 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
ViewMask-1-to-3: Multi-View Consistent Image Generation via Multimodal Diffusion Models
Dec 16, 2025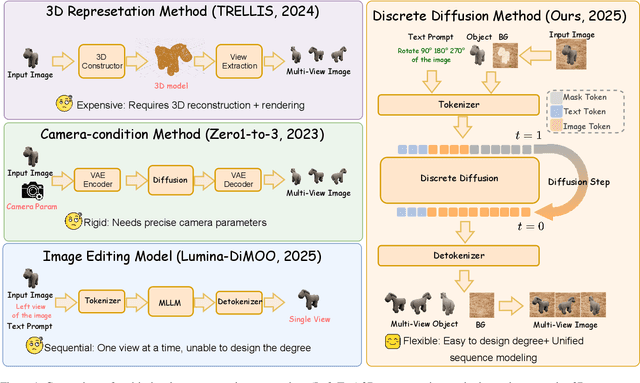
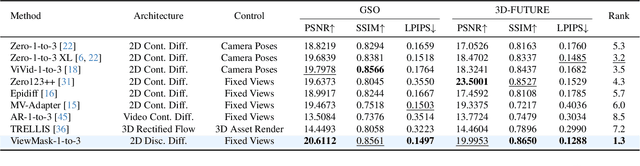
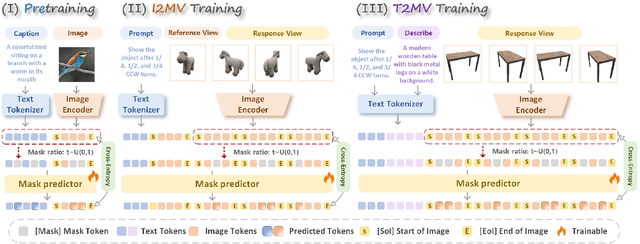
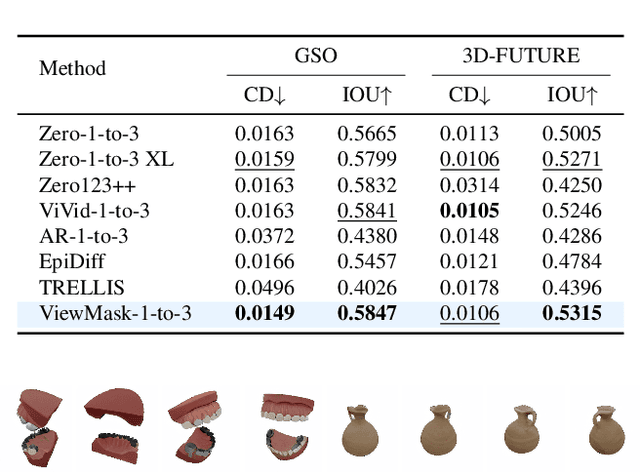
Multi-view image generation from a single image and text description remains challenging due to the difficulty of maintaining geometric consistency across different viewpoints. Existing approaches typically rely on 3D-aware architectures or specialized diffusion models that require extensive multi-view training data and complex geometric priors. In this work, we introduce ViewMask-1-to-3, a pioneering approach to apply discrete diffusion models to multi-view image generation. Unlike continuous diffusion methods that operate in latent spaces, ViewMask-1-to-3 formulates multi-view synthesis as a discrete sequence modeling problem, where each viewpoint is represented as visual tokens obtained through MAGVIT-v2 tokenization. By unifying language and vision through masked token prediction, our approach enables progressive generation of multiple viewpoints through iterative token unmasking with text input. ViewMask-1-to-3 achieves cross-view consistency through simple random masking combined with self-attention, eliminating the requirement for complex 3D geometric constraints or specialized attention architectures. Our approach demonstrates that discrete diffusion provides a viable and simple alternative to existing multi-view generation methods, ranking first on average across GSO and 3D-FUTURE datasets in terms of PSNR, SSIM, and LPIPS, while maintaining architectural simplicity.
GRPO-RM: Fine-Tuning Representation Models via GRPO-Driven Reinforcement Learning
Nov 19, 2025The Group Relative Policy Optimization (GRPO), a reinforcement learning method used to fine-tune large language models (LLMs), has proved its effectiveness in practical applications such as DeepSeek-R1. It raises a question whether GRPO can be generalized to representation learning models. In this paper, we propose Group Relative Policy Optimization for Representation Model (GRPO-RM), and investigate the performance of GRPO-like policy in post-training representation models. Specifically, our method establishes a predefined output set to functionally replace token sequence sampling in LLMs, thereby generating an output group, which is essential for the probability-driven optimization of GRPO. In addition, a specialized reward function is designed to accommodate the properties of representation models. Extensive experiments are conducted on various real-world datasets to validate the effectiveness of our proposed method.
Is Your VLM for Autonomous Driving Safety-Ready? A Comprehensive Benchmark for Evaluating External and In-Cabin Risks
Nov 19, 2025Vision-Language Models (VLMs) show great promise for autonomous driving, but their suitability for safety-critical scenarios is largely unexplored, raising safety concerns. This issue arises from the lack of comprehensive benchmarks that assess both external environmental risks and in-cabin driving behavior safety simultaneously. To bridge this critical gap, we introduce DSBench, the first comprehensive Driving Safety Benchmark designed to assess a VLM's awareness of various safety risks in a unified manner. DSBench encompasses two major categories: external environmental risks and in-cabin driving behavior safety, divided into 10 key categories and a total of 28 sub-categories. This comprehensive evaluation covers a wide range of scenarios, ensuring a thorough assessment of VLMs' performance in safety-critical contexts. Extensive evaluations across various mainstream open-source and closed-source VLMs reveal significant performance degradation under complex safety-critical situations, highlighting urgent safety concerns. To address this, we constructed a large dataset of 98K instances focused on in-cabin and external safety scenarios, showing that fine-tuning on this dataset significantly enhances the safety performance of existing VLMs and paves the way for advancing autonomous driving technology. The benchmark toolkit, code, and model checkpoints will be publicly accessible.
Explore How to Inject Beneficial Noise in MLLMs
Nov 17, 2025Multimodal Large Language Models (MLLMs) have played an increasingly important role in multimodal intelligence. However, the existing fine-tuning methods often ignore cross-modal heterogeneity, limiting their full potential. In this work, we propose a novel fine-tuning strategy by injecting beneficial random noise, which outperforms previous methods and even surpasses full fine-tuning, with minimal additional parameters. The proposed Multimodal Noise Generator (MuNG) enables efficient modality fine-tuning by injecting customized noise into the frozen MLLMs. Specifically, we reformulate the reasoning process of MLLMs from a variational inference perspective, upon which we design a multimodal noise generator that dynamically analyzes cross-modal relationships in image-text pairs to generate task-adaptive beneficial noise. Injecting this type of noise into the MLLMs effectively suppresses irrelevant semantic components, leading to significantly improved cross-modal representation alignment and enhanced performance on downstream tasks. Experiments on two mainstream MLLMs, QwenVL and LLaVA, demonstrate that our method surpasses full-parameter fine-tuning and other existing fine-tuning approaches, while requiring adjustments to only about $1\sim2\%$ additional parameters. The relevant code is uploaded in the supplementary.
Rectified Noise: A Generative Model Using Positive-incentive Noise
Nov 12, 2025Rectified Flow (RF) has been widely used as an effective generative model. Although RF is primarily based on probability flow Ordinary Differential Equations (ODE), recent studies have shown that injecting noise through reverse-time Stochastic Differential Equations (SDE) for sampling can achieve superior generative performance. Inspired by Positive-incentive Noise (pi-noise), we propose an innovative generative algorithm to train pi-noise generators, namely Rectified Noise (RN), which improves the generative performance by injecting pi-noise into the velocity field of pre-trained RF models. After introducing the Rectified Noise pipeline, pre-trained RF models can be efficiently transformed into pi-noise generators. We validate Rectified Noise by conducting extensive experiments across various model architectures on different datasets. Notably, we find that: (1) RF models using Rectified Noise reduce FID from 10.16 to 9.05 on ImageNet-1k. (2) The models of pi-noise generators achieve improved performance with only 0.39% additional training parameters.
Laytrol: Preserving Pretrained Knowledge in Layout Control for Multimodal Diffusion Transformers
Nov 11, 2025With the development of diffusion models, enhancing spatial controllability in text-to-image generation has become a vital challenge. As a representative task for addressing this challenge, layout-to-image generation aims to generate images that are spatially consistent with the given layout condition. Existing layout-to-image methods typically introduce the layout condition by integrating adapter modules into the base generative model. However, the generated images often exhibit low visual quality and stylistic inconsistency with the base model, indicating a loss of pretrained knowledge. To alleviate this issue, we construct the Layout Synthesis (LaySyn) dataset, which leverages images synthesized by the base model itself to mitigate the distribution shift from the pretraining data. Moreover, we propose the Layout Control (Laytrol) Network, in which parameters are inherited from MM-DiT to preserve the pretrained knowledge of the base model. To effectively activate the copied parameters and avoid disturbance from unstable control conditions, we adopt a dedicated initialization scheme for Laytrol. In this scheme, the layout encoder is initialized as a pure text encoder to ensure that its output tokens remain within the data domain of MM-DiT. Meanwhile, the outputs of the layout control network are initialized to zero. In addition, we apply Object-level Rotary Position Embedding to the layout tokens to provide coarse positional information. Qualitative and quantitative experiments demonstrate the effectiveness of our method.
CoLM: Collaborative Large Models via A Client-Server Paradigm
Nov 10, 2025Large models have achieved remarkable performance across a range of reasoning and understanding tasks. Prior work often utilizes model ensembles or multi-agent systems to collaboratively generate responses, effectively operating in a server-to-server paradigm. However, such approaches do not align well with practical deployment settings, where a limited number of server-side models are shared by many clients under modern internet architectures. In this paper, we introduce \textbf{CoLM} (\textbf{Co}llaboration in \textbf{L}arge-\textbf{M}odels), a novel framework for collaborative reasoning that redefines cooperation among large models from a client-server perspective. Unlike traditional ensemble methods that rely on simultaneous inference from multiple models to produce a single output, CoLM allows the outputs of multiple models to be aggregated or shared, enabling each client model to independently refine and update its own generation based on these high-quality outputs. This design enables collaborative benefits by fully leveraging both client-side and shared server-side models. We further extend CoLM to vision-language models (VLMs), demonstrating its applicability beyond language tasks. Experimental results across multiple benchmarks show that CoLM consistently improves model performance on previously failed queries, highlighting the effectiveness of collaborative guidance in enhancing single-model capabilities.
Class-Aware Prototype Learning with Negative Contrast for Test-Time Adaptation of Vision-Language Models
Oct 22, 2025Vision-Language Models (VLMs) demonstrate impressive zero-shot generalization through large-scale image-text pretraining, yet their performance can drop once the deployment distribution diverges from the training distribution. To address this, Test-Time Adaptation (TTA) methods update models using unlabeled target data. However, existing approaches often ignore two key challenges: prototype degradation in long-tailed distributions and confusion between semantically similar classes. To tackle these issues, we propose \textbf{C}lass-Aware \textbf{P}rototype \textbf{L}earning with \textbf{N}egative \textbf{C}ontrast(\textbf{CPL-NC}), a lightweight TTA framework designed specifically for VLMs to enhance generalization under distribution shifts. CPL-NC introduces a \textit{Class-Aware Prototype Cache} Module that dynamically adjusts per-class capacity based on test-time frequency and activation history, with a rejuvenation mechanism for inactive classes to retain rare-category knowledge. Additionally, a \textit{Negative Contrastive Learning} Mechanism identifies and constrains hard visual-textual negatives to improve class separability. The framework employs asymmetric optimization, refining only textual prototypes while anchoring on stable visual features. Experiments on 15 benchmarks show that CPL-NC consistently outperforms prior TTA methods across both ResNet-50 and ViT-B/16 backbones.