 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeum-VL Technical Report
Mar 20, 2026A short video succeeds not simply because of what it shows, but because of how it schedules attention -- yet current multimodal models lack the structural grammar to parse or produce this organization. Existing models can describe scenes, answer event-centric questions, and read on-screen text, but they are far less reliable at identifying timeline-grounded units such as hooks, cut rationales, shot-induced tension, and platform-facing packaging cues. We propose SV6D (Structured Video in Six Dimensions), inspired by professional storyboard practice in film and television production, a representation framework that decomposes internet-native video into six complementary structural dimensions -- subject, aesthetics, camera language, editing, narrative, and dissemination -- with each label tied to physically observable evidence on the timeline. We formalize a unified optimization objective over SV6D that combines Hungarian-matched temporal alignment, dimension-wise semantic label distance, and quality regularization. Building on this framework, we present Leum-VL-8B, an 8B video-language model that realizes the SV6D objective through an expert-driven post-training pipeline, further refined through verifiable reinforcement learning on perception-oriented tasks. Leum-VL-8B achieves 70.8 on VideoMME (w/o subtitles), 70.0 on MVBench, and 61.6 on MotionBench, while remaining competitive on general multimodal evaluations such as MMBench-EN. We also construct FeedBench, a benchmark for structure-sensitive short-video understanding. Our results indicate that the missing layer in video AI is not pixel generation but structural representation: grounded on the timeline, linked to visible evidence, and directly consumable by downstream workflows such as editing, retrieval, recommendation, and generation control, including text-heavy internet video formats with overlays and image-text layouts.
TTMBA: Towards Text To Multiple Sources Binaural Audio Generation
Jul 22, 2025



Most existing text-to-audio (TTA) generation methods produce mono outputs, neglecting essential spatial information for immersive auditory experiences. To address this issue, we propose a cascaded method for text-to-multisource binaural audio generation (TTMBA) with both temporal and spatial control. First, a pretrained large language model (LLM) segments the text into a structured format with time and spatial details for each sound event. Next, a pretrained mono audio generation network creates multiple mono audios with varying durations for each event. These mono audios are transformed into binaural audios using a binaural rendering neural network based on spatial data from the LLM. Finally, the binaural audios are arranged by their start times, resulting in multisource binaural audio. Experimental results demonstrate the superiority of the proposed method in terms of both audio generation quality and spatial perceptual accuracy.
Towards the Three-Phase Dynamics of Generalization Power of a DNN
May 11, 2025This paper proposes a new perspective for analyzing the generalization power of deep neural networks (DNNs), i.e., directly disentangling and analyzing the dynamics of generalizable and non-generalizable interaction encoded by a DNN through the training process. Specifically, this work builds upon the recent theoretical achievement in explainble AI, which proves that the detailed inference logic of DNNs can be can be strictly rewritten as a small number of AND-OR interaction patterns. Based on this, we propose an efficient method to quantify the generalization power of each interaction, and we discover a distinct three-phase dynamics of the generalization power of interactions during training. In particular, the early phase of training typically removes noisy and non-generalizable interactions and learns simple and generalizable ones. The second and the third phases tend to capture increasingly complex interactions that are harder to generalize. Experimental results verify that the learning of non-generalizable interactions is the the direct cause for the gap between the training and testing losses.
An Empirical Study of Benchmarking Chinese Aspect Sentiment Quad Prediction
Nov 03, 2023
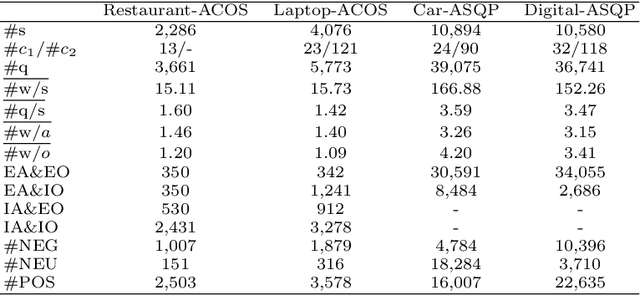


Aspect sentiment quad prediction (ASQP) is a critical subtask of aspect-level sentiment analysis. Current ASQP datasets are characterized by their small size and low quadruple density, which hinders technical development. To expand capacity, we construct two large Chinese ASQP datasets crawled from multiple online platforms. The datasets hold several significant characteristics: larger size (each with 10,000+ samples) and rich aspect categories, more words per sentence, and higher density than existing ASQP datasets. Moreover, we are the first to evaluate the performance of Generative Pre-trained Transformer (GPT) series models on ASQP and exhibit potential issues. The experiments with state-of-the-art ASQP baselines underscore the need to explore additional techniques to address ASQP, as well as the importance of further investigation into methods to improve the performance of GPTs.
A Unified One-Step Solution for Aspect Sentiment Quad Prediction
Jun 07, 2023



Aspect sentiment quad prediction (ASQP) is a challenging yet significant subtask in aspect-based sentiment analysis as it provides a complete aspect-level sentiment structure. However, existing ASQP datasets are usually small and low-density, hindering technical advancement. To expand the capacity, in this paper, we release two new datasets for ASQP, which contain the following characteristics: larger size, more words per sample, and higher density. With such datasets, we unveil the shortcomings of existing strong ASQP baselines and therefore propose a unified one-step solution for ASQP, namely One-ASQP, to detect the aspect categories and to identify the aspect-opinion-sentiment (AOS) triplets simultaneously. Our One-ASQP holds several unique advantages: (1) by separating ASQP into two subtasks and solving them independently and simultaneously, we can avoid error propagation in pipeline-based methods and overcome slow training and inference in generation-based methods; (2) by introducing sentiment-specific horns tagging schema in a token-pair-based two-dimensional matrix, we can exploit deeper interactions between sentiment elements and efficiently decode the AOS triplets; (3) we design ``[NULL]'' token can help us effectively identify the implicit aspects or opinions. Experiments on two benchmark datasets and our released two datasets demonstrate the advantages of our One-ASQP. The two new datasets are publicly released at \url{https://www.github.com/Datastory-CN/ASQP-Datasets}.
Model-Agnostic Meta-Learning for Natural Language Understanding Tasks in Finance
Mar 06, 2023



Natural language understanding(NLU) is challenging for finance due to the lack of annotated data and the specialized language in that domain. As a result, researchers have proposed to use pre-trained language model and multi-task learning to learn robust representations. However, aggressive fine-tuning often causes over-fitting and multi-task learning may favor tasks with significantly larger amounts data, etc. To address these problems, in this paper, we investigate model-agnostic meta-learning algorithm(MAML) in low-resource financial NLU tasks. Our contribution includes: 1. we explore the performance of MAML method with multiple types of tasks: GLUE datasets, SNLI, Sci-Tail and Financial PhraseBank; 2. we study the performance of MAML method with multiple single-type tasks: a real scenario stock price prediction problem with twitter text data. Our models achieve the state-of-the-art performance according to the experimental results, which demonstrate that our method can adapt fast and well to low-resource situations.
Auto-KWS 2021 Challenge: Task, Datasets, and Baselines
Mar 31, 2021

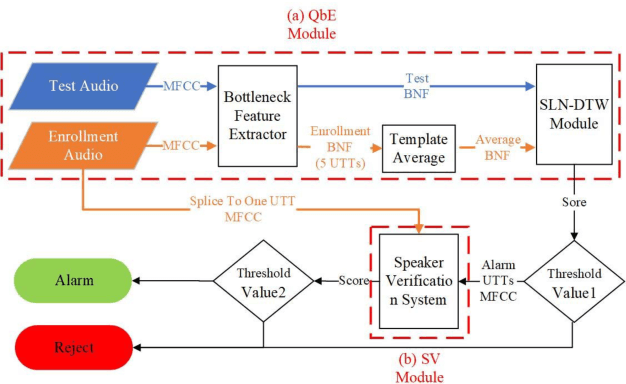

Auto-KWS 2021 challenge calls for automated machine learning (AutoML) solutions to automate the process of applying machine learning to a customized keyword spotting task. Compared with other keyword spotting tasks, Auto-KWS challenge has the following three characteristics: 1) The challenge focuses on the problem of customized keyword spotting, where the target device can only be awakened by an enrolled speaker with his specified keyword. The speaker can use any language and accent to define his keyword. 2) All dataset of the challenge is recorded in realistic environment. It is to simulate different user scenarios. 3) Auto-KWS is a "code competition", where participants need to submit AutoML solutions, then the platform automatically runs the enrollment and prediction steps with the submitted code.This challenge aims at promoting the development of a more personalized and flexible keyword spotting system. Two baseline systems are provided to all participants as references.
FairPrep: Promoting Data to a First-Class Citizen in Studies on Fairness-Enhancing Interventions
Nov 28, 2019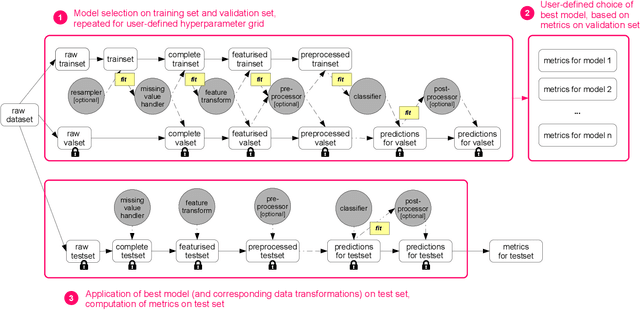
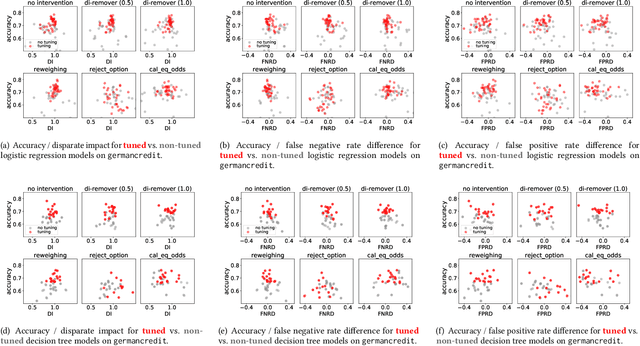
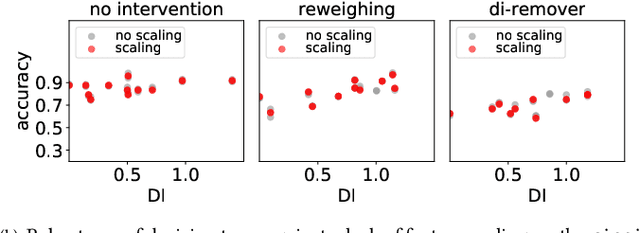
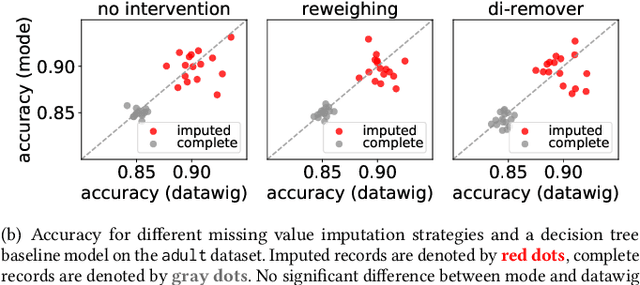
The importance of incorporating ethics and legal compliance into machine-assisted decision-making is broadly recognized. Further, several lines of recent work have argued that critical opportunities for improving data quality and representativeness, controlling for bias, and allowing humans to oversee and impact computational processes are missed if we do not consider the lifecycle stages upstream from model training and deployment. Yet, very little has been done to date to provide system-level support to data scientists who wish to develop and deploy responsible machine learning methods. We aim to fill this gap and present FairPrep, a design and evaluation framework for fairness-enhancing interventions. FairPrep is based on a developer-centered design, and helps data scientists follow best practices in software engineering and machine learning. As part of our contribution, we identify shortcomings in existing empirical studies for analyzing fairness-enhancing interventions. We then show how FairPrep can be used to measure the impact of sound best practices, such as hyperparameter tuning and feature scaling. In particular, our results suggest that the high variability of the outcomes of fairness-enhancing interventions observed in previous studies is often an artifact of a lack of hyperparameter tuning. Further, we show that the choice of a data cleaning method can impact the effectiveness of fairness-enhancing interventions.