 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAD-R1: Eliciting Consistent Reasoning in Interpretible Medical Anomaly Detection via Consistency-Reinforced Policy Optimization
Feb 01, 2026Medical Anomaly Detection (MedAD) presents a significant opportunity to enhance diagnostic accuracy using Large Multimodal Models (LMMs) to interpret and answer questions based on medical images. However, the reliance on Supervised Fine-Tuning (SFT) on simplistic and fragmented datasets has hindered the development of models capable of plausible reasoning and robust multimodal generalization. To overcome this, we introduce MedAD-38K, the first large-scale, multi-modal, and multi-center benchmark for MedAD featuring diagnostic Chain-of-Thought (CoT) annotations alongside structured Visual Question-Answering (VQA) pairs. On this foundation, we propose a two-stage training framework. The first stage, Cognitive Injection, uses SFT to instill foundational medical knowledge and align the model with a structured think-then-answer paradigm. Given that standard policy optimization can produce reasoning that is disconnected from the final answer, the second stage incorporates Consistency Group Relative Policy Optimization (Con-GRPO). This novel algorithm incorporates a crucial consistency reward to ensure the generated reasoning process is relevant and logically coherent with the final diagnosis. Our proposed model, MedAD-R1, achieves state-of-the-art (SOTA) performance on the MedAD-38K benchmark, outperforming strong baselines by more than 10\%. This superior performance stems from its ability to generate transparent and logically consistent reasoning pathways, offering a promising approach to enhancing the trustworthiness and interpretability of AI for clinical decision support.
Enabling High-Frequency Cross-Modality Visual Positioning Service for Accurate Drone Landing
Oct 01, 2025After years of growth, drone-based delivery is transforming logistics. At its core, real-time 6-DoF drone pose tracking enables precise flight control and accurate drone landing. With the widespread availability of urban 3D maps, the Visual Positioning Service (VPS), a mobile pose estimation system, has been adapted to enhance drone pose tracking during the landing phase, as conventional systems like GPS are unreliable in urban environments due to signal attenuation and multi-path propagation. However, deploying the current VPS on drones faces limitations in both estimation accuracy and efficiency. In this work, we redesign drone-oriented VPS with the event camera and introduce EV-Pose to enable accurate, high-frequency 6-DoF pose tracking for accurate drone landing. EV-Pose introduces a spatio-temporal feature-instructed pose estimation module that extracts a temporal distance field to enable 3D point map matching for pose estimation; and a motion-aware hierarchical fusion and optimization scheme to enhance the above estimation in accuracy and efficiency, by utilizing drone motion in the \textit{early stage} of event filtering and the \textit{later stage} of pose optimization. Evaluation shows that EV-Pose achieves a rotation accuracy of 1.34$\degree$ and a translation accuracy of 6.9$mm$ with a tracking latency of 10.08$ms$, outperforming baselines by $>$50\%, \tmcrevise{thus enabling accurate drone landings.} Demo: https://ev-pose.github.io/
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025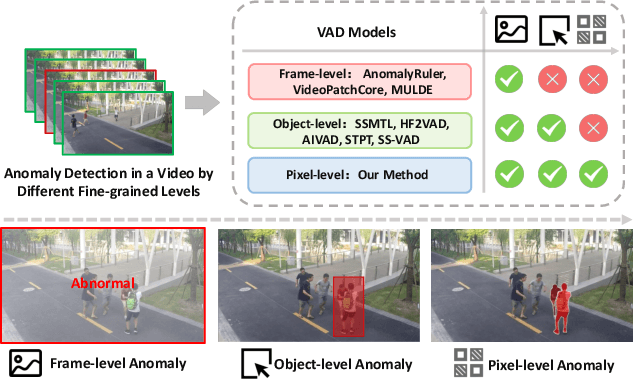
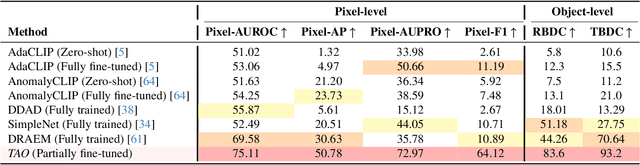
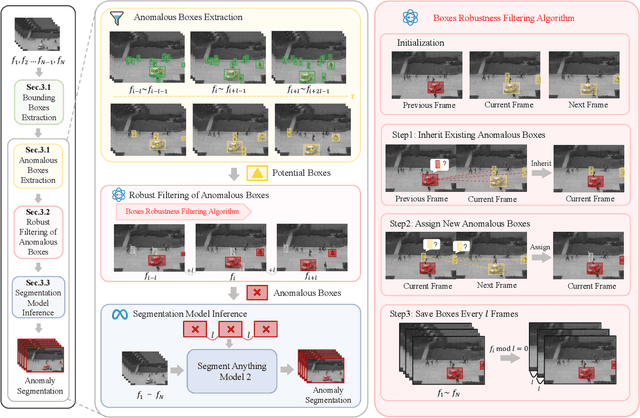

Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Structure-guided Deep Multi-View Clustering
Jan 17, 2025Deep multi-view clustering seeks to utilize the abundant information from multiple views to improve clustering performance. However, most of the existing clustering methods often neglect to fully mine multi-view structural information and fail to explore the distribution of multi-view data, limiting clustering performance. To address these limitations, we propose a structure-guided deep multi-view clustering model. Specifically, we introduce a positive sample selection strategy based on neighborhood relationships, coupled with a corresponding loss function. This strategy constructs multi-view nearest neighbor graphs to dynamically redefine positive sample pairs, enabling the mining of local structural information within multi-view data and enhancing the reliability of positive sample selection. Additionally, we introduce a Gaussian distribution model to uncover latent structural information and introduce a loss function to reduce discrepancies between view embeddings. These two strategies explore multi-view structural information and data distribution from different perspectives, enhancing consistency across views and increasing intra-cluster compactness. Experimental evaluations demonstrate the efficacy of our method, showing significant improvements in clustering performance on multiple benchmark datasets compared to state-of-the-art multi-view clustering approaches.
MedGo: A Chinese Medical Large Language Model
Oct 27, 2024Large models are a hot research topic in the field of artificial intelligence. Leveraging their generative capabilities has the potential to enhance the level and quality of medical services. In response to the limitations of current large language models, which often struggle with accuracy and have narrow capabilities in medical applications, this paper presents a Chinese medical large language model, MedGo. MedGo was trained using a combination of high quality unsupervised medical data, supervised data, and preference alignment data, aimed at enhancing both its versatility and precision in medical tasks. The model was evaluated through the public CBLUE benchmark and a manually constructed dataset ClinicalQA. The results demonstrate that MedGo achieved promising performance across various Chinese medical information processing tasks, achieved the first place in the CBLUE evaluation. Additionally, on our constructed dataset ClinicalQA, MedGo outperformed its base model Qwen2, highlighting its potential to improve both automated medical question answering and clinical decision support. These experimental results demonstrate that MedGo possesses strong information processing capabilities in the medical field. At present, we have successfully deployed MedGo at Shanghai East Hospital.
DLRover: An Elastic Deep Training Extension with Auto Job Resource Recommendation
Apr 04, 2023The cloud is still a popular platform for distributed deep learning (DL) training jobs since resource sharing in the cloud can improve resource utilization and reduce overall costs. However, such sharing also brings multiple challenges for DL training jobs, e.g., high-priority jobs could impact, even interrupt, low-priority jobs. Meanwhile, most existing distributed DL training systems require users to configure the resources (i.e., the number of nodes and resources like CPU and memory allocated to each node) of jobs manually before job submission and can not adjust the job's resources during the runtime. The resource configuration of a job deeply affect this job's performance (e.g., training throughput, resource utilization, and completion rate). However, this usually leads to poor performance of jobs since users fail to provide optimal resource configuration in most cases. \system~is a distributed DL framework can auto-configure a DL job's initial resources and dynamically tune the job's resources to win the better performance. With elastic capability, \system~can effectively adjusts the resources of a job when there are performance issues detected or a job fails because of faults or eviction. Evaluations results show \system~can outperform manual well-tuned resource configurations. Furthermore, in the production Kubernetes cluster of \company, \system~reduces the medium of job completion time by 31\%, and improves the job completion rate by 6\%, CPU utilization by 15\%, and memory utilization by 20\% compared with manual configuration.
RPT++: Customized Feature Representation for Siamese Visual Tracking
Oct 23, 2021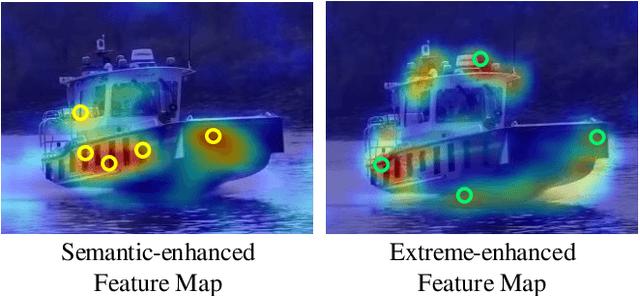

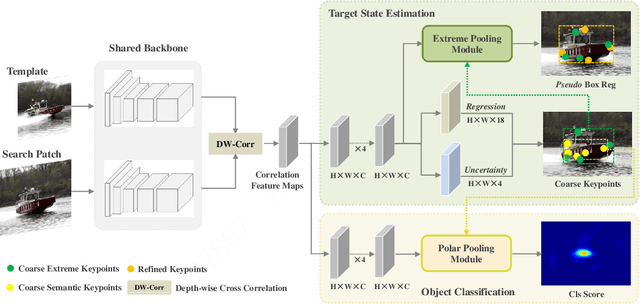

While recent years have witnessed remarkable progress in the feature representation of visual tracking, the problem of feature misalignment between the classification and regression tasks is largely overlooked. The approaches of feature extraction make no difference for these two tasks in most of advanced trackers. We argue that the performance gain of visual tracking is limited since features extracted from the salient area provide more recognizable visual patterns for classification, while these around the boundaries contribute to accurately estimating the target state. We address this problem by proposing two customized feature extractors, named polar pooling and extreme pooling to capture task-specific visual patterns. Polar pooling plays the role of enriching information collected from the semantic keypoints for stronger classification, while extreme pooling facilitates explicit visual patterns of the object boundary for accurate target state estimation. We demonstrate the effectiveness of the task-specific feature representation by integrating it into the recent and advanced tracker RPT. Extensive experiments on several benchmarks show that our Customized Features based RPT (RPT++) achieves new state-of-the-art performances on OTB-100, VOT2018, VOT2019, GOT-10k, TrackingNet and LaSOT.
RPT: Learning Point Set Representation for Siamese Visual Tracking
Sep 02, 2020

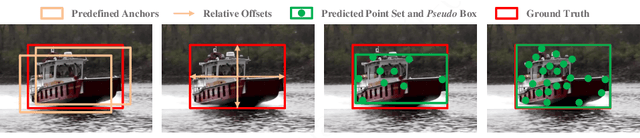
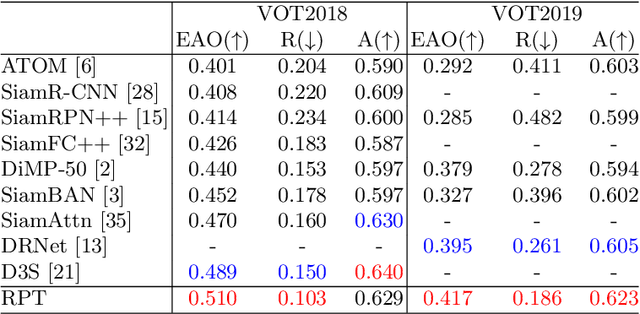
While remarkable progress has been made in robust visual tracking, accurate target state estimation still remains a highly challenging problem. In this paper, we argue that this issue is closely related to the prevalent bounding box representation, which provides only a coarse spatial extent of object. Thus an effcient visual tracking framework is proposed to accurately estimate the target state with a finer representation as a set of representative points. The point set is trained to indicate the semantically and geometrically significant positions of target region, enabling more fine-grained localization and modeling of object appearance. We further propose a multi-level aggregation strategy to obtain detailed structure information by fusing hierarchical convolution layers. Extensive experiments on several challenging benchmarks including OTB2015, VOT2018, VOT2019 and GOT-10k demonstrate that our method achieves new state-of-the-art performance while running at over 20 FPS.
1D-Convolutional Capsule Network for Hyperspectral Image Classification
Mar 23, 2019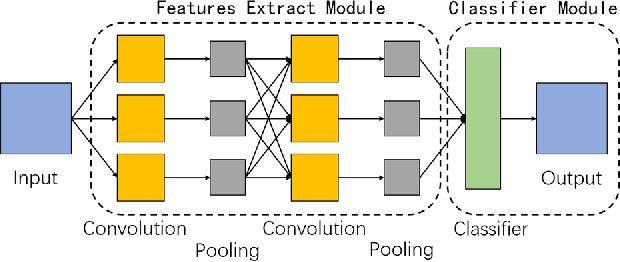
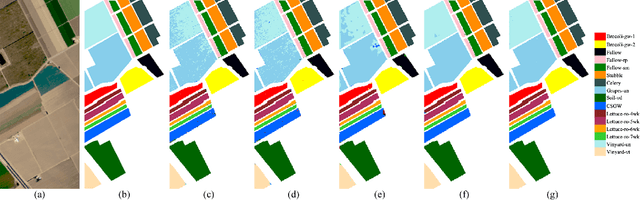

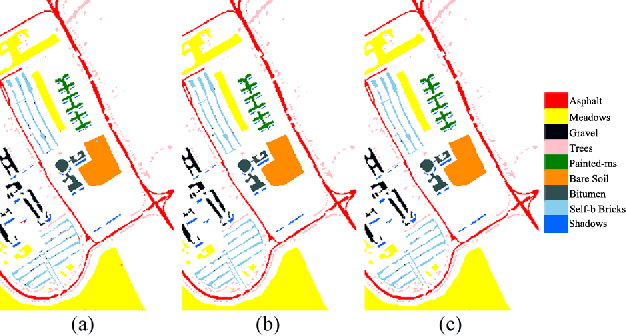
Recently, convolutional neural networks (CNNs) have achieved excellent performances in many computer vision tasks. Specifically, for hyperspectral images (HSIs) classification, CNNs often require very complex structure due to the high dimension of HSIs. The complex structure of CNNs results in prohibitive training efforts. Moreover, the common situation in HSIs classification task is the lack of labeled samples, which results in accuracy deterioration of CNNs. In this work, we develop an easy-to-implement capsule network to alleviate the aforementioned problems, i.e., 1D-convolution capsule network (1D-ConvCapsNet). Firstly, 1D-ConvCapsNet separately extracts spatial and spectral information on spatial and spectral domains, which is more lightweight than 3D-convolution due to fewer parameters. Secondly, 1D-ConvCapsNet utilizes the capsule-wise constraint window method to reduce parameter amount and computational complexity of conventional capsule network. Finally, 1D-ConvCapsNet obtains accurate predictions with respect to input samples via dynamic routing. The effectiveness of the 1D-ConvCapsNet is verified by three representative HSI datasets. Experimental results demonstrate that 1D-ConvCapsNet is superior to state-of-the-art methods in both the accuracy and training effort.