 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRender-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
Jan 21, 2026Chain-of-Thought (CoT) prompting has achieved remarkable success in unlocking the reasoning capabilities of Large Language Models (LLMs). Although CoT prompting enhances reasoning, its verbosity imposes substantial computational overhead. Recent works often focus exclusively on outcome alignment and lack supervision on the intermediate reasoning process. These deficiencies obscure the analyzability of the latent reasoning chain. To address these challenges, we introduce Render-of-Thought (RoT), the first framework to reify the reasoning chain by rendering textual steps into images, making the latent rationale explicit and traceable. Specifically, we leverage the vision encoders of existing Vision Language Models (VLMs) as semantic anchors to align the vision embeddings with the textual space. This design ensures plug-and-play implementation without incurring additional pre-training overhead. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that our method achieves 3-4x token compression and substantial inference acceleration compared to explicit CoT. Furthermore, it maintains competitive performance against other methods, validating the feasibility of this paradigm. Our code is available at https://github.com/TencentBAC/RoT
SPAN: Spatial-Projection Alignment for Monocular 3D Object Detection
Nov 10, 2025Existing monocular 3D detectors typically tame the pronounced nonlinear regression of 3D bounding box through decoupled prediction paradigm, which employs multiple branches to estimate geometric center, depth, dimensions, and rotation angle separately. Although this decoupling strategy simplifies the learning process, it inherently ignores the geometric collaborative constraints between different attributes, resulting in the lack of geometric consistency prior, thereby leading to suboptimal performance. To address this issue, we propose novel Spatial-Projection Alignment (SPAN) with two pivotal components: (i). Spatial Point Alignment enforces an explicit global spatial constraint between the predicted and ground-truth 3D bounding boxes, thereby rectifying spatial drift caused by decoupled attribute regression. (ii). 3D-2D Projection Alignment ensures that the projected 3D box is aligned tightly within its corresponding 2D detection bounding box on the image plane, mitigating projection misalignment overlooked in previous works. To ensure training stability, we further introduce a Hierarchical Task Learning strategy that progressively incorporates spatial-projection alignment as 3D attribute predictions refine, preventing early stage error propagation across attributes. Extensive experiments demonstrate that the proposed method can be easily integrated into any established monocular 3D detector and delivers significant performance improvements.
Data-Efficient Fine-Tuning of Vision-Language Models for Diagnosis of Alzheimer's Disease
Sep 09, 2025Medical vision-language models (Med-VLMs) have shown impressive results in tasks such as report generation and visual question answering, but they still face several limitations. Most notably, they underutilize patient metadata and lack integration of clinical diagnostic knowledge. Moreover, most existing models are typically trained from scratch or fine-tuned on large-scale 2D image-text pairs, requiring extensive computational resources, and their effectiveness on 3D medical imaging is often limited due to the absence of structural information. To address these gaps, we propose a data-efficient fine-tuning pipeline to adapt 3D CT-based Med-VLMs for 3D MRI and demonstrate its application in Alzheimer's disease (AD) diagnosis. Our system introduces two key innovations. First, we convert structured metadata into synthetic reports, enriching textual input for improved image-text alignment. Second, we add an auxiliary token trained to predict the mini-mental state examination (MMSE) score, a widely used clinical measure of cognitive function that correlates with AD severity. This provides additional supervision for fine-tuning. Applying lightweight prompt tuning to both image and text modalities, our approach achieves state-of-the-art performance on two AD datasets using 1,500 training images, outperforming existing methods fine-tuned on 10,000 images. Code will be released upon publication.
Self-Supervised Cross-Encoder for Neurodegenerative Disease Diagnosis
Sep 09, 2025


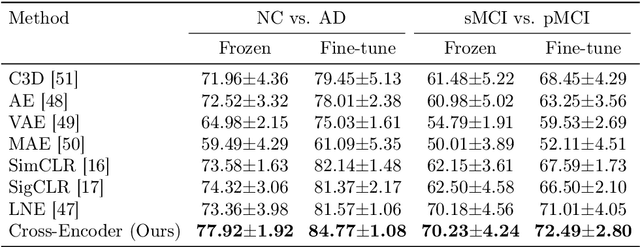
Deep learning has shown significant potential in diagnosing neurodegenerative diseases from MRI data. However, most existing methods rely heavily on large volumes of labeled data and often yield representations that lack interpretability. To address both challenges, we propose a novel self-supervised cross-encoder framework that leverages the temporal continuity in longitudinal MRI scans for supervision. This framework disentangles learned representations into two components: a static representation, constrained by contrastive learning, which captures stable anatomical features; and a dynamic representation, guided by input-gradient regularization, which reflects temporal changes and can be effectively fine-tuned for downstream classification tasks. Experimental results on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate that our method achieves superior classification accuracy and improved interpretability. Furthermore, the learned representations exhibit strong zero-shot generalization on the Open Access Series of Imaging Studies (OASIS) dataset and cross-task generalization on the Parkinson Progression Marker Initiative (PPMI) dataset. The code for the proposed method will be made publicly available.
Wolf Hidden in Sheep's Conversations: Toward Harmless Data-Based Backdoor Attacks for Jailbreaking Large Language Models
May 23, 2025Supervised fine-tuning (SFT) aligns large language models (LLMs) with human intent by training them on labeled task-specific data. Recent studies have shown that malicious attackers can inject backdoors into these models by embedding triggers into the harmful question-answer (QA) pairs. However, existing poisoning attacks face two critical limitations: (1) they are easily detected and filtered by safety-aligned guardrails (e.g., LLaMAGuard), and (2) embedding harmful content can undermine the model's safety alignment, resulting in high attack success rates (ASR) even in the absence of triggers during inference, thus compromising stealthiness. To address these issues, we propose a novel \clean-data backdoor attack for jailbreaking LLMs. Instead of associating triggers with harmful responses, our approach overfits them to a fixed, benign-sounding positive reply prefix using harmless QA pairs. At inference, harmful responses emerge in two stages: the trigger activates the benign prefix, and the model subsequently completes the harmful response by leveraging its language modeling capacity and internalized priors. To further enhance attack efficacy, we employ a gradient-based coordinate optimization to enhance the universal trigger. Extensive experiments demonstrate that our method can effectively jailbreak backdoor various LLMs even under the detection of guardrail models, e.g., an ASR of 86.67% and 85% on LLaMA-3-8B and Qwen-2.5-7B judged by GPT-4o.
PathoSCOPE: Few-Shot Pathology Detection via Self-Supervised Contrastive Learning and Pathology-Informed Synthetic Embeddings
May 23, 2025Unsupervised pathology detection trains models on non-pathological data to flag deviations as pathologies, offering strong generalizability for identifying novel diseases and avoiding costly annotations. However, building reliable normality models requires vast healthy datasets, as hospitals' data is inherently biased toward symptomatic populations, while privacy regulations hinder the assembly of representative healthy cohorts. To address this limitation, we propose PathoSCOPE, a few-shot unsupervised pathology detection framework that requires only a small set of non-pathological samples (minimum 2 shots), significantly improving data efficiency. We introduce Global-Local Contrastive Loss (GLCL), comprised of a Local Contrastive Loss to reduce the variability of non-pathological embeddings and a Global Contrastive Loss to enhance the discrimination of pathological regions. We also propose a Pathology-informed Embedding Generation (PiEG) module that synthesizes pathological embeddings guided by the global loss, better exploiting the limited non-pathological samples. Evaluated on the BraTS2020 and ChestXray8 datasets, PathoSCOPE achieves state-of-the-art performance among unsupervised methods while maintaining computational efficiency (2.48 GFLOPs, 166 FPS).
VISTA: Unsupervised 2D Temporal Dependency Representations for Time Series Anomaly Detection
Apr 03, 2025Time Series Anomaly Detection (TSAD) is essential for uncovering rare and potentially harmful events in unlabeled time series data. Existing methods are highly dependent on clean, high-quality inputs, making them susceptible to noise and real-world imperfections. Additionally, intricate temporal relationships in time series data are often inadequately captured in traditional 1D representations, leading to suboptimal modeling of dependencies. We introduce VISTA, a training-free, unsupervised TSAD algorithm designed to overcome these challenges. VISTA features three core modules: 1) Time Series Decomposition using Seasonal and Trend Decomposition via Loess (STL) to decompose noisy time series into trend, seasonal, and residual components; 2) Temporal Self-Attention, which transforms 1D time series into 2D temporal correlation matrices for richer dependency modeling and anomaly detection; and 3) Multivariate Temporal Aggregation, which uses a pretrained feature extractor to integrate cross-variable information into a unified, memory-efficient representation. VISTA's training-free approach enables rapid deployment and easy hyperparameter tuning, making it suitable for industrial applications. It achieves state-of-the-art performance on five multivariate TSAD benchmarks.
MAP-based Problem-Agnostic diffusion model for Inverse Problems
Jan 25, 2025



Diffusion models have indeed shown great promise in solving inverse problems in image processing. In this paper, we propose a novel, problem-agnostic diffusion model called the maximum a posteriori (MAP)-based guided term estimation method for inverse problems. We divide the conditional score function into two terms according to Bayes' rule: the unconditional score function and the guided term. We design the MAP-based guided term estimation method, while the unconditional score function is approximated by an existing score network. To estimate the guided term, we base on the assumption that the space of clean natural images is inherently smooth, and introduce a MAP estimate of the $t$-th latent variable. We then substitute this estimation into the expression of the inverse problem and obtain the approximation of the guided term. We evaluate our method extensively on super-resolution, inpainting, and denoising tasks, and demonstrate comparable performance to DDRM, DMPS, DPS and $\Pi$GDM.
COMO: Cross-Mamba Interaction and Offset-Guided Fusion for Multimodal Object Detection
Dec 24, 2024Single-modal object detection tasks often experience performance degradation when encountering diverse scenarios. In contrast, multimodal object detection tasks can offer more comprehensive information about object features by integrating data from various modalities. Current multimodal object detection methods generally use various fusion techniques, including conventional neural networks and transformer-based models, to implement feature fusion strategies and achieve complementary information. However, since multimodal images are captured by different sensors, there are often misalignments between them, making direct matching challenging. This misalignment hinders the ability to establish strong correlations for the same object across different modalities. In this paper, we propose a novel approach called the CrOss-Mamba interaction and Offset-guided fusion (COMO) framework for multimodal object detection tasks. The COMO framework employs the cross-mamba technique to formulate feature interaction equations, enabling multimodal serialized state computation. This results in interactive fusion outputs while reducing computational overhead and improving efficiency. Additionally, COMO leverages high-level features, which are less affected by misalignment, to facilitate interaction and transfer complementary information between modalities, addressing the positional offset challenges caused by variations in camera angles and capture times. Furthermore, COMO incorporates a global and local scanning mechanism in the cross-mamba module to capture features with local correlation, particularly in remote sensing images. To preserve low-level features, the offset-guided fusion mechanism ensures effective multiscale feature utilization, allowing the construction of a multiscale fusion data cube that enhances detection performance.
Efficient Feature Aggregation and Scale-Aware Regression for Monocular 3D Object Detection
Nov 05, 2024



Monocular 3D object detection has attracted great attention due to simplicity and low cost. Existing methods typically follow conventional 2D detection paradigms, first locating object centers and then predicting 3D attributes via neighboring features. However, these methods predominantly rely on progressive cross-scale feature aggregation and focus solely on local information, which may result in a lack of global awareness and the omission of small-scale objects. In addition, due to large variation in object scales across different scenes and depths, inaccurate receptive fields often lead to background noise and degraded feature representation. To address these issues, we introduces MonoASRH, a novel monocular 3D detection framework composed of Efficient Hybrid Feature Aggregation Module (EH-FAM) and Adaptive Scale-Aware 3D Regression Head (ASRH). Specifically, EH-FAM employs multi-head attention with a global receptive field to extract semantic features for small-scale objects and leverages lightweight convolutional modules to efficiently aggregate visual features across different scales. The ASRH encodes 2D bounding box dimensions and then fuses scale features with the semantic features aggregated by EH-FAM through a scale-semantic feature fusion module. The scale-semantic feature fusion module guides ASRH in learning dynamic receptive field offsets, incorporating scale priors into 3D position prediction for better scale-awareness. Extensive experiments on the KITTI and Waymo datasets demonstrate that MonoASRH achieves state-of-the-art performance.