 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
GenSmoke-GS: A Multi-Stage Method for Novel View Synthesis from Smoke-Degraded Images Using a Generative Model
Apr 03, 2026This paper describes our method for Track 2 of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge on smoke-degraded images. In this task, smoke reduces image visibility and weakens the cross-view consistency required by scene optimization and rendering. We address this problem with a multi-stage pipeline consisting of image restoration, dehazing, MLLM-based enhancement, 3DGS-MCMC optimization, and averaging over repeated runs. The main purpose of the pipeline is to improve visibility before rendering while limiting scene-content changes across input views. Experimental results on the challenge benchmark show improved quantitative performance and better visual quality than the provided baselines. The code is available at https://github.com/plbbl/GenSmoke-GS. Our method achieved a ranking of 1 out of 14 participants in Track 2 of the NTIRE 3DRR Challenge, as reported on the official competition website: https://www.codabench.org/competitions/13993/#/results-tab.
FedAFD: Multimodal Federated Learning via Adversarial Fusion and Distillation
Mar 05, 2026Multimodal Federated Learning (MFL) enables clients with heterogeneous data modalities to collaboratively train models without sharing raw data, offering a privacy-preserving framework that leverages complementary cross-modal information. However, existing methods often overlook personalized client performance and struggle with modality/task discrepancies, as well as model heterogeneity. To address these challenges, we propose FedAFD, a unified MFL framework that enhances client and server learning. On the client side, we introduce a bi-level adversarial alignment strategy to align local and global representations within and across modalities, mitigating modality and task gaps. We further design a granularity-aware fusion module to integrate global knowledge into the personalized features adaptively. On the server side, to handle model heterogeneity, we propose a similarity-guided ensemble distillation mechanism that aggregates client representations on shared public data based on feature similarity and distills the fused knowledge into the global model. Extensive experiments conducted under both IID and non-IID settings demonstrate that FedAFD achieves superior performance and efficiency for both the client and the server.
VideoARM: Agentic Reasoning over Hierarchical Memory for Long-Form Video Understanding
Dec 13, 2025



Long-form video understanding remains challenging due to the extended temporal structure and dense multimodal cues. Despite recent progress, many existing approaches still rely on hand-crafted reasoning pipelines or employ token-consuming video preprocessing to guide MLLMs in autonomous reasoning. To overcome these limitations, we introduce VideoARM, an Agentic Reasoning-over-hierarchical-Memory paradigm for long-form video understanding. Instead of static, exhaustive preprocessing, VideoARM performs adaptive, on-the-fly agentic reasoning and memory construction. Specifically, VideoARM performs an adaptive and continuous loop of observing, thinking, acting, and memorizing, where a controller autonomously invokes tools to interpret the video in a coarse-to-fine manner, thereby substantially reducing token consumption. In parallel, a hierarchical multimodal memory continuously captures and updates multi-level clues throughout the operation of the agent, providing precise contextual information to support the controller in decision-making. Experiments on prevalent benchmarks demonstrate that VideoARM outperforms the state-of-the-art method, DVD, while significantly reducing token consumption for long-form videos.
SRSplat: Feed-Forward Super-Resolution Gaussian Splatting from Sparse Multi-View Images
Nov 15, 2025Feed-forward 3D reconstruction from sparse, low-resolution (LR) images is a crucial capability for real-world applications, such as autonomous driving and embodied AI. However, existing methods often fail to recover fine texture details. This limitation stems from the inherent lack of high-frequency information in LR inputs. To address this, we propose \textbf{SRSplat}, a feed-forward framework that reconstructs high-resolution 3D scenes from only a few LR views. Our main insight is to compensate for the deficiency of texture information by jointly leveraging external high-quality reference images and internal texture cues. We first construct a scene-specific reference gallery, generated for each scene using Multimodal Large Language Models (MLLMs) and diffusion models. To integrate this external information, we introduce the \textit{Reference-Guided Feature Enhancement (RGFE)} module, which aligns and fuses features from the LR input images and their reference twin image. Subsequently, we train a decoder to predict the Gaussian primitives using the multi-view fused feature obtained from \textit{RGFE}. To further refine predicted Gaussian primitives, we introduce \textit{Texture-Aware Density Control (TADC)}, which adaptively adjusts Gaussian density based on the internal texture richness of the LR inputs. Extensive experiments demonstrate that our SRSplat outperforms existing methods on various datasets, including RealEstate10K, ACID, and DTU, and exhibits strong cross-dataset and cross-resolution generalization capabilities.
Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
Nov 10, 2025



Dynamic Gaussian Splatting approaches have achieved remarkable performance for 4D scene reconstruction. However, these approaches rely on dense-frame video sequences for photorealistic reconstruction. In real-world scenarios, due to equipment constraints, sometimes only sparse frames are accessible. In this paper, we propose Sparse4DGS, the first method for sparse-frame dynamic scene reconstruction. We observe that dynamic reconstruction methods fail in both canonical and deformed spaces under sparse-frame settings, especially in areas with high texture richness. Sparse4DGS tackles this challenge by focusing on texture-rich areas. For the deformation network, we propose Texture-Aware Deformation Regularization, which introduces a texture-based depth alignment loss to regulate Gaussian deformation. For the canonical Gaussian field, we introduce Texture-Aware Canonical Optimization, which incorporates texture-based noise into the gradient descent process of canonical Gaussians. Extensive experiments show that when taking sparse frames as inputs, our method outperforms existing dynamic or few-shot techniques on NeRF-Synthetic, HyperNeRF, NeRF-DS, and our iPhone-4D datasets.
LymphAtlas- A Unified Multimodal Lymphoma Imaging Repository Delivering AI-Enhanced Diagnostic Insight
Apr 29, 2025This study integrates PET metabolic information with CT anatomical structures to establish a 3D multimodal segmentation dataset for lymphoma based on whole-body FDG PET/CT examinations, which bridges the gap of the lack of standardised multimodal segmentation datasets in the field of haematological malignancies. We retrospectively collected 483 examination datasets acquired between March 2011 and May 2024, involving 220 patients (106 non-Hodgkin lymphoma, 42 Hodgkin lymphoma); all data underwent ethical review and were rigorously de-identified. Complete 3D structural information was preserved during data acquisition, preprocessing and annotation, and a high-quality dataset was constructed based on the nnUNet format. By systematic technical validation and evaluation of the preprocessing process, annotation quality and automatic segmentation algorithm, the deep learning model trained based on this dataset is verified to achieve accurate segmentation of lymphoma lesions in PET/CT images with high accuracy, good robustness and reproducibility, which proves the applicability and stability of this dataset in accurate segmentation and quantitative analysis. The deep fusion of PET/CT images achieved with this dataset not only significantly improves the accurate portrayal of the morphology, location and metabolic features of tumour lesions, but also provides solid data support for early diagnosis, clinical staging and personalized treatment, and promotes the development of automated image segmentation and precision medicine based on deep learning. The dataset and related resources are available at https://github.com/SuperD0122/LymphAtlas-.
PINN-EMFNet: PINN-based and Enhanced Multi-Scale Feature Fusion Network for Breast Ultrasound Images Segmentation
Dec 22, 2024



With the rapid development of deep learning and computer vision technologies, medical image segmentation plays a crucial role in the early diagnosis of breast cancer. However, due to the characteristics of breast ultrasound images, such as low contrast, speckle noise, and the highly diverse morphology of tumors, existing segmentation methods exhibit significant limitations in terms of accuracy and robustness. To address these challenges, this study proposes a PINN-based and Enhanced Multi-Scale Feature Fusion Network. The network introduces a Hierarchical Aggregation Encoder in the backbone, which efficiently integrates and globally models multi-scale features through several structural innovations and a novel PCAM module. In the decoder section, a Multi-Scale Feature Refinement Decoder is employed, which, combined with a Multi-Scale Supervision Mechanism and a correction module, significantly improves segmentation accuracy and adaptability. Additionally, the loss function incorporating the PINN mechanism introduces physical constraints during the segmentation process, enhancing the model's ability to accurately delineate tumor boundaries. Comprehensive evaluations on two publicly available breast ultrasound datasets, BUSIS and BUSI, demonstrate that the proposed method outperforms previous segmentation approaches in terms of segmentation accuracy and robustness, particularly under conditions of complex noise and low contrast, effectively improving the accuracy and reliability of tumor segmentation. This method provides a more precise and robust solution for computer-aided diagnosis of breast ultrasound images.
Imp: Highly Capable Large Multimodal Models for Mobile Devices
May 20, 2024By harnessing the capabilities of large language models (LLMs), recent large multimodal models (LMMs) have shown remarkable versatility in open-world multimodal understanding. Nevertheless, they are usually parameter-heavy and computation-intensive, thus hindering their applicability in resource-constrained scenarios. To this end, several lightweight LMMs have been proposed successively to maximize the capabilities under constrained scale (e.g., 3B). Despite the encouraging results achieved by these methods, most of them only focus on one or two aspects of the design space, and the key design choices that influence model capability have not yet been thoroughly investigated. In this paper, we conduct a systematic study for lightweight LMMs from the aspects of model architecture, training strategy, and training data. Based on our findings, we obtain Imp -- a family of highly capable LMMs at the 2B-4B scales. Notably, our Imp-3B model steadily outperforms all the existing lightweight LMMs of similar size, and even surpasses the state-of-the-art LMMs at the 13B scale. With low-bit quantization and resolution reduction techniques, our Imp model can be deployed on a Qualcomm Snapdragon 8Gen3 mobile chip with a high inference speed of about 13 tokens/s.
ZS-SRT: An Efficient Zero-Shot Super-Resolution Training Method for Neural Radiance Fields
Dec 19, 2023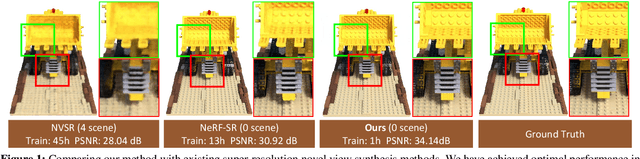
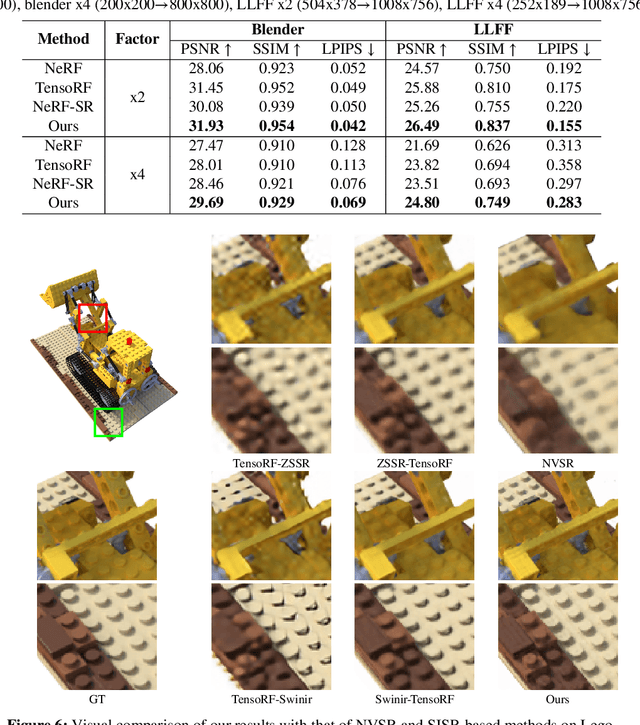
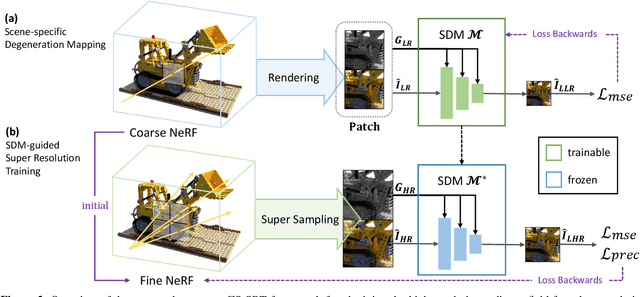
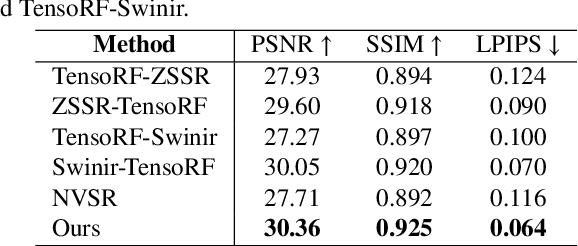
Neural Radiance Fields (NeRF) have achieved great success in the task of synthesizing novel views that preserve the same resolution as the training views. However, it is challenging for NeRF to synthesize high-quality high-resolution novel views with low-resolution training data. To solve this problem, we propose a zero-shot super-resolution training framework for NeRF. This framework aims to guide the NeRF model to synthesize high-resolution novel views via single-scene internal learning rather than requiring any external high-resolution training data. Our approach consists of two stages. First, we learn a scene-specific degradation mapping by performing internal learning on a pretrained low-resolution coarse NeRF. Second, we optimize a super-resolution fine NeRF by conducting inverse rendering with our mapping function so as to backpropagate the gradients from low-resolution 2D space into the super-resolution 3D sampling space. Then, we further introduce a temporal ensemble strategy in the inference phase to compensate for the scene estimation errors. Our method is featured on two points: (1) it does not consume high-resolution views or additional scene data to train super-resolution NeRF; (2) it can speed up the training process by adopting a coarse-to-fine strategy. By conducting extensive experiments on public datasets, we have qualitatively and quantitatively demonstrated the effectiveness of our method.