples requires considerably more optimization steps compared to generating in-distribution samples. Overall, our study lays a foundation for understanding capabilities and compositionality in generative models from a data-centric perspective.
Mechanistic Mode Connectivity
Nov 15, 2022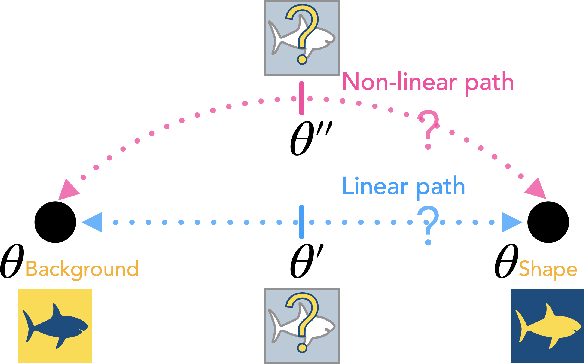
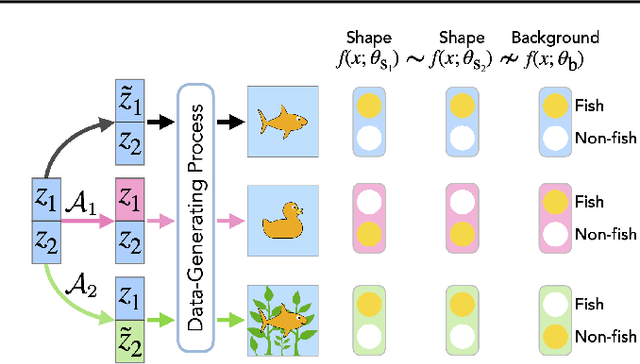
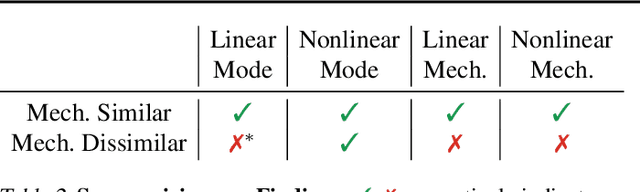
Neural networks are known to be biased towards learning mechanisms that help identify $spurious\, attributes$, yielding features that do not generalize well under distribution shifts. To understand and address this limitation, we study the geometry of neural network loss landscapes through the lens of $mode\, connectivity$, the observation that minimizers of neural networks are connected via simple paths of low loss. Our work addresses two questions: (i) do minimizers that encode dissimilar mechanisms connect via simple paths of low loss? (ii) can fine-tuning a pretrained model help switch between such minimizers? We define a notion of $\textit{mechanistic similarity}$ and demonstrate that lack of linear connectivity between two minimizers implies the corresponding models use dissimilar mechanisms for making their predictions. This property helps us demonstrate that na$\"{i}$ve fine-tuning can fail to eliminate a model's reliance on spurious attributes. We thus propose a method for altering a model's mechanisms, named $connectivity$-$based$ $fine$-$tuning$, and validate its usefulness by inducing models invariant to spurious attributes.
Orchestra: Unsupervised Federated Learning via Globally Consistent Clustering
May 23, 2022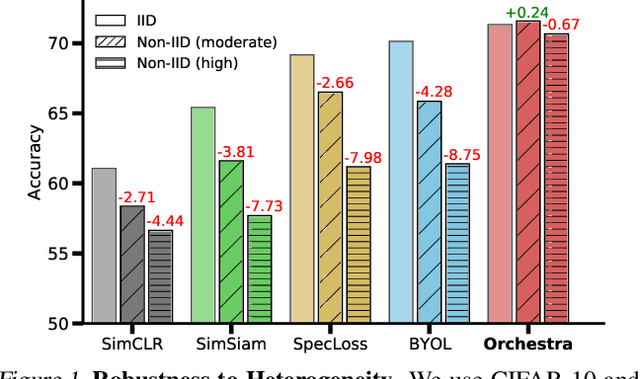
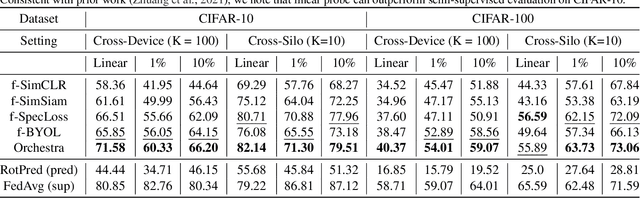
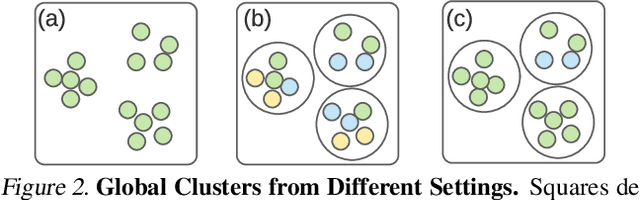
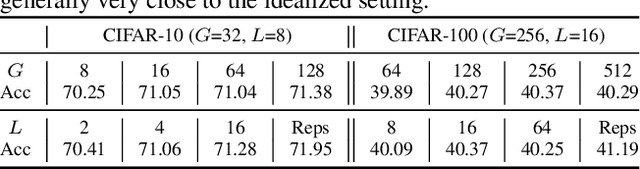
Federated learning is generally used in tasks where labels are readily available (e.g., next word prediction). Relaxing this constraint requires design of unsupervised learning techniques that can support desirable properties for federated training: robustness to statistical/systems heterogeneity, scalability with number of participants, and communication efficiency. Prior work on this topic has focused on directly extending centralized self-supervised learning techniques, which are not designed to have the properties listed above. To address this situation, we propose Orchestra, a novel unsupervised federated learning technique that exploits the federation's hierarchy to orchestrate a distributed clustering task and enforce a globally consistent partitioning of clients' data into discriminable clusters. We show the algorithmic pipeline in Orchestra guarantees good generalization performance under a linear probe, allowing it to outperform alternative techniques in a broad range of conditions, including variation in heterogeneity, number of clients, participation ratio, and local epochs.