 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubject-Aware Multi-Granularity Alignment for Zero-Shot EEG-to-Image Retrieval
Apr 20, 2026Zero-shot EEG-to-image retrieval aims to decode perceived visual content from electroencephalography (EEG) by aligning neural responses with pretrained visual representations, providing a promising route toward scalable visual neural decoding and practical brain-computer interfaces. However, robust EEG-to-image retrieval remains challenging, because prior methods usually rely on either a single fixed visual target or a subject-invariant target construction scheme. Such designs overlook two important properties of visually evoked EEG signals: they preserve information across multiple representational scales, and the visual granularity best matched to EEG may vary across subjects. To address these issues, subject-aware multi-granularity alignment (SAMGA) framework is proposed for zero-shot EEG-to-image retrieval. SAMGA first constructs a subject-aware visual supervision target by adaptively aggregating multiple intermediate representations from a pretrained vision encoder, allowing the model to absorb subject-dependent granularity deviations during training while preserving subject-agnostic inference. Building on this adaptive target construction, a coarse-to-fine cross-modal alignment strategy is further designed with a shared encoder wherein the coarse stage stabilizes the shared semantic geometry and reduces subject-induced distribution shift, and the fine stage further improves instance-level retrieval discrimination. Extensive experiments on the THINGS-EEG benchmark demonstrate that the proposed method achieves 91.3% Top-1 and 98.8% Top-5 accuracy in the intra-subject setting, and 34.4% Top-1 and 64.8% Top-5 accuracy in the inter-subject setting, outperforming recent state-of-the-art methods.
FedAFD: Multimodal Federated Learning via Adversarial Fusion and Distillation
Mar 05, 2026Multimodal Federated Learning (MFL) enables clients with heterogeneous data modalities to collaboratively train models without sharing raw data, offering a privacy-preserving framework that leverages complementary cross-modal information. However, existing methods often overlook personalized client performance and struggle with modality/task discrepancies, as well as model heterogeneity. To address these challenges, we propose FedAFD, a unified MFL framework that enhances client and server learning. On the client side, we introduce a bi-level adversarial alignment strategy to align local and global representations within and across modalities, mitigating modality and task gaps. We further design a granularity-aware fusion module to integrate global knowledge into the personalized features adaptively. On the server side, to handle model heterogeneity, we propose a similarity-guided ensemble distillation mechanism that aggregates client representations on shared public data based on feature similarity and distills the fused knowledge into the global model. Extensive experiments conducted under both IID and non-IID settings demonstrate that FedAFD achieves superior performance and efficiency for both the client and the server.
SR3R: Rethinking Super-Resolution 3D Reconstruction With Feed-Forward Gaussian Splatting
Feb 27, 20263D super-resolution (3DSR) aims to reconstruct high-resolution (HR) 3D scenes from low-resolution (LR) multi-view images. Existing methods rely on dense LR inputs and per-scene optimization, which restricts the high-frequency priors for constructing HR 3D Gaussian Splatting (3DGS) to those inherited from pretrained 2D super-resolution (2DSR) models. This severely limits reconstruction fidelity, cross-scene generalization, and real-time usability. We propose to reformulate 3DSR as a direct feed-forward mapping from sparse LR views to HR 3DGS representations, enabling the model to autonomously learn 3D-specific high-frequency geometry and appearance from large-scale, multi-scene data. This fundamentally changes how 3DSR acquires high-frequency knowledge and enables robust generalization to unseen scenes. Specifically, we introduce SR3R, a feed-forward framework that directly predicts HR 3DGS representations from sparse LR views via the learned mapping network. To further enhance reconstruction fidelity, we introduce Gaussian offset learning and feature refinement, which stabilize reconstruction and sharpen high-frequency details. SR3R is plug-and-play and can be paired with any feed-forward 3DGS reconstruction backbone: the backbone provides an LR 3DGS scaffold, and SR3R upscales it to an HR 3DGS. Extensive experiments across three 3D benchmarks demonstrate that SR3R surpasses state-of-the-art (SOTA) 3DSR methods and achieves strong zero-shot generalization, even outperforming SOTA per-scene optimization methods on unseen scenes.
Facial Identity Anonymization via Intrinsic and Extrinsic Attention Distraction
Jun 25, 2024
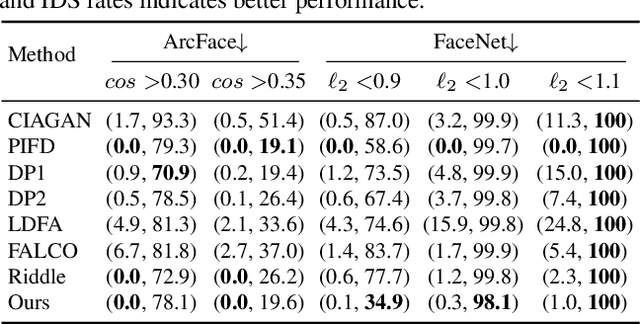


The unprecedented capture and application of face images raise increasing concerns on anonymization to fight against privacy disclosure. Most existing methods may suffer from the problem of excessive change of the identity-independent information or insufficient identity protection. In this paper, we present a new face anonymization approach by distracting the intrinsic and extrinsic identity attentions. On the one hand, we anonymize the identity information in the feature space by distracting the intrinsic identity attention. On the other, we anonymize the visual clues (i.e. appearance and geometry structure) by distracting the extrinsic identity attention. Our approach allows for flexible and intuitive manipulation of face appearance and geometry structure to produce diverse results, and it can also be used to instruct users to perform personalized anonymization. We conduct extensive experiments on multiple datasets and demonstrate that our approach outperforms state-of-the-art methods.
SRGS: Super-Resolution 3D Gaussian Splatting
Apr 16, 2024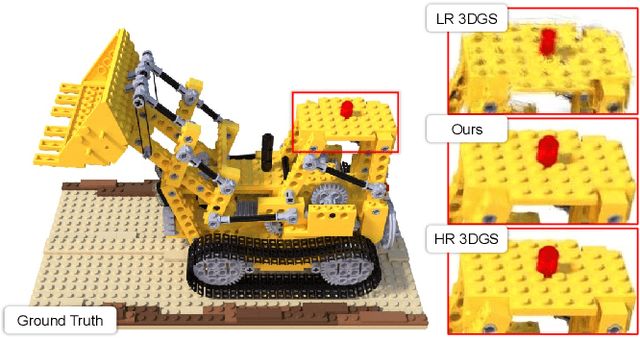
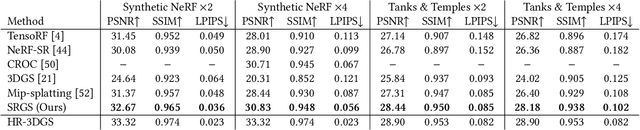
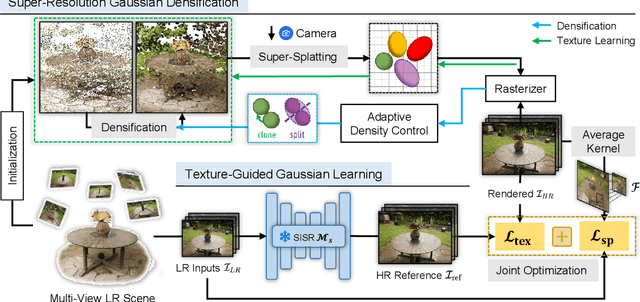
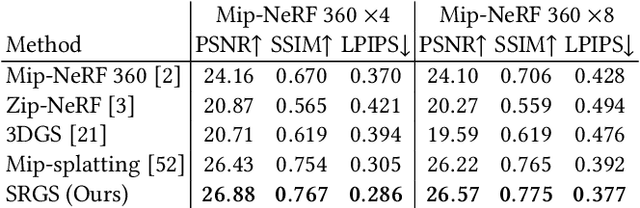
Recently, 3D Gaussian Splatting (3DGS) has gained popularity as a novel explicit 3D representation. This approach relies on the representation power of Gaussian primitives to provide a high-quality rendering. However, primitives optimized at low resolution inevitably exhibit sparsity and texture deficiency, posing a challenge for achieving high-resolution novel view synthesis (HRNVS). To address this problem, we propose Super-Resolution 3D Gaussian Splatting (SRGS) to perform the optimization in a high-resolution (HR) space. The sub-pixel constraint is introduced for the increased viewpoints in HR space, exploiting the sub-pixel cross-view information of the multiple low-resolution (LR) views. The gradient accumulated from more viewpoints will facilitate the densification of primitives. Furthermore, a pre-trained 2D super-resolution model is integrated with the sub-pixel constraint, enabling these dense primitives to learn faithful texture features. In general, our method focuses on densification and texture learning to effectively enhance the representation ability of primitives. Experimentally, our method achieves high rendering quality on HRNVS only with LR inputs, outperforming state-of-the-art methods on challenging datasets such as Mip-NeRF 360 and Tanks & Temples. Related codes will be released upon acceptance.
ZS-SRT: An Efficient Zero-Shot Super-Resolution Training Method for Neural Radiance Fields
Dec 19, 2023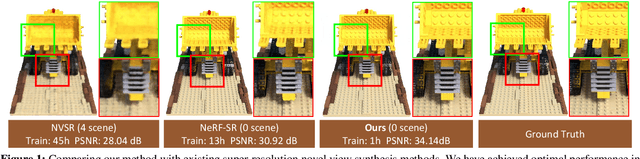
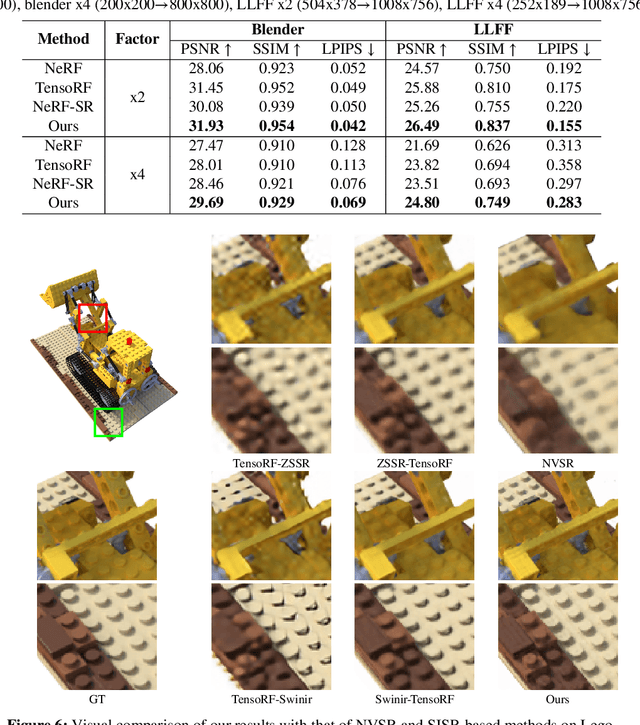
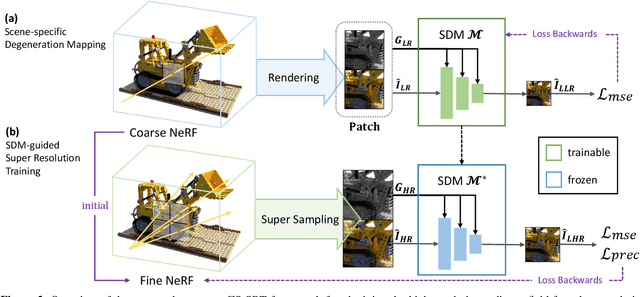
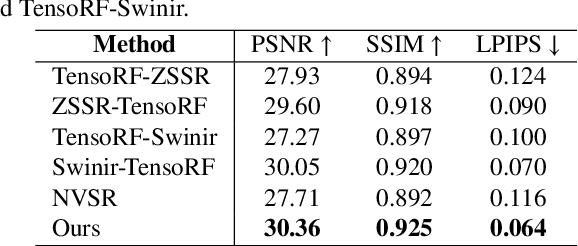
Neural Radiance Fields (NeRF) have achieved great success in the task of synthesizing novel views that preserve the same resolution as the training views. However, it is challenging for NeRF to synthesize high-quality high-resolution novel views with low-resolution training data. To solve this problem, we propose a zero-shot super-resolution training framework for NeRF. This framework aims to guide the NeRF model to synthesize high-resolution novel views via single-scene internal learning rather than requiring any external high-resolution training data. Our approach consists of two stages. First, we learn a scene-specific degradation mapping by performing internal learning on a pretrained low-resolution coarse NeRF. Second, we optimize a super-resolution fine NeRF by conducting inverse rendering with our mapping function so as to backpropagate the gradients from low-resolution 2D space into the super-resolution 3D sampling space. Then, we further introduce a temporal ensemble strategy in the inference phase to compensate for the scene estimation errors. Our method is featured on two points: (1) it does not consume high-resolution views or additional scene data to train super-resolution NeRF; (2) it can speed up the training process by adopting a coarse-to-fine strategy. By conducting extensive experiments on public datasets, we have qualitatively and quantitatively demonstrated the effectiveness of our method.
Self-supervised Learning of Rotation-invariant 3D Point Set Features using Transformer and its Self-distillation
Aug 09, 2023Invariance against rotations of 3D objects is an important property in analyzing 3D point set data. Conventional 3D point set DNNs having rotation invariance typically obtain accurate 3D shape features via supervised learning by using labeled 3D point sets as training samples. However, due to the rapid increase in 3D point set data and the high cost of labeling, a framework to learn rotation-invariant 3D shape features from numerous unlabeled 3D point sets is required. This paper proposes a novel self-supervised learning framework for acquiring accurate and rotation-invariant 3D point set features at object-level. Our proposed lightweight DNN architecture decomposes an input 3D point set into multiple global-scale regions, called tokens, that preserve the spatial layout of partial shapes composing the 3D object. We employ a self-attention mechanism to refine the tokens and aggregate them into an expressive rotation-invariant feature per 3D point set. Our DNN is effectively trained by using pseudo-labels generated by a self-distillation framework. To facilitate the learning of accurate features, we propose to combine multi-crop and cut-mix data augmentation techniques to diversify 3D point sets for training. Through a comprehensive evaluation, we empirically demonstrate that, (1) existing rotation-invariant DNN architectures designed for supervised learning do not necessarily learn accurate 3D shape features under a self-supervised learning scenario, and (2) our proposed algorithm learns rotation-invariant 3D point set features that are more accurate than those learned by existing algorithms. Code will be available at https://github.com/takahikof/RIPT_SDMM
Deep Mixture of Diverse Experts for Large-Scale Visual Recognition
Jun 24, 2017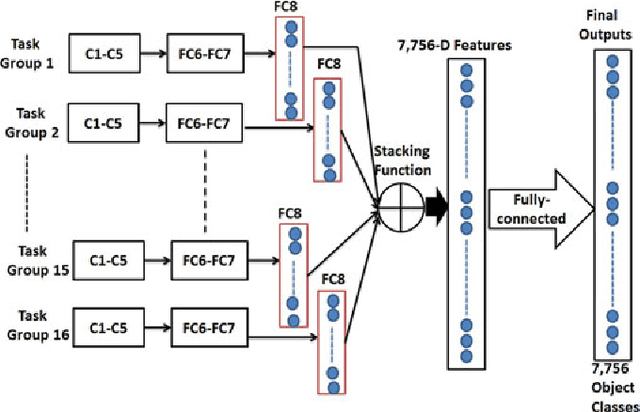
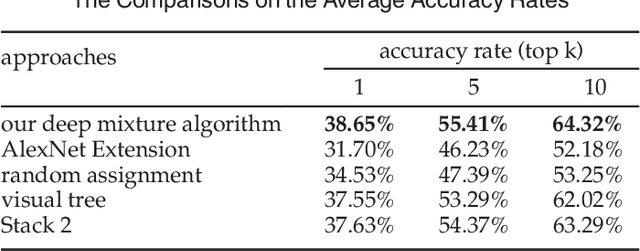
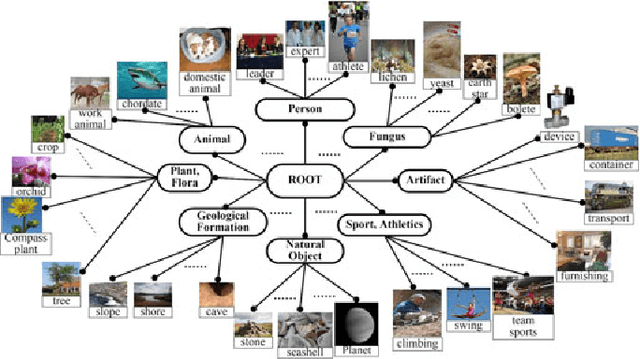
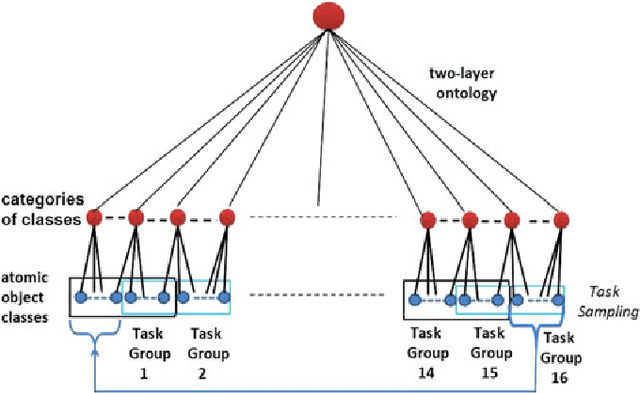
In this paper, a deep mixture of diverse experts algorithm is developed for seamlessly combining a set of base deep CNNs (convolutional neural networks) with diverse outputs (task spaces), e.g., such base deep CNNs are trained to recognize different subsets of tens of thousands of atomic object classes. First, a two-layer (category layer and object class layer) ontology is constructed to achieve more effective solution for task group generation, e.g., assigning the semantically-related atomic object classes at the sibling leaf nodes into the same task group because they may share similar learning complexities. Second, one particular base deep CNNs with $M+1$ ($M \leq 1,000$) outputs is learned for each task group to recognize its $M$ atomic object classes effectively and identify one special class of "not-in-group" automatically, and the network structure (numbers of layers and units in each layer) of the well-designed AlexNet is directly used to configure such base deep CNNs. A deep multi-task learning algorithm is developed to leverage the inter-class visual similarities to learn more discriminative base deep CNNs and multi-task softmax for enhancing the separability of the atomic object classes in the same task group. Finally, all these base deep CNNs with diverse outputs (task spaces) are seamlessly combined to form a deep mixture of diverse experts for recognizing tens of thousands of atomic object classes. Our experimental results have demonstrated that our deep mixture of diverse experts algorithm can achieve very competitive results on large-scale visual recognition.