 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASER: Activation Smoothing and Error Reconstruction for Large Language Model Quantization
Nov 12, 2024Quantization stands as a pivotal technique for large language model (LLM) serving, yet it poses significant challenges particularly in achieving effective low-bit quantization. The limited numerical mapping makes the quantized model produce a non-trivial error, bringing out intolerable performance degration. This paper is anchored in the basic idea of model compression objectives, and delves into the layer-wise error distribution of LLMs during post-training quantization. Subsequently, we introduce ASER, an algorithm consisting of (1) Error Reconstruction: low-rank compensation for quantization error with LoRA-style matrices constructed by whitening SVD; (2) Activation Smoothing: outlier extraction to gain smooth activation and better error compensation. ASER is capable of quantizing typical LLMs to low-bit ones, particularly preserving accuracy even in W4A8 per-channel setup. Experimental results show that ASER is competitive among the state-of-the-art quantization algorithms, showing potential to activation quantization, with minor overhead.
Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models
May 13, 2024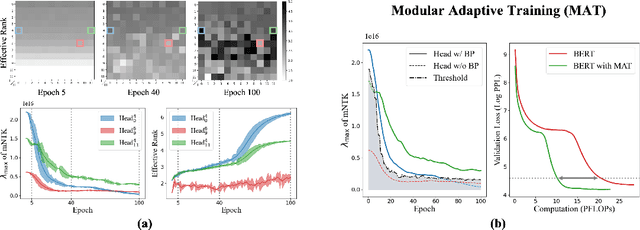

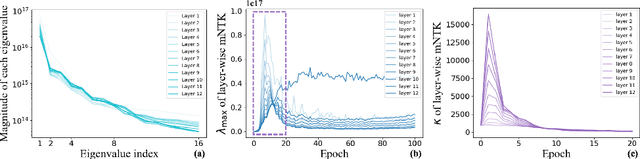

Despite their prevalence in deep-learning communities, over-parameterized models convey high demands of computational costs for proper training. This work studies the fine-grained, modular-level learning dynamics of over-parameterized models to attain a more efficient and fruitful training strategy. Empirical evidence reveals that when scaling down into network modules, such as heads in self-attention models, we can observe varying learning patterns implicitly associated with each module's trainability. To describe such modular-level learning capabilities, we introduce a novel concept dubbed modular neural tangent kernel (mNTK), and we demonstrate that the quality of a module's learning is tightly associated with its mNTK's principal eigenvalue $\lambda_{\max}$. A large $\lambda_{\max}$ indicates that the module learns features with better convergence, while those miniature ones may impact generalization negatively. Inspired by the discovery, we propose a novel training strategy termed Modular Adaptive Training (MAT) to update those modules with their $\lambda_{\max}$ exceeding a dynamic threshold selectively, concentrating the model on learning common features and ignoring those inconsistent ones. Unlike most existing training schemes with a complete BP cycle across all network modules, MAT can significantly save computations by its partially-updating strategy and can further improve performance. Experiments show that MAT nearly halves the computational cost of model training and outperforms the accuracy of baselines.