 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroLoc: Encoding Navigation Cells for 6-DOF Camera Localization
May 02, 2025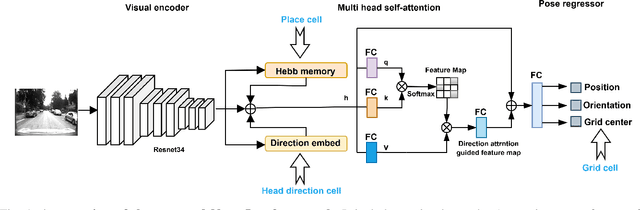
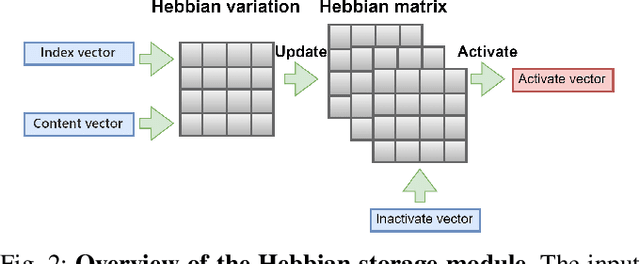
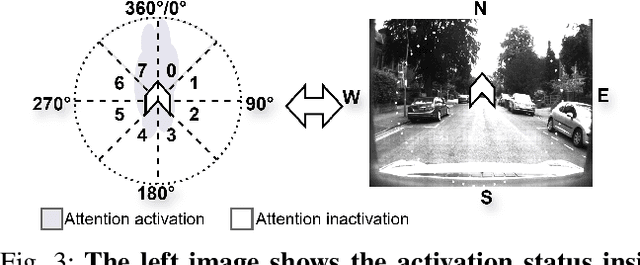
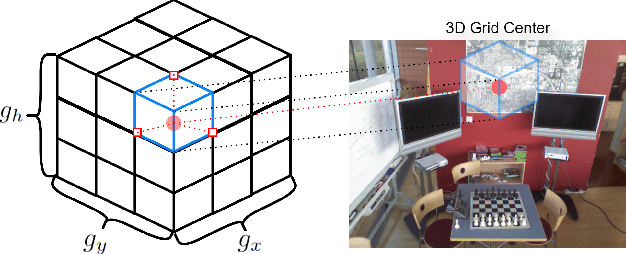
Recently, camera localization has been widely adopted in autonomous robotic navigation due to its efficiency and convenience. However, autonomous navigation in unknown environments often suffers from scene ambiguity, environmental disturbances, and dynamic object transformation in camera localization. To address this problem, inspired by the biological brain navigation mechanism (such as grid cells, place cells, and head direction cells), we propose a novel neurobiological camera location method, namely NeuroLoc. Firstly, we designed a Hebbian learning module driven by place cells to save and replay historical information, aiming to restore the details of historical representations and solve the issue of scene fuzziness. Secondly, we utilized the head direction cell-inspired internal direction learning as multi-head attention embedding to help restore the true orientation in similar scenes. Finally, we added a 3D grid center prediction in the pose regression module to reduce the final wrong prediction. We evaluate the proposed NeuroLoc on commonly used benchmark indoor and outdoor datasets. The experimental results show that our NeuroLoc can enhance the robustness in complex environments and improve the performance of pose regression by using only a single image.
Enhancing Texture Generation with High-Fidelity Using Advanced Texture Priors
Mar 08, 2024The recent advancements in 2D generation technology have sparked a widespread discussion on using 2D priors for 3D shape and texture content generation. However, these methods often overlook the subsequent user operations, such as texture aliasing and blurring that occur when the user acquires the 3D model and simplifies its structure. Traditional graphics methods partially alleviate this issue, but recent texture synthesis technologies fail to ensure consistency with the original model's appearance and cannot achieve high-fidelity restoration. Moreover, background noise frequently arises in high-resolution texture synthesis, limiting the practical application of these generation technologies.In this work, we propose a high-resolution and high-fidelity texture restoration technique that uses the rough texture as the initial input to enhance the consistency between the synthetic texture and the initial texture, thereby overcoming the issues of aliasing and blurring caused by the user's structure simplification operations. Additionally, we introduce a background noise smoothing technique based on a self-supervised scheme to address the noise problem in current high-resolution texture synthesis schemes. Our approach enables high-resolution texture synthesis, paving the way for high-definition and high-detail texture synthesis technology. Experiments demonstrate that our scheme outperforms currently known schemes in high-fidelity texture recovery under high-resolution conditions.
MetaDreamer: Efficient Text-to-3D Creation With Disentangling Geometry and Texture
Nov 16, 2023Generative models for 3D object synthesis have seen significant advancements with the incorporation of prior knowledge distilled from 2D diffusion models. Nevertheless, challenges persist in the form of multi-view geometric inconsistencies and slow generation speeds within the existing 3D synthesis frameworks. This can be attributed to two factors: firstly, the deficiency of abundant geometric a priori knowledge in optimization, and secondly, the entanglement issue between geometry and texture in conventional 3D generation methods.In response, we introduce MetaDreammer, a two-stage optimization approach that leverages rich 2D and 3D prior knowledge. In the first stage, our emphasis is on optimizing the geometric representation to ensure multi-view consistency and accuracy of 3D objects. In the second stage, we concentrate on fine-tuning the geometry and optimizing the texture, thereby achieving a more refined 3D object. Through leveraging 2D and 3D prior knowledge in two stages, respectively, we effectively mitigate the interdependence between geometry and texture. MetaDreamer establishes clear optimization objectives for each stage, resulting in significant time savings in the 3D generation process. Ultimately, MetaDreamer can generate high-quality 3D objects based on textual prompts within 20 minutes, and to the best of our knowledge, it is the most efficient text-to-3D generation method. Furthermore, we introduce image control into the process, enhancing the controllability of 3D generation. Extensive empirical evidence confirms that our method is not only highly efficient but also achieves a quality level that is at the forefront of current state-of-the-art 3D generation techniques.
Missing-modality Enabled Multi-modal Fusion Architecture for Medical Data
Sep 27, 2023Fusing multi-modal data can improve the performance of deep learning models. However, missing modalities are common for medical data due to patients' specificity, which is detrimental to the performance of multi-modal models in applications. Therefore, it is critical to adapt the models to missing modalities. This study aimed to develop an efficient multi-modal fusion architecture for medical data that was robust to missing modalities and further improved the performance on disease diagnosis.X-ray chest radiographs for the image modality, radiology reports for the text modality, and structured value data for the tabular data modality were fused in this study. Each modality pair was fused with a Transformer-based bi-modal fusion module, and the three bi-modal fusion modules were then combined into a tri-modal fusion framework. Additionally, multivariate loss functions were introduced into the training process to improve model's robustness to missing modalities in the inference process. Finally, we designed comparison and ablation experiments for validating the effectiveness of the fusion, the robustness to missing modalities and the enhancements from each key component. Experiments were conducted on MIMIC-IV, MIMIC-CXR with the 14-label disease diagnosis task. Areas under the receiver operating characteristic curve (AUROC), the area under the precision-recall curve (AUPRC) were used to evaluate models' performance. The experimental results demonstrated that our proposed multi-modal fusion architecture effectively fused three modalities and showed strong robustness to missing modalities. This method is hopeful to be scaled to more modalities to enhance the clinical practicality of the model.
Multi-scale Geometry-aware Transformer for 3D Point Cloud Classification
Apr 12, 2023Self-attention modules have demonstrated remarkable capabilities in capturing long-range relationships and improving the performance of point cloud tasks. However, point cloud objects are typically characterized by complex, disordered, and non-Euclidean spatial structures with multiple scales, and their behavior is often dynamic and unpredictable. The current self-attention modules mostly rely on dot product multiplication and dimension alignment among query-key-value features, which cannot adequately capture the multi-scale non-Euclidean structures of point cloud objects. To address these problems, this paper proposes a self-attention plug-in module with its variants, Multi-scale Geometry-aware Transformer (MGT). MGT processes point cloud data with multi-scale local and global geometric information in the following three aspects. At first, the MGT divides point cloud data into patches with multiple scales. Secondly, a local feature extractor based on sphere mapping is proposed to explore the geometry inner each patch and generate a fixed-length representation for each patch. Thirdly, the fixed-length representations are fed into a novel geodesic-based self-attention to capture the global non-Euclidean geometry between patches. Finally, all the modules are integrated into the framework of MGT with an end-to-end training scheme. Experimental results demonstrate that the MGT vastly increases the capability of capturing multi-scale geometry using the self-attention mechanism and achieves strong competitive performance on mainstream point cloud benchmarks.