 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Knowledge-Driven Interpretable Vessel Trajectory Imputation via Large Language Models
Jan 11, 2026The Automatic Identification System provides critical information for maritime navigation and safety, yet its trajectories are often incomplete due to signal loss or deliberate tampering. Existing imputation methods emphasize trajectory recovery, paying limited attention to interpretability and failing to provide underlying knowledge that benefits downstream tasks such as anomaly detection and route planning. We propose knowledge-driven interpretable vessel trajectory imputation (VISTA), the first trajectory imputation framework that offers interpretability while simultaneously providing underlying knowledge to support downstream analysis. Specifically, we first define underlying knowledge as a combination of Structured Data-derived Knowledge (SDK) distilled from AIS data and Implicit LLM Knowledge acquired from large-scale Internet corpora. Second, to manage and leverage the SDK effectively at scale, we develop a data-knowledge-data loop that employs a Structured Data-derived Knowledge Graph for SDK extraction and knowledge-driven trajectory imputation. Third, to efficiently process large-scale AIS data, we introduce a workflow management layer that coordinates the end-to-end pipeline, enabling parallel knowledge extraction and trajectory imputation with anomaly handling and redundancy elimination. Experiments on two large AIS datasets show that VISTA is capable of state-of-the-art imputation accuracy and computational efficiency, improving over state-of-the-art baselines by 5%-94% and reducing time cost by 51%-93%, while producing interpretable knowledge cues that benefit downstream tasks. The source code and implementation details of VISTA are publicly available.
MSC-180: A Benchmark for Automated Formal Theorem Proving from Mathematical Subject Classification
Dec 20, 2025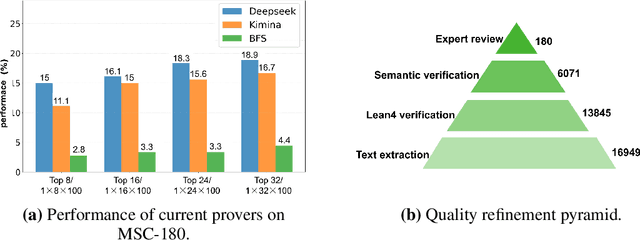



Automated Theorem Proving (ATP) represents a core research direction in artificial intelligence for achieving formal reasoning and verification, playing a significant role in advancing machine intelligence. However, current large language model (LLM)-based theorem provers suffer from limitations such as restricted domain coverage and weak generalization in mathematical reasoning. To address these issues, we propose MSC-180, a benchmark for evaluation based on the MSC2020 mathematical subject classification. It comprises 180 formal verification problems, 3 advanced problems from each of 60 mathematical branches, spanning from undergraduate to graduate levels. Each problem has undergone multiple rounds of verification and refinement by domain experts to ensure formal accuracy. Evaluations of state-of-the-art LLM-based theorem provers under the pass@32 setting reveal that the best model achieves only an 18.89% overall pass rate, with prominent issues including significant domain bias (maximum domain coverage 41.7%) and a difficulty gap (significantly lower pass rates on graduate-level problems). To further quantify performance variability across mathematical domains, we introduce the coefficient of variation (CV) as an evaluation metric. The observed CV values are 4-6 times higher than the statistical high-variability threshold, indicating that the models still rely on pattern matching from training corpora rather than possessing transferable reasoning mechanisms and systematic generalization capabilities. MSC-180, together with its multi-dimensional evaluation framework, provides a discriminative and systematic benchmark for driving the development of next-generation AI systems with genuine mathematical reasoning abilities.
Advancing Knowledge Tracing by Exploring Follow-up Performance Trends
Aug 11, 2025


Intelligent Tutoring Systems (ITS), such as Massive Open Online Courses, offer new opportunities for human learning. At the core of such systems, knowledge tracing (KT) predicts students' future performance by analyzing their historical learning activities, enabling an accurate evaluation of students' knowledge states over time. We show that existing KT methods often encounter correlation conflicts when analyzing the relationships between historical learning sequences and future performance. To address such conflicts, we propose to extract so-called Follow-up Performance Trends (FPTs) from historical ITS data and to incorporate them into KT. We propose a method called Forward-Looking Knowledge Tracing (FINER) that combines historical learning sequences with FPTs to enhance student performance prediction accuracy. FINER constructs learning patterns that facilitate the retrieval of FPTs from historical ITS data in linear time; FINER includes a novel similarity-aware attention mechanism that aggregates FPTs based on both frequency and contextual similarity; and FINER offers means of combining FPTs and historical learning sequences to enable more accurate prediction of student future performance. Experiments on six real-world datasets show that FINER can outperform ten state-of-the-art KT methods, increasing accuracy by 8.74% to 84.85%.
Automated Formalization via Conceptual Retrieval-Augmented LLMs
Aug 09, 2025



Interactive theorem provers (ITPs) require manual formalization, which is labor-intensive and demands expert knowledge. While automated formalization offers a potential solution, it faces two major challenges: model hallucination (e.g., undefined predicates, symbol misuse, and version incompatibility) and the semantic gap caused by ambiguous or missing premises in natural language descriptions. To address these issues, we propose CRAMF, a Concept-driven Retrieval-Augmented Mathematical Formalization framework. CRAMF enhances LLM-based autoformalization by retrieving formal definitions of core mathematical concepts, providing contextual grounding during code generation. However, applying retrieval-augmented generation (RAG) in this setting is non-trivial due to the lack of structured knowledge bases, the polymorphic nature of mathematical concepts, and the high precision required in formal retrieval. We introduce a framework for automatically constructing a concept-definition knowledge base from Mathlib4, the standard mathematical library for the Lean 4 theorem prover, indexing over 26,000 formal definitions and 1,000+ core mathematical concepts. To address conceptual polymorphism, we propose contextual query augmentation with domain- and application-level signals. In addition, we design a dual-channel hybrid retrieval strategy with reranking to ensure accurate and relevant definition retrieval. Experiments on miniF2F, ProofNet, and our newly proposed AdvancedMath benchmark show that CRAMF can be seamlessly integrated into LLM-based autoformalizers, yielding consistent improvements in translation accuracy, achieving up to 62.1% and an average of 29.9% relative improvement.
MH-GIN: Multi-scale Heterogeneous Graph-based Imputation Network for AIS Data (Extended Version)
Jul 27, 2025Location-tracking data from the Automatic Identification System, much of which is publicly available, plays a key role in a range of maritime safety and monitoring applications. However, the data suffers from missing values that hamper downstream applications. Imputing the missing values is challenging because the values of different heterogeneous attributes are updated at diverse rates, resulting in the occurrence of multi-scale dependencies among attributes. Existing imputation methods that assume similar update rates across attributes are unable to capture and exploit such dependencies, limiting their imputation accuracy. We propose MH-GIN, a Multi-scale Heterogeneous Graph-based Imputation Network that aims improve imputation accuracy by capturing multi-scale dependencies. Specifically, MH-GIN first extracts multi-scale temporal features for each attribute while preserving their intrinsic heterogeneous characteristics. Then, it constructs a multi-scale heterogeneous graph to explicitly model dependencies between heterogeneous attributes to enable more accurate imputation of missing values through graph propagation. Experimental results on two real-world datasets find that MH-GIN is capable of an average 57% reduction in imputation errors compared to state-of-the-art methods, while maintaining computational efficiency. The source code and implementation details of MH-GIN are publicly available https://github.com/hyLiu1994/MH-GIN.
EndoGen: Conditional Autoregressive Endoscopic Video Generation
Jul 23, 2025Endoscopic video generation is crucial for advancing medical imaging and enhancing diagnostic capabilities. However, prior efforts in this field have either focused on static images, lacking the dynamic context required for practical applications, or have relied on unconditional generation that fails to provide meaningful references for clinicians. Therefore, in this paper, we propose the first conditional endoscopic video generation framework, namely EndoGen. Specifically, we build an autoregressive model with a tailored Spatiotemporal Grid-Frame Patterning (SGP) strategy. It reformulates the learning of generating multiple frames as a grid-based image generation pattern, which effectively capitalizes the inherent global dependency modeling capabilities of autoregressive architectures. Furthermore, we propose a Semantic-Aware Token Masking (SAT) mechanism, which enhances the model's ability to produce rich and diverse content by selectively focusing on semantically meaningful regions during the generation process. Through extensive experiments, we demonstrate the effectiveness of our framework in generating high-quality, conditionally guided endoscopic content, and improves the performance of downstream task of polyp segmentation. Code released at https://www.github.com/CUHK-AIM-Group/EndoGen.
WonderFree: Enhancing Novel View Quality and Cross-View Consistency for 3D Scene Exploration
Jun 25, 2025Interactive 3D scene generation from a single image has gained significant attention due to its potential to create immersive virtual worlds. However, a key challenge in current 3D generation methods is the limited explorability, which cannot render high-quality images during larger maneuvers beyond the original viewpoint, particularly when attempting to move forward into unseen areas. To address this challenge, we propose WonderFree, the first model that enables users to interactively generate 3D worlds with the freedom to explore from arbitrary angles and directions. Specifically, we decouple this challenge into two key subproblems: novel view quality, which addresses visual artifacts and floating issues in novel views, and cross-view consistency, which ensures spatial consistency across different viewpoints. To enhance rendering quality in novel views, we introduce WorldRestorer, a data-driven video restoration model designed to eliminate floaters and artifacts. In addition, a data collection pipeline is presented to automatically gather training data for WorldRestorer, ensuring it can handle scenes with varying styles needed for 3D scene generation. Furthermore, to improve cross-view consistency, we propose ConsistView, a multi-view joint restoration mechanism that simultaneously restores multiple perspectives while maintaining spatiotemporal coherence. Experimental results demonstrate that WonderFree not only enhances rendering quality across diverse viewpoints but also significantly improves global coherence and consistency. These improvements are confirmed by CLIP-based metrics and a user study showing a 77.20% preference for WonderFree over WonderWorld enabling a seamless and immersive 3D exploration experience. The code, model, and data will be publicly available.
LearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
Jun 13, 2025Reinforcement learning (RL) has become a key technique for enhancing LLMs' reasoning abilities, yet its data inefficiency remains a major bottleneck. To address this critical yet challenging issue, we present a novel gradient-alignment-based method, named LearnAlign, which intelligently selects the learnable and representative training reasoning data for RL post-training. To overcome the well-known issue of response-length bias in gradient norms, we introduce the data learnability based on the success rate, which can indicate the learning potential of each data point. Experiments across three mathematical reasoning benchmarks demonstrate that our method significantly reduces training data requirements while achieving minor performance degradation or even improving performance compared to full-data training. For example, it reduces data requirements by up to 1,000 data points with better performance (77.53%) than that on the full dataset on GSM8K benchmark (77.04%). Furthermore, we show its effectiveness in the staged RL setting. This work provides valuable insights into data-efficient RL post-training and establishes a foundation for future research in optimizing reasoning data selection.To facilitate future work, we will release code.
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025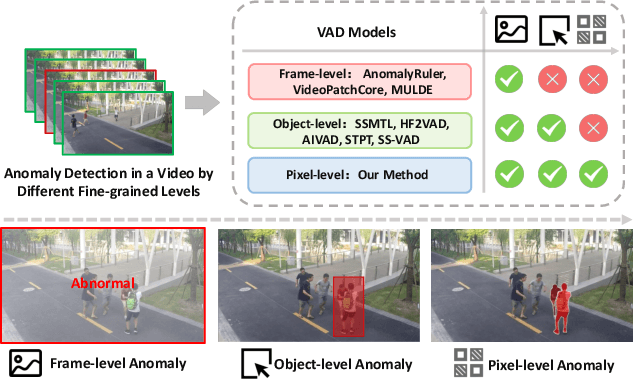
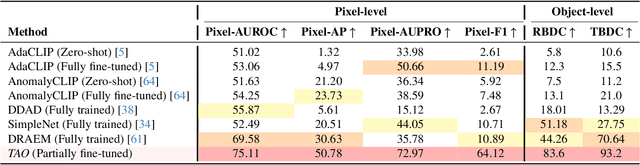
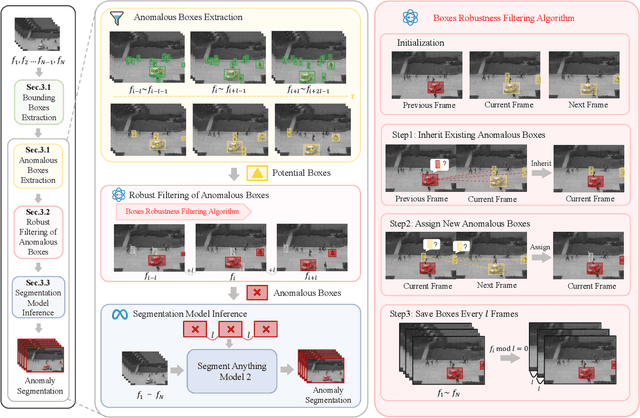

Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.
FlexGS: Train Once, Deploy Everywhere with Many-in-One Flexible 3D Gaussian Splatting
Jun 04, 20253D Gaussian splatting (3DGS) has enabled various applications in 3D scene representation and novel view synthesis due to its efficient rendering capabilities. However, 3DGS demands relatively significant GPU memory, limiting its use on devices with restricted computational resources. Previous approaches have focused on pruning less important Gaussians, effectively compressing 3DGS but often requiring a fine-tuning stage and lacking adaptability for the specific memory needs of different devices. In this work, we present an elastic inference method for 3DGS. Given an input for the desired model size, our method selects and transforms a subset of Gaussians, achieving substantial rendering performance without additional fine-tuning. We introduce a tiny learnable module that controls Gaussian selection based on the input percentage, along with a transformation module that adjusts the selected Gaussians to complement the performance of the reduced model. Comprehensive experiments on ZipNeRF, MipNeRF and Tanks\&Temples scenes demonstrate the effectiveness of our approach. Code is available at https://flexgs.github.io.