 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUT-ACA: Uncertainty-Triggered Adaptive Context Allocation for Long-Context Inference
Mar 19, 2026Long-context inference remains challenging for large language models due to attention dilution and out-of-distribution degradation. Context selection mitigates this limitation by attending to a subset of key-value cache entries, yet most methods allocate a fixed context budget throughout decoding despite highly non-uniform token-level contextual demands. To address this issue, we propose Uncertainty-Triggered Adaptive Context Allocation (UT-ACA), an inference-time framework that dynamically adjusts the context window based on token-wise uncertainty. UT-ACA learns an uncertainty detector that combines semantic embeddings with logit-based confidence while accounting for uncertainty accumulation across decoding steps. When insufficient evidence is indicated, UT-ACA selectively rolls back, expands the context window, and regenerates the token with additional support. Experiments show that UT-ACA substantially reduces average context usage while preserving generation quality in long-context settings.
DCAC: Dynamic Class-Aware Cache Creates Stronger Out-of-Distribution Detectors
Jan 18, 2026Out-of-distribution (OOD) detection remains a fundamental challenge for deep neural networks, particularly due to overconfident predictions on unseen OOD samples during testing. We reveal a key insight: OOD samples predicted as the same class, or given high probabilities for it, are visually more similar to each other than to the true in-distribution (ID) samples. Motivated by this class-specific observation, we propose DCAC (Dynamic Class-Aware Cache), a training-free, test-time calibration module that maintains separate caches for each ID class to collect high-entropy samples and calibrate the raw predictions of input samples. DCAC leverages cached visual features and predicted probabilities through a lightweight two-layer module to mitigate overconfident predictions on OOD samples. This module can be seamlessly integrated with various existing OOD detection methods across both unimodal and vision-language models while introducing minimal computational overhead. Extensive experiments on multiple OOD benchmarks demonstrate that DCAC significantly enhances existing methods, achieving substantial improvements, i.e., reducing FPR95 by 6.55% when integrated with ASH-S on ImageNet OOD benchmark.
Learning Whole-Body Human-Humanoid Interaction from Human-Human Demonstrations
Jan 14, 2026Enabling humanoid robots to physically interact with humans is a critical frontier, but progress is hindered by the scarcity of high-quality Human-Humanoid Interaction (HHoI) data. While leveraging abundant Human-Human Interaction (HHI) data presents a scalable alternative, we first demonstrate that standard retargeting fails by breaking the essential contacts. We address this with PAIR (Physics-Aware Interaction Retargeting), a contact-centric, two-stage pipeline that preserves contact semantics across morphology differences to generate physically consistent HHoI data. This high-quality data, however, exposes a second failure: conventional imitation learning policies merely mimic trajectories and lack interactive understanding. We therefore introduce D-STAR (Decoupled Spatio-Temporal Action Reasoner), a hierarchical policy that disentangles when to act from where to act. In D-STAR, Phase Attention (when) and a Multi-Scale Spatial module (where) are fused by the diffusion head to produce synchronized whole-body behaviors beyond mimicry. By decoupling these reasoning streams, our model learns robust temporal phases without being distracted by spatial noise, leading to responsive, synchronized collaboration. We validate our framework through extensive and rigorous simulations, demonstrating significant performance gains over baseline approaches and a complete, effective pipeline for learning complex whole-body interactions from HHI data.
Exploring the Limits of Vision-Language-Action Manipulations in Cross-task Generalization
May 21, 2025The generalization capabilities of vision-language-action (VLA) models to unseen tasks are crucial to achieving general-purpose robotic manipulation in open-world settings. However, the cross-task generalization capabilities of existing VLA models remain significantly underexplored. To address this gap, we introduce AGNOSTOS, a novel simulation benchmark designed to rigorously evaluate cross-task zero-shot generalization in manipulation. AGNOSTOS comprises 23 unseen manipulation tasks for testing, distinct from common training task distributions, and incorporates two levels of generalization difficulty to assess robustness. Our systematic evaluation reveals that current VLA models, despite being trained on diverse datasets, struggle to generalize effectively to these unseen tasks. To overcome this limitation, we propose Cross-Task In-Context Manipulation (X-ICM), a method that conditions large language models (LLMs) on in-context demonstrations from seen tasks to predict action sequences for unseen tasks. Additionally, we introduce a dynamics-guided sample selection strategy that identifies relevant demonstrations by capturing cross-task dynamics. On AGNOSTOS, X-ICM significantly improves cross-task zero-shot generalization performance over leading VLAs. We believe AGNOSTOS and X-ICM will serve as valuable tools for advancing general-purpose robotic manipulation.
Federated Neural Nonparametric Point Processes
Oct 08, 2024Temporal point processes (TPPs) are effective for modeling event occurrences over time, but they struggle with sparse and uncertain events in federated systems, where privacy is a major concern. To address this, we propose \textit{FedPP}, a Federated neural nonparametric Point Process model. FedPP integrates neural embeddings into Sigmoidal Gaussian Cox Processes (SGCPs) on the client side, which is a flexible and expressive class of TPPs, allowing it to generate highly flexible intensity functions that capture client-specific event dynamics and uncertainties while efficiently summarizing historical records. For global aggregation, FedPP introduces a divergence-based mechanism that communicates the distributions of SGCPs' kernel hyperparameters between the server and clients, while keeping client-specific parameters local to ensure privacy and personalization. FedPP effectively captures event uncertainty and sparsity, and extensive experiments demonstrate its superior performance in federated settings, particularly with KL divergence and Wasserstein distance-based global aggregation.
ParamReL: Learning Parameter Space Representation via Progressively Encoding Bayesian Flow Networks
May 24, 2024The recently proposed Bayesian Flow Networks~(BFNs) show great potential in modeling parameter spaces, offering a unified strategy for handling continuous, discretized, and discrete data. However, BFNs cannot learn high-level semantic representation from the parameter space since {common encoders, which encode data into one static representation, cannot capture semantic changes in parameters.} This motivates a new direction: learning semantic representations hidden in the parameter spaces to characterize mixed-typed noisy data. {Accordingly, we propose a representation learning framework named ParamReL, which operates in the parameter space to obtain parameter-wise latent semantics that exhibit progressive structures. Specifically, ParamReL proposes a \emph{self-}encoder to learn latent semantics directly from parameters, rather than from observations. The encoder is then integrated into BFNs, enabling representation learning with various formats of observations. Mutual information terms further promote the disentanglement of latent semantics and capture meaningful semantics simultaneously.} We illustrate {conditional generation and reconstruction} in ParamReL via expanding BFNs, and extensive {quantitative} experimental results demonstrate the {superior effectiveness} of ParamReL in learning parameter representation.
Rethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition
Mar 03, 2024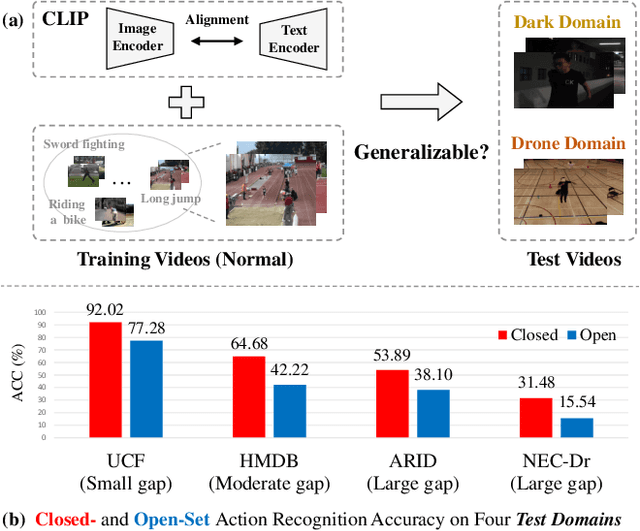
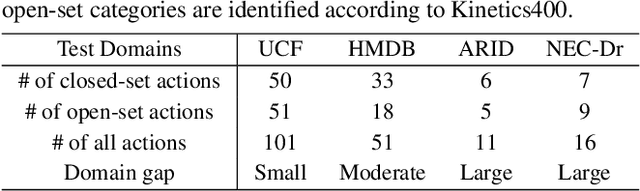
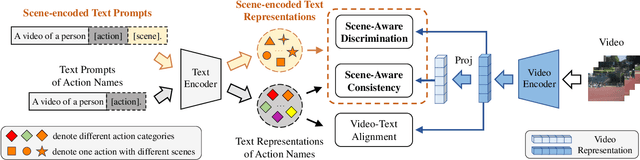
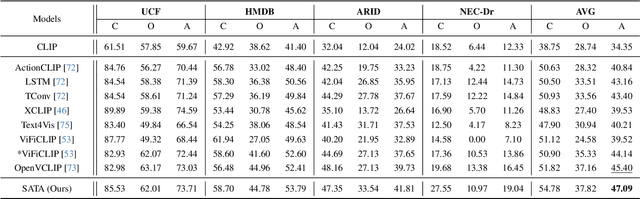
Contrastive Language-Image Pretraining (CLIP) has shown remarkable open-vocabulary abilities across various image understanding tasks. Building upon this impressive success, recent pioneer works have proposed to adapt the powerful CLIP to video data, leading to efficient and effective video learners for open-vocabulary action recognition. Inspired by the fact that humans perform actions in diverse environments, our work delves into an intriguing question: Can CLIP-based video learners effectively generalize to video domains they have not encountered during training? To answer this, we establish a CROSS-domain Open-Vocabulary Action recognition benchmark named XOV-Action, and conduct a comprehensive evaluation of five state-of-the-art CLIP-based video learners under various types of domain gaps. Our evaluation demonstrates that previous methods exhibit limited action recognition performance in unseen video domains, revealing potential challenges of the cross-domain open-vocabulary action recognition task. To address this task, our work focuses on a critical challenge, namely scene bias, and we accordingly contribute a novel scene-aware video-text alignment method. Our key idea is to distinguish video representations apart from scene-encoded text representations, aiming to learn scene-agnostic video representations for recognizing actions across domains. Extensive experimental results demonstrate the effectiveness of our method. The benchmark and code will be available at https://github.com/KunyuLin/XOV-Action/.
Out-of-Distribution Knowledge Distillation via Confidence Amendment
Nov 14, 2023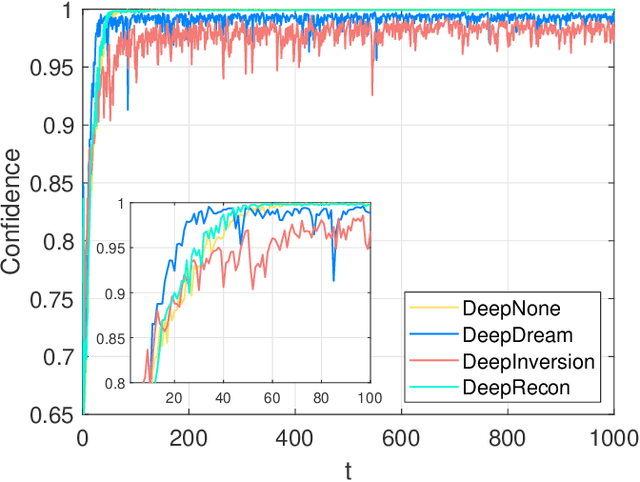
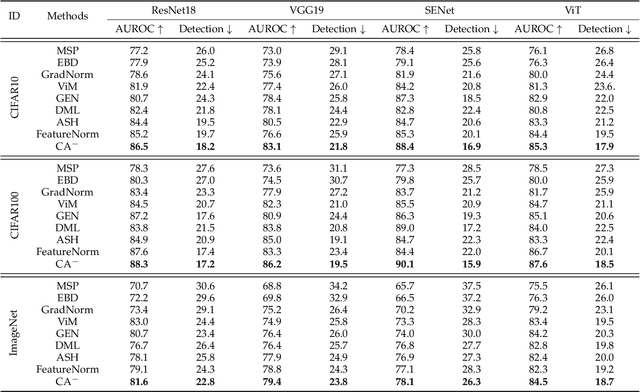
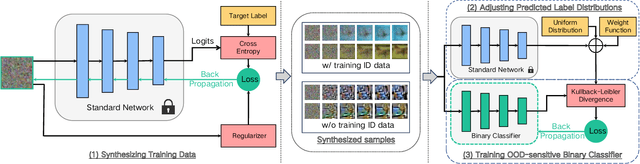
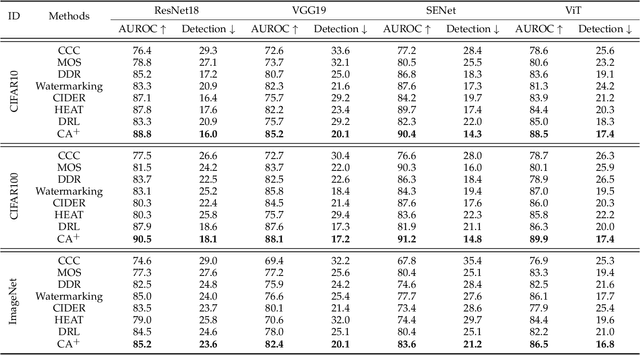
Out-of-distribution (OOD) detection is essential in identifying test samples that deviate from the in-distribution (ID) data upon which a standard network is trained, ensuring network robustness and reliability. This paper introduces OOD knowledge distillation, a pioneering learning framework applicable whether or not training ID data is available, given a standard network. This framework harnesses OOD-sensitive knowledge from the standard network to craft a binary classifier adept at distinguishing between ID and OOD samples. To accomplish this, we introduce Confidence Amendment (CA), an innovative methodology that transforms an OOD sample into an ID one while progressively amending prediction confidence derived from the standard network. This approach enables the simultaneous synthesis of both ID and OOD samples, each accompanied by an adjusted prediction confidence, thereby facilitating the training of a binary classifier sensitive to OOD. Theoretical analysis provides bounds on the generalization error of the binary classifier, demonstrating the pivotal role of confidence amendment in enhancing OOD sensitivity. Extensive experiments spanning various datasets and network architectures confirm the efficacy of the proposed method in detecting OOD samples.
R-divergence for Estimating Model-oriented Distribution Discrepancy
Oct 02, 2023Real-life data are often non-IID due to complex distributions and interactions, and the sensitivity to the distribution of samples can differ among learning models. Accordingly, a key question for any supervised or unsupervised model is whether the probability distributions of two given datasets can be considered identical. To address this question, we introduce R-divergence, designed to assess model-oriented distribution discrepancies. The core insight is that two distributions are likely identical if their optimal hypothesis yields the same expected risk for each distribution. To estimate the distribution discrepancy between two datasets, R-divergence learns a minimum hypothesis on the mixed data and then gauges the empirical risk difference between them. We evaluate the test power across various unsupervised and supervised tasks and find that R-divergence achieves state-of-the-art performance. To demonstrate the practicality of R-divergence, we employ R-divergence to train robust neural networks on samples with noisy labels.
Label and Distribution-discriminative Dual Representation Learning for Out-of-Distribution Detection
Jun 19, 2022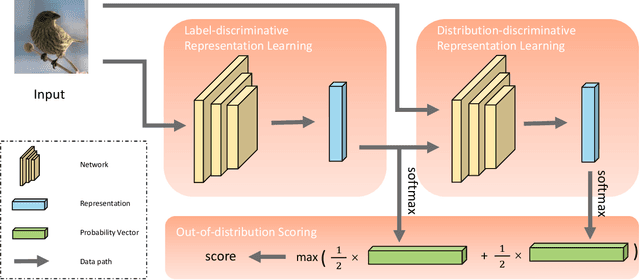
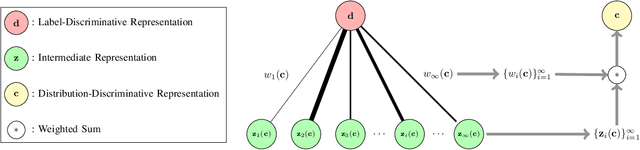
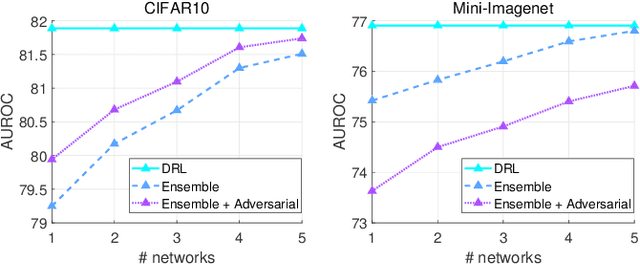
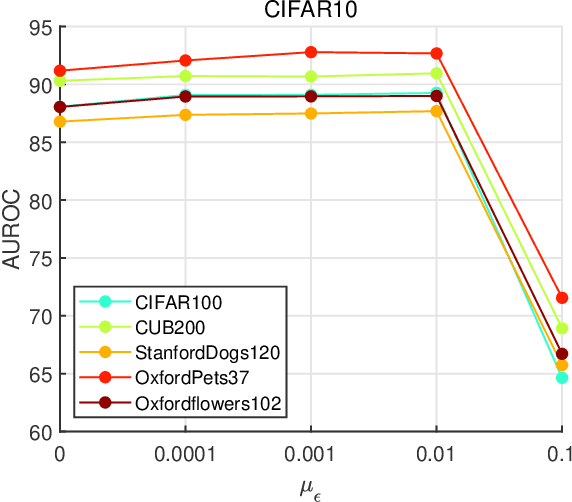
To classify in-distribution samples, deep neural networks learn label-discriminative representations, which, however, are not necessarily distribution-discriminative according to the information bottleneck. Therefore, trained networks could assign unexpected high-confidence predictions to out-of-distribution samples drawn from distributions differing from that of in-distribution samples. Specifically, networks extract the strongly label-related information from in-distribution samples to learn the label-discriminative representations but discard the weakly label-related information. Accordingly, networks treat out-of-distribution samples with minimum label-sensitive information as in-distribution samples. According to the different informativeness properties of in- and out-of-distribution samples, a Dual Representation Learning (DRL) method learns distribution-discriminative representations that are weakly related to the labeling of in-distribution samples and combines label- and distribution-discriminative representations to detect out-of-distribution samples. For a label-discriminative representation, DRL constructs the complementary distribution-discriminative representation by an implicit constraint, i.e., integrating diverse intermediate representations where an intermediate representation less similar to the label-discriminative representation owns a higher weight. Experiments show that DRL outperforms the state-of-the-art methods for out-of-distribution detection.