 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Augmented Variational Autoencoder in Time Series Anomaly Detection
Jan 07, 2024Due to their unsupervised training and uncertainty estimation, deep Variational Autoencoders (VAEs) have become powerful tools for reconstruction-based Time Series Anomaly Detection (TSAD). Existing VAE-based TSAD methods, either statistical or deep, tune meta-priors to estimate the likelihood probability for effectively capturing spatiotemporal dependencies in the data. However, these methods confront the challenge of inherent data scarcity, which is often the case in anomaly detection tasks. Such scarcity easily leads to latent holes, discontinuous regions in latent space, resulting in non-robust reconstructions on these discontinuous spaces. We propose a novel generative framework that combines VAEs with self-supervised learning (SSL) to address this issue.
An Empirical Study of Benchmarking Chinese Aspect Sentiment Quad Prediction
Nov 03, 2023
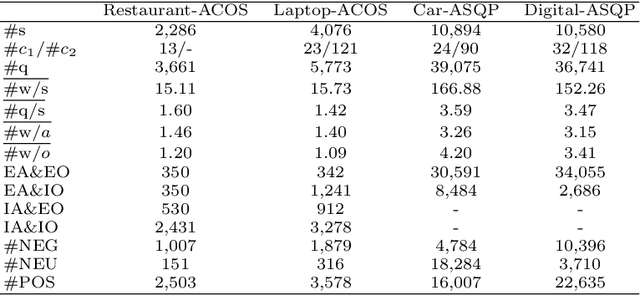


Aspect sentiment quad prediction (ASQP) is a critical subtask of aspect-level sentiment analysis. Current ASQP datasets are characterized by their small size and low quadruple density, which hinders technical development. To expand capacity, we construct two large Chinese ASQP datasets crawled from multiple online platforms. The datasets hold several significant characteristics: larger size (each with 10,000+ samples) and rich aspect categories, more words per sentence, and higher density than existing ASQP datasets. Moreover, we are the first to evaluate the performance of Generative Pre-trained Transformer (GPT) series models on ASQP and exhibit potential issues. The experiments with state-of-the-art ASQP baselines underscore the need to explore additional techniques to address ASQP, as well as the importance of further investigation into methods to improve the performance of GPTs.
A Unified One-Step Solution for Aspect Sentiment Quad Prediction
Jun 07, 2023



Aspect sentiment quad prediction (ASQP) is a challenging yet significant subtask in aspect-based sentiment analysis as it provides a complete aspect-level sentiment structure. However, existing ASQP datasets are usually small and low-density, hindering technical advancement. To expand the capacity, in this paper, we release two new datasets for ASQP, which contain the following characteristics: larger size, more words per sample, and higher density. With such datasets, we unveil the shortcomings of existing strong ASQP baselines and therefore propose a unified one-step solution for ASQP, namely One-ASQP, to detect the aspect categories and to identify the aspect-opinion-sentiment (AOS) triplets simultaneously. Our One-ASQP holds several unique advantages: (1) by separating ASQP into two subtasks and solving them independently and simultaneously, we can avoid error propagation in pipeline-based methods and overcome slow training and inference in generation-based methods; (2) by introducing sentiment-specific horns tagging schema in a token-pair-based two-dimensional matrix, we can exploit deeper interactions between sentiment elements and efficiently decode the AOS triplets; (3) we design ``[NULL]'' token can help us effectively identify the implicit aspects or opinions. Experiments on two benchmark datasets and our released two datasets demonstrate the advantages of our One-ASQP. The two new datasets are publicly released at \url{https://www.github.com/Datastory-CN/ASQP-Datasets}.