 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested AutoRegressive Models
Oct 27, 2025AutoRegressive (AR) models have demonstrated competitive performance in image generation, achieving results comparable to those of diffusion models. However, their token-by-token image generation mechanism remains computationally intensive and existing solutions such as VAR often lead to limited sample diversity. In this work, we propose a Nested AutoRegressive~(NestAR) model, which proposes nested AutoRegressive architectures in generating images. NestAR designs multi-scale modules in a hierarchical order. These different scaled modules are constructed in an AR architecture, where one larger-scale module is conditioned on outputs from its previous smaller-scale module. Within each module, NestAR uses another AR structure to generate ``patches'' of tokens. The proposed nested AR architecture reduces the overall complexity from $\mathcal{O}(n)$ to $\mathcal{O}(\log n)$ in generating $n$ image tokens, as well as increases image diversities. NestAR further incorporates flow matching loss to use continuous tokens, and develops objectives to coordinate these multi-scale modules in model training. NestAR achieves competitive image generation performance while significantly lowering computational cost.
FAME: Fairness-aware Attention-modulated Video Editing
Oct 27, 2025Training-free video editing (VE) models tend to fall back on gender stereotypes when rendering profession-related prompts. We propose \textbf{FAME} for \textit{Fairness-aware Attention-modulated Video Editing} that mitigates profession-related gender biases while preserving prompt alignment and temporal consistency for coherent VE. We derive fairness embeddings from existing minority representations by softly injecting debiasing tokens into the text encoder. Simultaneously, FAME integrates fairness modulation into both temporal self attention and prompt-to-region cross attention to mitigate the motion corruption and temporal inconsistency caused by directly introducing fairness cues. For temporal self attention, FAME introduces a region constrained attention mask combined with time decay weighting, which enhances intra-region coherence while suppressing irrelevant inter-region interactions. For cross attention, it reweights tokens to region matching scores by incorporating fairness sensitive similarity masks derived from debiasing prompt embeddings. Together, these modulations keep fairness-sensitive semantics tied to the right visual regions and prevent temporal drift across frames. Extensive experiments on new VE fairness-oriented benchmark \textit{FairVE} demonstrate that FAME achieves stronger fairness alignment and semantic fidelity, surpassing existing VE baselines.
VALA: Learning Latent Anchors for Training-Free and Temporally Consistent
Oct 27, 2025Recent advances in training-free video editing have enabled lightweight and precise cross-frame generation by leveraging pre-trained text-to-image diffusion models. However, existing methods often rely on heuristic frame selection to maintain temporal consistency during DDIM inversion, which introduces manual bias and reduces the scalability of end-to-end inference. In this paper, we propose~\textbf{VALA} (\textbf{V}ariational \textbf{A}lignment for \textbf{L}atent \textbf{A}nchors), a variational alignment module that adaptively selects key frames and compresses their latent features into semantic anchors for consistent video editing. To learn meaningful assignments, VALA propose a variational framework with a contrastive learning objective. Therefore, it can transform cross-frame latent representations into compressed latent anchors that preserve both content and temporal coherence. Our method can be fully integrated into training-free text-to-image based video editing models. Extensive experiments on real-world video editing benchmarks show that VALA achieves state-of-the-art performance in inversion fidelity, editing quality, and temporal consistency, while offering improved efficiency over prior methods.
FigBO: A Generalized Acquisition Function Framework with Look-Ahead Capability for Bayesian Optimization
Apr 28, 2025Bayesian optimization is a powerful technique for optimizing expensive-to-evaluate black-box functions, consisting of two main components: a surrogate model and an acquisition function. In recent years, myopic acquisition functions have been widely adopted for their simplicity and effectiveness. However, their lack of look-ahead capability limits their performance. To address this limitation, we propose FigBO, a generalized acquisition function that incorporates the future impact of candidate points on global information gain. FigBO is a plug-and-play method that can integrate seamlessly with most existing myopic acquisition functions. Theoretically, we analyze the regret bound and convergence rate of FigBO when combined with the myopic base acquisition function expected improvement (EI), comparing them to those of standard EI. Empirically, extensive experimental results across diverse tasks demonstrate that FigBO achieves state-of-the-art performance and significantly faster convergence compared to existing methods.
TraFlow: Trajectory Distillation on Pre-Trained Rectified Flow
Feb 24, 2025Majorities of distillation methods on pre-trained diffusion models or on pre-trained rectified flow, focus on either the distillation outputs or the trajectories between random noises and clean images to speed up sample generations from pre-trained models. In those trajectory-based distillation methods, consistency distillation requires the self-consistent trajectory projection to regulate the trajectory, which might avoid the common ODE approximation error {while still be concerning about sampling efficiencies}. At the same time, rectified flow distillations enforce straight trajectory for fast sampling, although an ODE solver is still required. In this work, we propose a trajectory distillation method, \modelname, that enjoys the benefits of both and enables few-step generations. TraFlow adopts the settings of consistency trajectory models, and further enforces the properties of self-consistency and straightness throughout the entire trajectory. These two properties are pursued by reaching a balance with following three targets: (1) reconstruct the output from pre-trained models; (2) learn the amount of changes by pre-trained models; (3) satisfy the self-consistency over its trajectory. Extensive experimental results have shown the effectiveness of our proposed method.
A Survey on Pre-Trained Diffusion Model Distillations
Feb 12, 2025Diffusion Models~(DMs) have emerged as the dominant approach in Generative Artificial Intelligence (GenAI), owing to their remarkable performance in tasks such as text-to-image synthesis. However, practical DMs, such as stable diffusion, are typically trained on massive datasets and thus usually require large storage. At the same time, many steps may be required, i.e., recursively evaluating the trained neural network, to generate a high-quality image, which results in significant computational costs during sample generation. As a result, distillation methods on pre-trained DM have become widely adopted practices to develop smaller, more efficient models capable of rapid, few-step generation in low-resource environment. When these distillation methods are developed from different perspectives, there is an urgent need for a systematic survey, particularly from a methodological perspective. In this survey, we review distillation methods through three aspects: output loss distillation, trajectory distillation and adversarial distillation. We also discuss current challenges and outline future research directions in the conclusion.
ParamReL: Learning Parameter Space Representation via Progressively Encoding Bayesian Flow Networks
May 24, 2024The recently proposed Bayesian Flow Networks~(BFNs) show great potential in modeling parameter spaces, offering a unified strategy for handling continuous, discretized, and discrete data. However, BFNs cannot learn high-level semantic representation from the parameter space since {common encoders, which encode data into one static representation, cannot capture semantic changes in parameters.} This motivates a new direction: learning semantic representations hidden in the parameter spaces to characterize mixed-typed noisy data. {Accordingly, we propose a representation learning framework named ParamReL, which operates in the parameter space to obtain parameter-wise latent semantics that exhibit progressive structures. Specifically, ParamReL proposes a \emph{self-}encoder to learn latent semantics directly from parameters, rather than from observations. The encoder is then integrated into BFNs, enabling representation learning with various formats of observations. Mutual information terms further promote the disentanglement of latent semantics and capture meaningful semantics simultaneously.} We illustrate {conditional generation and reconstruction} in ParamReL via expanding BFNs, and extensive {quantitative} experimental results demonstrate the {superior effectiveness} of ParamReL in learning parameter representation.
FedSI: Federated Subnetwork Inference for Efficient Uncertainty Quantification
Apr 24, 2024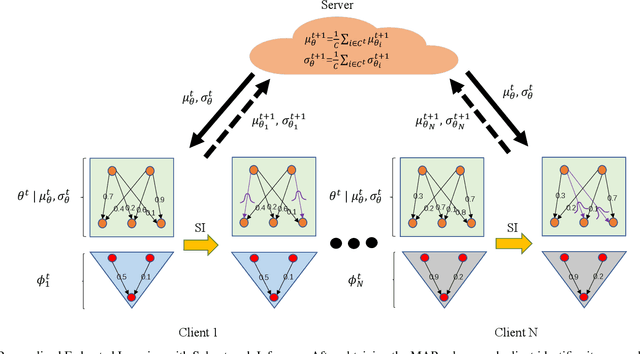
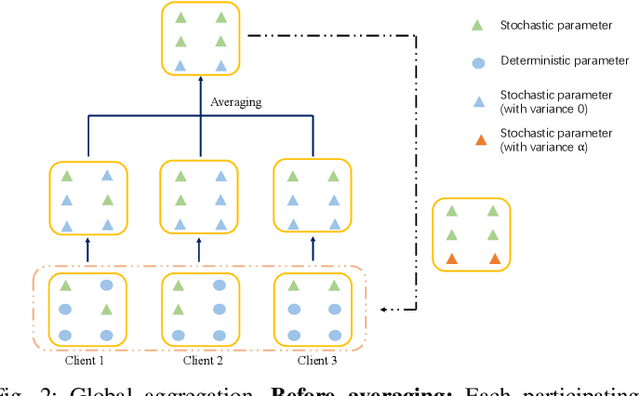
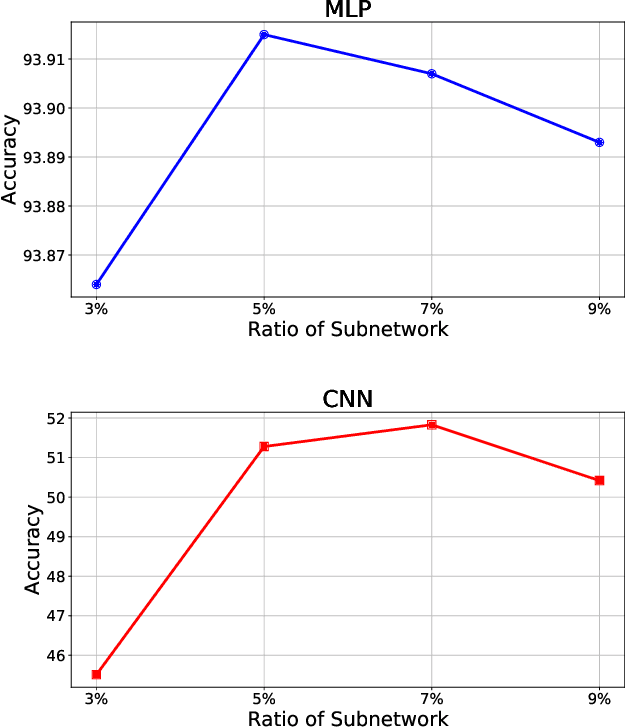
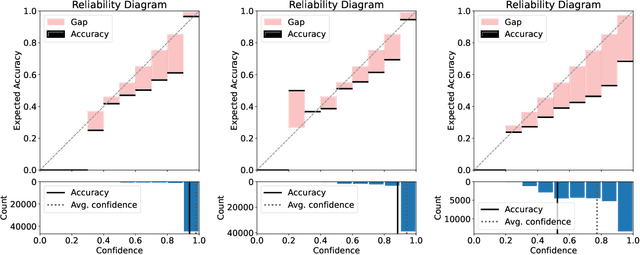
While deep neural networks (DNNs) based personalized federated learning (PFL) is demanding for addressing data heterogeneity and shows promising performance, existing methods for federated learning (FL) suffer from efficient systematic uncertainty quantification. The Bayesian DNNs-based PFL is usually questioned of either over-simplified model structures or high computational and memory costs. In this paper, we introduce FedSI, a novel Bayesian DNNs-based subnetwork inference PFL framework. FedSI is simple and scalable by leveraging Bayesian methods to incorporate systematic uncertainties effectively. It implements a client-specific subnetwork inference mechanism, selects network parameters with large variance to be inferred through posterior distributions, and fixes the rest as deterministic ones. FedSI achieves fast and scalable inference while preserving the systematic uncertainties to the fullest extent. Extensive experiments on three different benchmark datasets demonstrate that FedSI outperforms existing Bayesian and non-Bayesian FL baselines in heterogeneous FL scenarios.
LERENet: Eliminating Intra-class Differences for Metal Surface Defect Few-shot Semantic Segmentation
Mar 17, 2024Few-shot segmentation models excel in metal defect detection due to their rapid generalization ability to new classes and pixel-level segmentation, rendering them ideal for addressing data scarcity issues and achieving refined object delineation in industrial applications. Existing works neglect the \textit{Intra-Class Differences}, inherent in metal surface defect data, which hinders the model from learning sufficient knowledge from the support set to guide the query set segmentation. Specifically, it can be categorized into two types: the \textit{Semantic Difference} induced by internal factors in metal samples and the \textit{Distortion Difference} caused by external factors of surroundings. To address these differences, we introduce a \textbf{L}ocal d\textbf{E}scriptor based \textbf{R}easoning and \textbf{E}xcitation \textbf{Net}work (\textbf{LERENet}) to learn the two-view guidance, i.e., local and global information from the graph and feature space, and fuse them to segment precisely. Since the relation structure of local features embedded in graph space will help to eliminate \textit{Semantic Difference}, we employ Multi-Prototype Reasoning (MPR) module, extracting local descriptors based prototypes and analyzing local-view feature relevance in support-query pairs. Besides, due to the global information that will assist in countering the \textit{Distortion Difference} in observations, we utilize Multi-Prototype Excitation (MPE) module to capture the global-view relations in support-query pairs. Finally, we employ an Information Fusion Module (IFM) to fuse learned prototypes in local and global views to generate pixel-level masks. Our comprehensive experiments on defect datasets demonstrate that it outperforms existing benchmarks, establishing a new state-of-the-art.
Temporal Disentangled Contrastive Diffusion Model for Spatiotemporal Imputation
Feb 18, 2024



Spatiotemporal data analysis is pivotal across various domains, including transportation, meteorology, and healthcare. However, the data collected in real-world scenarios often suffers incompleteness due to sensor malfunctions and network transmission errors. Spatiotemporal imputation endeavours to predict missing values by exploiting the inherent spatial and temporal dependencies present in the observed data. Traditional approaches, which rely on classical statistical and machine learning techniques, are often inadequate, particularly when the data fails to meet strict distributional assumptions. In contrast, recent deep learning-based methods, leveraging graph and recurrent neural networks, have demonstrated enhanced efficacy. Nonetheless, these approaches are prone to error accumulation. Generative models have been increasingly adopted to circumvent the reliance on potentially inaccurate historical imputed values for future predictions. These models grapple with the challenge of producing unstable results, a particular issue in diffusion-based models. We aim to address these challenges by designing conditional features to guide the generative process and expedite training. Specifically, we introduce C$^2$TSD, a novel approach incorporating trend and seasonal information as conditional features and employing contrastive learning to improve model generalizability. The extensive experiments on three real-world datasets demonstrate the superior performance of C$^2$TSD over various state-of-the-art baselines.