 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTUDSR: Twice Upsampling-Diffusion for Higher Super-Resolution
Jun 08, 2026Diffusion-based generative models have achieved remarkable success in real-world image super-resolution (SR). With tiled diffusion techniques, these models can produce high-resolution images that exceed their native-supported resolution. However, the quality of such high-resolution (e.g $2048^2$) outputs often remains extremely poor, primarily due to two factors we consider: the image upsampling ratio (e.g $\times8$) exceeding the model's native-supported upsampling ratio (e.g $\times4$), and the model's native-supported resolution. In practice, training a native high-resolution model requires larger architectures, which incur significant computational overhead and GPU memory costs, making it hard on limited-resource equipment. Thus, we present TUDSR, a Twice Upsampling-Diffusion framework for higher SR. The TUDSR framework mainly consists of two stages: the first involves training at $R$-resolution, and the second introduces a looped chunk-based training strategy at $NR$-resolution. Each stage adapts a one-step GAN architecture comprising a generator and a discriminator. Based on SD2.1-base, we develop TUDSR-S, which achieves state-of-the-art performance across multiple benchmarks. Extensive experiments further demonstrate that TUDSR-S generates high-quality images at the resolutions of $1024^2$ and even $2048^2$, significantly outperforming existing approaches. Code is available at https://github.com/wuer5/TUDSR.
Learning While Acting: A Skill-Enhanced Test-Time Co-Evolution Framework for Online Lifelong Learning Agents
Jun 03, 2026Lifelong learning is essential for Large Language Model (LLM) agents operating in dynamic, interactive environments. However, existing lifelong learning agents for long-horizon tasks typically depend on discrete skill or past experiences retrieval with static parameters during inference, which prevents them from continuously internalizing test-time feedback like human learners. To bridge this gap, we propose Skill-enhanced Test-Time Co-Evolution (\texttt{LifeSkill}), a two-stage reinforcement learning framework for Online Lifelong Learning Agents. Specifically, we design Verifier-Guided Skill Learning that addresses the lack of direct supervision for skill extraction by rewarding candidate skills according to the average verifier success of multiple skill-conditioned policy rollouts, encouraging the model to generate skills that are useful for solving tasks rather than merely plausible in text. Furthermore, we introduce Online Skill Internalization, which continuously improves the policy model during test-time interaction by transforming skill-conditioned trajectories into reward signals. This enables the agent to directly internalize reasoning capabilities into its parameters, avoiding the context bloat of experience retrieval. Experiments on LifelongAgentBench show that LifeSkill improves average performance by 7 absolute points by comparing with existing lifelong agent baselines.
The Sword, Shield, and Achilles' Heel: Characterizing the Linguistic Inductive Bias of Large Language Models for Spatial Reasoning in Navigation Planning
May 29, 2026Large Language Model (LLM)-based navigation systems commonly construct explicit spatial representations (e.g., topological graphs, semantic raster maps) and translate them into textual descriptions as LLMs' inputs. However, the linguistic structures of such text-based spatial representations and the choices of contextual features (e.g., topology, geometry) they contain are often treated as neutral engineering decisions rather than key factors that shape LLMs' behavior. To fill the gap, we propose a dual-interventional framework that disentangles linguistic structures from different contextual cues to evaluate the linguistic inductive bias of LLMs for navigation planning. In the framework, representation intervention varies the linguistic format and the degree of linguistic compression, clarifying when linguistic representations support or inhibit navigation planning. Context intervention, combined with contextual feature combination and conflict probing, explicitly clarifies the preferences and weaknesses of LLMs when processing different contextual cues. Experiments across diverse spatial reasoning tasks and multiple model scales reveal a consistent pattern: topological information is a sturdy shield and the backbone of robust planning; linguistic format is a double-edged sword whose effect depends on model size, task demands, and the compression level; and semantic information is a fatal Achilles' heel -- incorrect semantic cues can systematically derail the planning process. Overall, our study shows that effective text-based spatial representations in LLM-based navigation should preserve topological integrity, calibrate representational compression to model capacity, and ensure semantic correctness, rather than simply adopting a single representation. Our code is publicly available at https://github.com/jonesdong150/LLM-Navigation-Inductive-Bias.
Automatic Paper Reviewing with Heterogeneous Graph Reasoning over LLM-Simulated Reviewer-Author Debates
Nov 11, 2025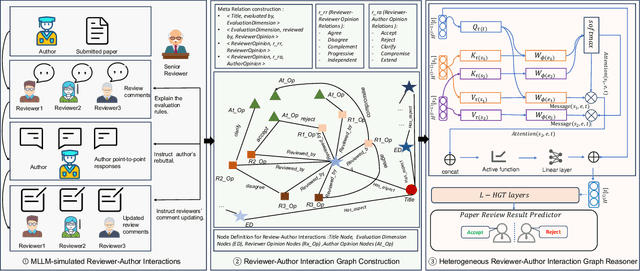
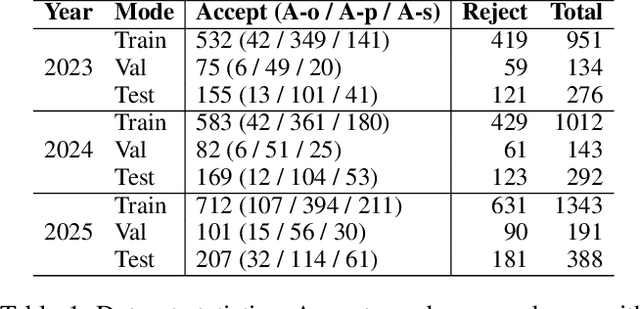
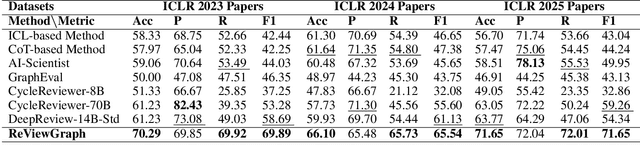
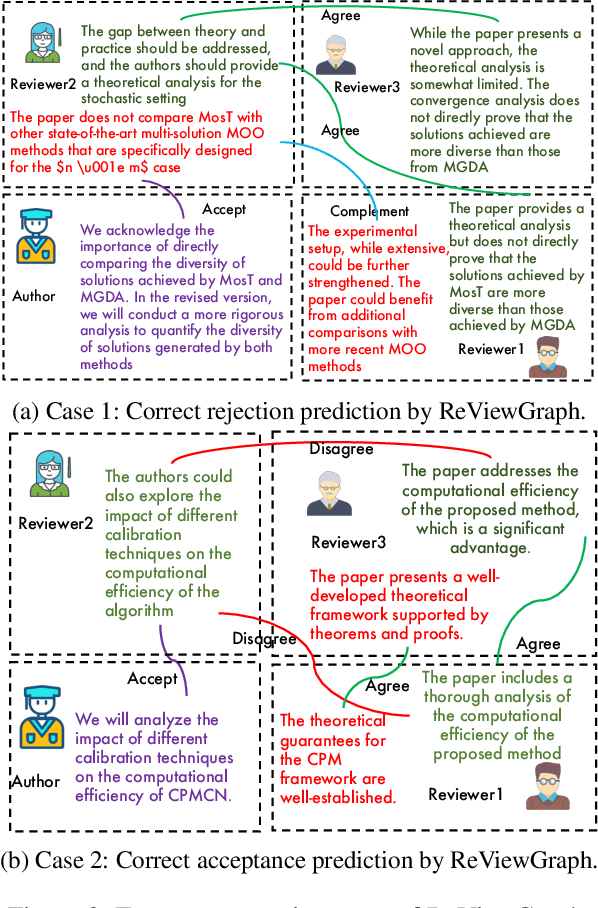
Existing paper review methods often rely on superficial manuscript features or directly on large language models (LLMs), which are prone to hallucinations, biased scoring, and limited reasoning capabilities. Moreover, these methods often fail to capture the complex argumentative reasoning and negotiation dynamics inherent in reviewer-author interactions. To address these limitations, we propose ReViewGraph (Reviewer-Author Debates Graph Reasoner), a novel framework that performs heterogeneous graph reasoning over LLM-simulated multi-round reviewer-author debates. In our approach, reviewer-author exchanges are simulated through LLM-based multi-agent collaboration. Diverse opinion relations (e.g., acceptance, rejection, clarification, and compromise) are then explicitly extracted and encoded as typed edges within a heterogeneous interaction graph. By applying graph neural networks to reason over these structured debate graphs, ReViewGraph captures fine-grained argumentative dynamics and enables more informed review decisions. Extensive experiments on three datasets demonstrate that ReViewGraph outperforms strong baselines with an average relative improvement of 15.73%, underscoring the value of modeling detailed reviewer-author debate structures.
OMGSR: You Only Need One Mid-timestep Guidance for Real-World Image Super-Resolution
Aug 11, 2025Denoising Diffusion Probabilistic Models (DDPM) and Flow Matching (FM) generative models show promising potential for one-step Real-World Image Super-Resolution (Real-ISR). Recent one-step Real-ISR models typically inject a Low-Quality (LQ) image latent distribution at the initial timestep. However, a fundamental gap exists between the LQ image latent distribution and the Gaussian noisy latent distribution, limiting the effective utilization of generative priors. We observe that the noisy latent distribution at DDPM/FM mid-timesteps aligns more closely with the LQ image latent distribution. Based on this insight, we present One Mid-timestep Guidance Real-ISR (OMGSR), a universal framework applicable to DDPM/FM-based generative models. OMGSR injects the LQ image latent distribution at a pre-computed mid-timestep, incorporating the proposed Latent Distribution Refinement loss to alleviate the latent distribution gap. We also design the Overlap-Chunked LPIPS/GAN loss to eliminate checkerboard artifacts in image generation. Within this framework, we instantiate OMGSR for DDPM/FM-based generative models with two variants: OMGSR-S (SD-Turbo) and OMGSR-F (FLUX.1-dev). Experimental results demonstrate that OMGSR-S/F achieves balanced/excellent performance across quantitative and qualitative metrics at 512-resolution. Notably, OMGSR-F establishes overwhelming dominance in all reference metrics. We further train a 1k-resolution OMGSR-F to match the default resolution of FLUX.1-dev, which yields excellent results, especially in the details of the image generation. We also generate 2k-resolution images by the 1k-resolution OMGSR-F using our two-stage Tiled VAE & Diffusion.
NeuroLoc: Encoding Navigation Cells for 6-DOF Camera Localization
May 02, 2025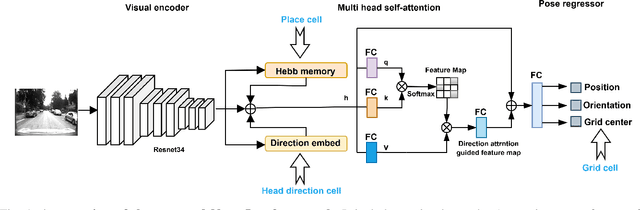
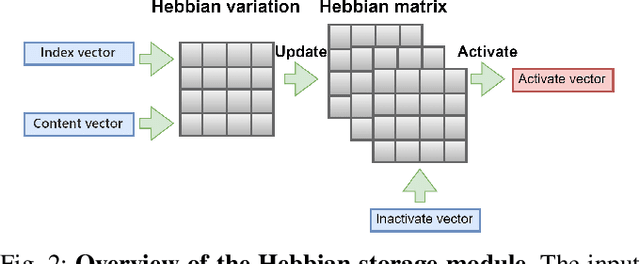
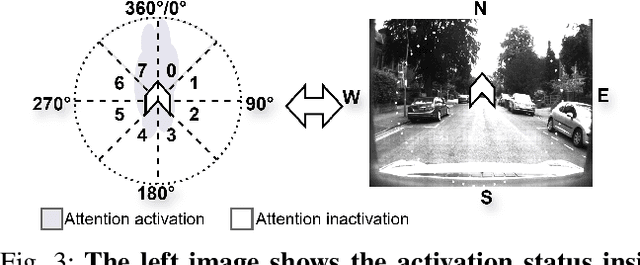
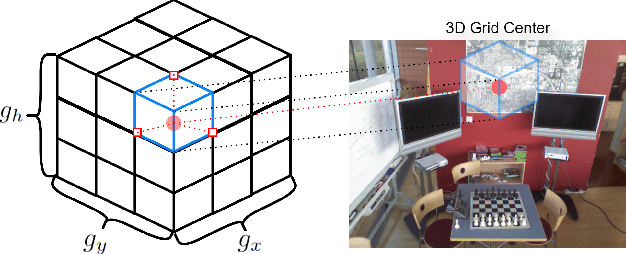
Recently, camera localization has been widely adopted in autonomous robotic navigation due to its efficiency and convenience. However, autonomous navigation in unknown environments often suffers from scene ambiguity, environmental disturbances, and dynamic object transformation in camera localization. To address this problem, inspired by the biological brain navigation mechanism (such as grid cells, place cells, and head direction cells), we propose a novel neurobiological camera location method, namely NeuroLoc. Firstly, we designed a Hebbian learning module driven by place cells to save and replay historical information, aiming to restore the details of historical representations and solve the issue of scene fuzziness. Secondly, we utilized the head direction cell-inspired internal direction learning as multi-head attention embedding to help restore the true orientation in similar scenes. Finally, we added a 3D grid center prediction in the pose regression module to reduce the final wrong prediction. We evaluate the proposed NeuroLoc on commonly used benchmark indoor and outdoor datasets. The experimental results show that our NeuroLoc can enhance the robustness in complex environments and improve the performance of pose regression by using only a single image.
Lipschitz Constant Meets Condition Number: Learning Robust and Compact Deep Neural Networks
Mar 26, 2025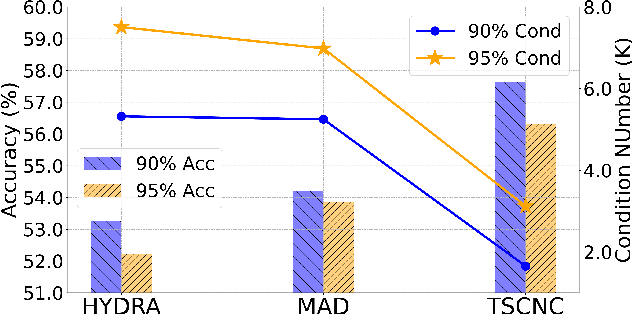
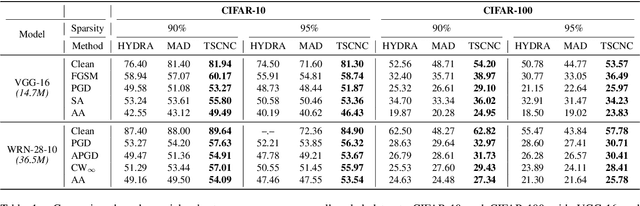
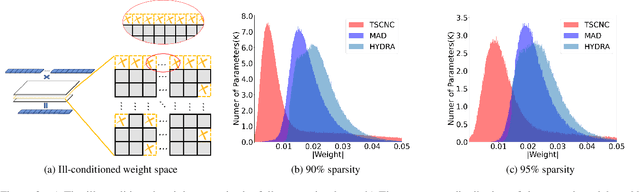
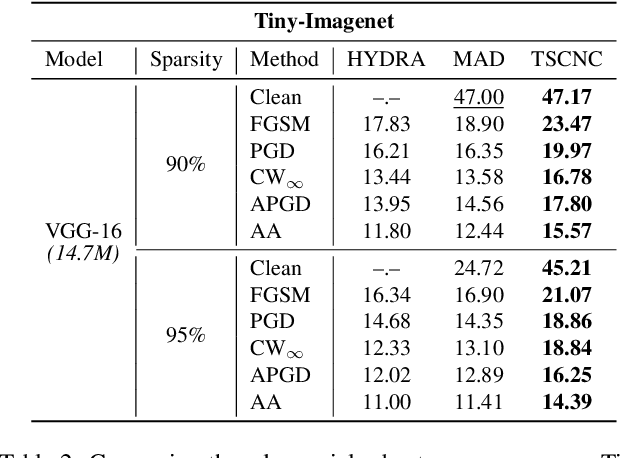
Recent research has revealed that high compression of Deep Neural Networks (DNNs), e.g., massive pruning of the weight matrix of a DNN, leads to a severe drop in accuracy and susceptibility to adversarial attacks. Integration of network pruning into an adversarial training framework has been proposed to promote adversarial robustness. It has been observed that a highly pruned weight matrix tends to be ill-conditioned, i.e., increasing the condition number of the weight matrix. This phenomenon aggravates the vulnerability of a DNN to input noise. Although a highly pruned weight matrix is considered to be able to lower the upper bound of the local Lipschitz constant to tolerate large distortion, the ill-conditionedness of such a weight matrix results in a non-robust DNN model. To overcome this challenge, this work develops novel joint constraints to adjust the weight distribution of networks, namely, the Transformed Sparse Constraint joint with Condition Number Constraint (TSCNC), which copes with smoothing distribution and differentiable constraint functions to reduce condition number and thus avoid the ill-conditionedness of weight matrices. Furthermore, our theoretical analyses unveil the relevance between the condition number and the local Lipschitz constant of the weight matrix, namely, the sharply increasing condition number becomes the dominant factor that restricts the robustness of over-sparsified models. Extensive experiments are conducted on several public datasets, and the results show that the proposed constraints significantly improve the robustness of a DNN with high pruning rates.
KiteRunner: Language-Driven Cooperative Local-Global Navigation Policy with UAV Mapping in Outdoor Environments
Mar 11, 2025
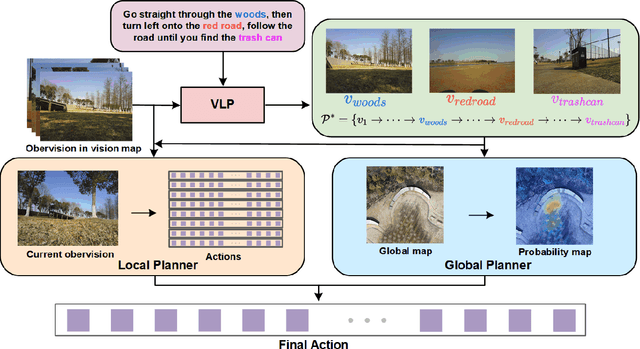
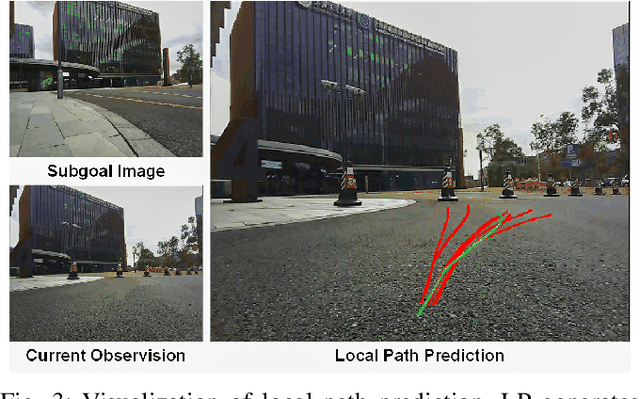

Autonomous navigation in open-world outdoor environments faces challenges in integrating dynamic conditions, long-distance spatial reasoning, and semantic understanding. Traditional methods struggle to balance local planning, global planning, and semantic task execution, while existing large language models (LLMs) enhance semantic comprehension but lack spatial reasoning capabilities. Although diffusion models excel in local optimization, they fall short in large-scale long-distance navigation. To address these gaps, this paper proposes KiteRunner, a language-driven cooperative local-global navigation strategy that combines UAV orthophoto-based global planning with diffusion model-driven local path generation for long-distance navigation in open-world scenarios. Our method innovatively leverages real-time UAV orthophotography to construct a global probability map, providing traversability guidance for the local planner, while integrating large models like CLIP and GPT to interpret natural language instructions. Experiments demonstrate that KiteRunner achieves 5.6% and 12.8% improvements in path efficiency over state-of-the-art methods in structured and unstructured environments, respectively, with significant reductions in human interventions and execution time.
Generative Multi-Agent Collaboration in Embodied AI: A Systematic Review
Feb 17, 2025Embodied multi-agent systems (EMAS) have attracted growing attention for their potential to address complex, real-world challenges in areas such as logistics and robotics. Recent advances in foundation models pave the way for generative agents capable of richer communication and adaptive problem-solving. This survey provides a systematic examination of how EMAS can benefit from these generative capabilities. We propose a taxonomy that categorizes EMAS by system architectures and embodiment modalities, emphasizing how collaboration spans both physical and virtual contexts. Central building blocks, perception, planning, communication, and feedback, are then analyzed to illustrate how generative techniques bolster system robustness and flexibility. Through concrete examples, we demonstrate the transformative effects of integrating foundation models into embodied, multi-agent frameworks. Finally, we discuss challenges and future directions, underlining the significant promise of EMAS to reshape the landscape of AI-driven collaboration.
Dual-BEV Nav: Dual-layer BEV-based Heuristic Path Planning for Robotic Navigation in Unstructured Outdoor Environments
Jan 30, 2025



Path planning with strong environmental adaptability plays a crucial role in robotic navigation in unstructured outdoor environments, especially in the case of low-quality location and map information. The path planning ability of a robot depends on the identification of the traversability of global and local ground areas. In real-world scenarios, the complexity of outdoor open environments makes it difficult for robots to identify the traversability of ground areas that lack a clearly defined structure. Moreover, most existing methods have rarely analyzed the integration of local and global traversability identifications in unstructured outdoor scenarios. To address this problem, we propose a novel method, Dual-BEV Nav, first introducing Bird's Eye View (BEV) representations into local planning to generate high-quality traversable paths. Then, these paths are projected onto the global traversability map generated by the global BEV planning model to obtain the optimal waypoints. By integrating the traversability from both local and global BEV, we establish a dual-layer BEV heuristic planning paradigm, enabling long-distance navigation in unstructured outdoor environments. We test our approach through both public dataset evaluations and real-world robot deployments, yielding promising results. Compared to baselines, the Dual-BEV Nav improved temporal distance prediction accuracy by up to $18.7\%$. In the real-world deployment, under conditions significantly different from the training set and with notable occlusions in the global BEV, the Dual-BEV Nav successfully achieved a 65-meter-long outdoor navigation. Further analysis demonstrates that the local BEV representation significantly enhances the rationality of the planning, while the global BEV probability map ensures the robustness of the overall planning.