 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGC: Compositional Grounded Contrast for Fine-Grained Multi-Image Understanding
Apr 24, 2026Although Multimodal Large Language Models (MLLMs) have advanced rapidly, they still face notable challenges in fine-grained multi-image understanding, often exhibiting spatial hallucination, attention leakage, and failures in object constancy. In addition, existing approaches typically rely on expensive human annotations or large-scale chain-of-thought (CoT) data generation. We propose Compositional Grounded Contrast (abbr. CGC), a low-cost full framework for boosting fine-grained multi-image understanding of MLLMs. Built on existing single-image grounding annotations, CGC constructs compositional multi-image training instances through Inter-Image Contrast and Intra-Image Contrast, which introduce semantically decoupled distractor contexts for cross-image discrimination and correlated cross-view samples for object constancy, respectively. CGC further introduces a Rule-Based Spatial Reward within the GRPO framework to improve source-image attribution, spatial alignment, and structured output validity under a Think-before-Grounding paradigm. Experiments show that CGC achieves state-of-the-art results on fine-grained multi-image benchmarks, including MIG-Bench and VLM2-Bench. The learned multi-image understanding capability also transfers to broader multimodal understanding and reasoning tasks, yielding consistent gains over the Qwen3-VL-8B base model on MathVista (+2.90), MuirBench (+2.88), MMStar (+1.93), MMMU (+1.77), and BLINK (+1.69).
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
VideoARM: Agentic Reasoning over Hierarchical Memory for Long-Form Video Understanding
Dec 13, 2025



Long-form video understanding remains challenging due to the extended temporal structure and dense multimodal cues. Despite recent progress, many existing approaches still rely on hand-crafted reasoning pipelines or employ token-consuming video preprocessing to guide MLLMs in autonomous reasoning. To overcome these limitations, we introduce VideoARM, an Agentic Reasoning-over-hierarchical-Memory paradigm for long-form video understanding. Instead of static, exhaustive preprocessing, VideoARM performs adaptive, on-the-fly agentic reasoning and memory construction. Specifically, VideoARM performs an adaptive and continuous loop of observing, thinking, acting, and memorizing, where a controller autonomously invokes tools to interpret the video in a coarse-to-fine manner, thereby substantially reducing token consumption. In parallel, a hierarchical multimodal memory continuously captures and updates multi-level clues throughout the operation of the agent, providing precise contextual information to support the controller in decision-making. Experiments on prevalent benchmarks demonstrate that VideoARM outperforms the state-of-the-art method, DVD, while significantly reducing token consumption for long-form videos.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Growing a Twig to Accelerate Large Vision-Language Models
Mar 18, 2025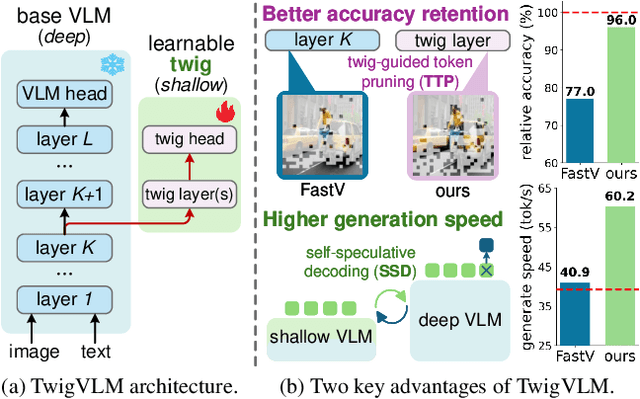
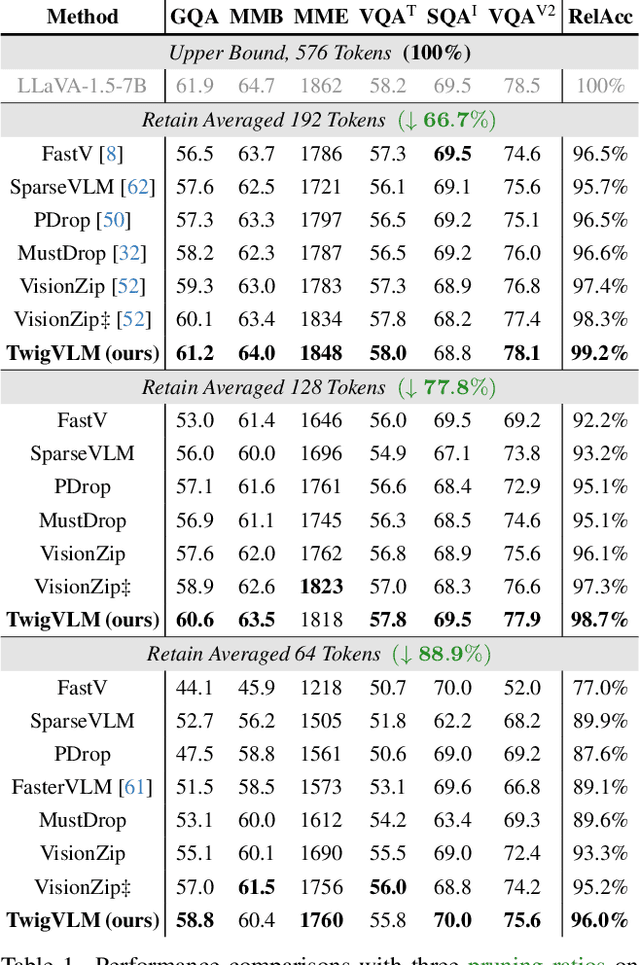
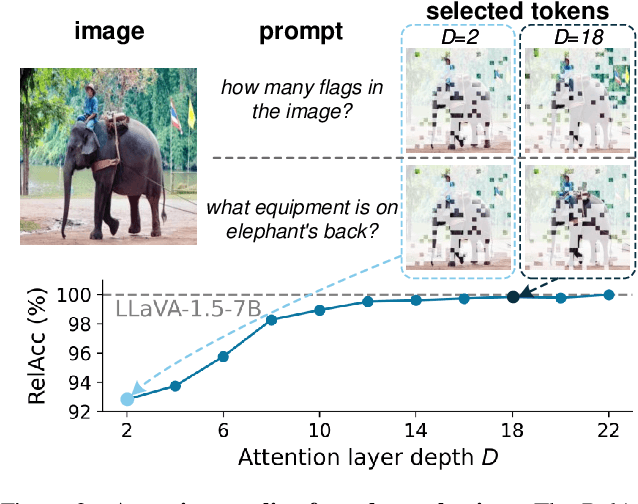
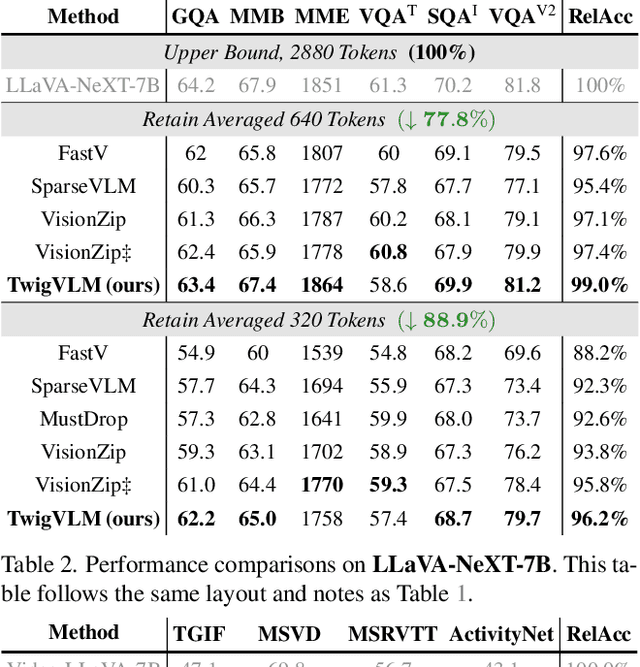
Large vision-language models (VLMs) have demonstrated remarkable capabilities in open-world multimodal understanding, yet their high computational overheads pose great challenges for practical deployment. Some recent works have proposed methods to accelerate VLMs by pruning redundant visual tokens guided by the attention maps of VLM's early layers. Despite the success of these token pruning methods, they still suffer from two major shortcomings: (i) considerable accuracy drop due to insensitive attention signals in early layers, and (ii) limited speedup when generating long responses (e.g., 30 tokens). To address the limitations above, we present TwigVLM -- a simple and general architecture by growing a lightweight twig upon an early layer of the base VLM. Compared with most existing VLM acceleration methods purely based on visual token pruning, our TwigVLM not only achieves better accuracy retention by employing a twig-guided token pruning (TTP) strategy, but also yields higher generation speed by utilizing a self-speculative decoding (SSD) strategy. Taking LLaVA-1.5-7B as the base VLM, experimental results show that TwigVLM preserves 96% of the original performance after pruning 88.9% of visual tokens and achieves 154% speedup in generating long responses, delivering significantly better performance in terms of both accuracy and speed over the state-of-the-art VLM acceleration methods. Code will be made publicly available.
Imp: Highly Capable Large Multimodal Models for Mobile Devices
May 20, 2024By harnessing the capabilities of large language models (LLMs), recent large multimodal models (LMMs) have shown remarkable versatility in open-world multimodal understanding. Nevertheless, they are usually parameter-heavy and computation-intensive, thus hindering their applicability in resource-constrained scenarios. To this end, several lightweight LMMs have been proposed successively to maximize the capabilities under constrained scale (e.g., 3B). Despite the encouraging results achieved by these methods, most of them only focus on one or two aspects of the design space, and the key design choices that influence model capability have not yet been thoroughly investigated. In this paper, we conduct a systematic study for lightweight LMMs from the aspects of model architecture, training strategy, and training data. Based on our findings, we obtain Imp -- a family of highly capable LMMs at the 2B-4B scales. Notably, our Imp-3B model steadily outperforms all the existing lightweight LMMs of similar size, and even surpasses the state-of-the-art LMMs at the 13B scale. With low-bit quantization and resolution reduction techniques, our Imp model can be deployed on a Qualcomm Snapdragon 8Gen3 mobile chip with a high inference speed of about 13 tokens/s.
Prompting Large Language Models with Answer Heuristics for Knowledge-based Visual Question Answering
Mar 16, 2023



Knowledge-based visual question answering (VQA) requires external knowledge beyond the image to answer the question. Early studies retrieve required knowledge from explicit knowledge bases (KBs), which often introduces irrelevant information to the question, hence restricting the performance of their models. Recent works have sought to use a large language model (i.e., GPT-3) as an implicit knowledge engine to acquire the necessary knowledge for answering. Despite the encouraging results achieved by these methods, we argue that they have not fully activated the capacity of GPT-3 as the provided input information is insufficient. In this paper, we present Prophet -- a conceptually simple framework designed to prompt GPT-3 with answer heuristics for knowledge-based VQA. Specifically, we first train a vanilla VQA model on a specific knowledge-based VQA dataset without external knowledge. After that, we extract two types of complementary answer heuristics from the model: answer candidates and answer-aware examples. Finally, the two types of answer heuristics are encoded into the prompts to enable GPT-3 to better comprehend the task thus enhancing its capacity. Prophet significantly outperforms all existing state-of-the-art methods on two challenging knowledge-based VQA datasets, OK-VQA and A-OKVQA, delivering 61.1% and 55.7% accuracies on their testing sets, respectively.