 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoFormer: A controllable feature-rich polyphonic music generation method
Oct 15, 2023
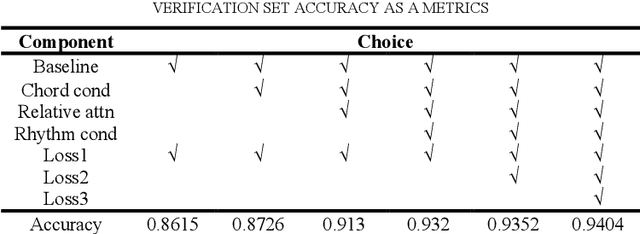
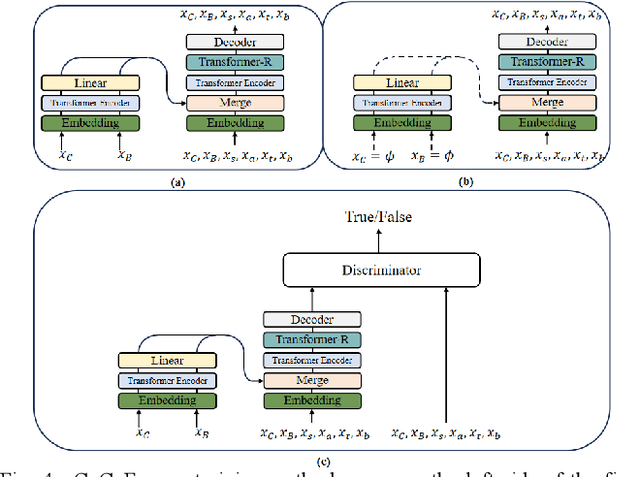
This paper explores the modeling method of polyphonic music sequence. Due to the great potential of Transformer models in music generation, controllable music generation is receiving more attention. In the task of polyphonic music, current controllable generation research focuses on controlling the generation of chords, but lacks precise adjustment for the controllable generation of choral music textures. This paper proposed Condition Choir Transformer (CoCoFormer) which controls the output of the model by controlling the chord and rhythm inputs at a fine-grained level. In this paper, the self-supervised method improves the loss function and performs joint training through conditional control input and unconditional input training. In order to alleviate the lack of diversity on generated samples caused by the teacher forcing training, this paper added an adversarial training method. CoCoFormer enhances model performance with explicit and implicit inputs to chords and rhythms. In this paper, the experiments proves that CoCoFormer has reached the current better level than current models. On the premise of specifying the polyphonic music texture, the same melody can also be generated in a variety of ways.
Choir Transformer: Generating Polyphonic Music with Relative Attention on Transformer
Aug 01, 2023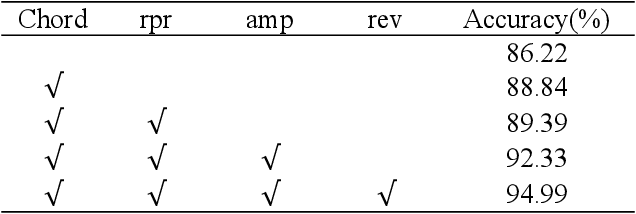
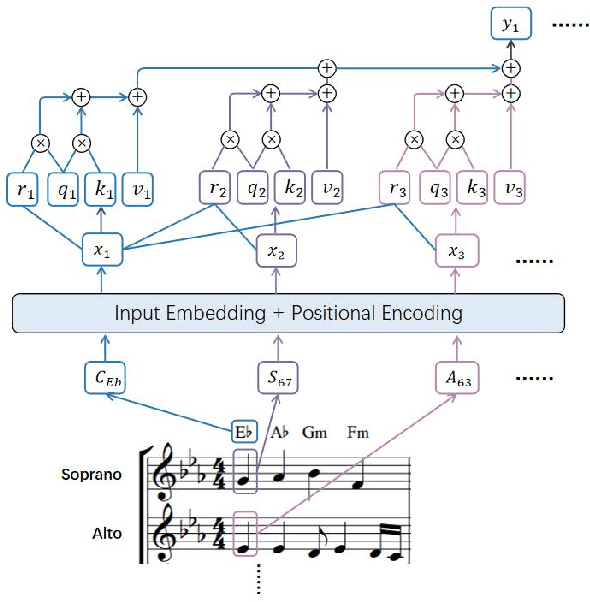
Polyphonic music generation is still a challenge direction due to its correct between generating melody and harmony. Most of the previous studies used RNN-based models. However, the RNN-based models are hard to establish the relationship between long-distance notes. In this paper, we propose a polyphonic music generation neural network named Choir Transformer[ https://github.com/Zjy0401/choir-transformer], with relative positional attention to better model the structure of music. We also proposed a music representation suitable for polyphonic music generation. The performance of Choir Transformer surpasses the previous state-of-the-art accuracy of 4.06%. We also measures the harmony metrics of polyphonic music. Experiments show that the harmony metrics are close to the music of Bach. In practical application, the generated melody and rhythm can be adjusted according to the specified input, with different styles of music like folk music or pop music and so on.
1D-Convolutional Capsule Network for Hyperspectral Image Classification
Mar 23, 2019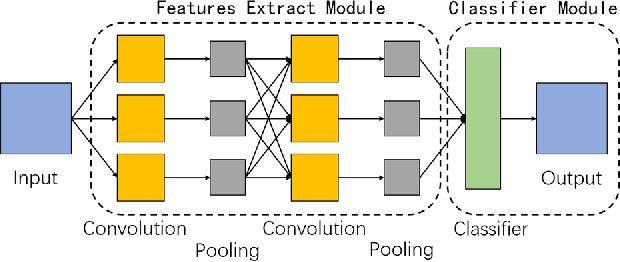
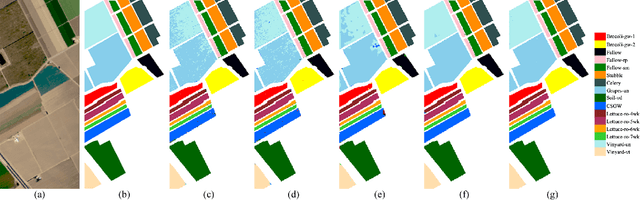

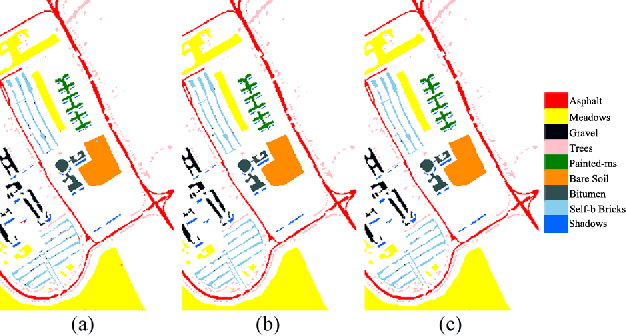
Recently, convolutional neural networks (CNNs) have achieved excellent performances in many computer vision tasks. Specifically, for hyperspectral images (HSIs) classification, CNNs often require very complex structure due to the high dimension of HSIs. The complex structure of CNNs results in prohibitive training efforts. Moreover, the common situation in HSIs classification task is the lack of labeled samples, which results in accuracy deterioration of CNNs. In this work, we develop an easy-to-implement capsule network to alleviate the aforementioned problems, i.e., 1D-convolution capsule network (1D-ConvCapsNet). Firstly, 1D-ConvCapsNet separately extracts spatial and spectral information on spatial and spectral domains, which is more lightweight than 3D-convolution due to fewer parameters. Secondly, 1D-ConvCapsNet utilizes the capsule-wise constraint window method to reduce parameter amount and computational complexity of conventional capsule network. Finally, 1D-ConvCapsNet obtains accurate predictions with respect to input samples via dynamic routing. The effectiveness of the 1D-ConvCapsNet is verified by three representative HSI datasets. Experimental results demonstrate that 1D-ConvCapsNet is superior to state-of-the-art methods in both the accuracy and training effort.