 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Motion In-betweening by Diffusion over Continuous Implicit Representations
May 12, 2026Recent advances in generative models have yielded impressive progress on motion in-betweening, allowing for more complex, varied, and realistic motion transitions. However, recent methods still exhibit noticeable limitations in preserving keyframe information and ensuring motion continuity. In this paper, we propose a novel pipeline and sampling optimization strategy for latent diffusion models (LDM) based on motion implicit neural representations (INR). By establishing a mapping between INR and sparse spatial or temporal information within latent diffusion, our model can sample the INR parameters from extremely sparse and ambiguous keyframe data and reconstruct plausible and smooth motions from the manifold. Our experiments demonstrate the superior performance of our model, which significantly improves motion generation quality in scenarios with few keyframes while ensuring both keyframe accuracy and diversity of in-between motions.
Masked Generative Policy for Robotic Control
Dec 09, 2025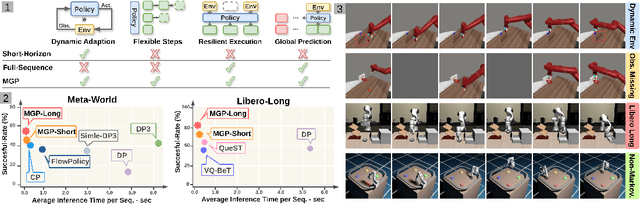

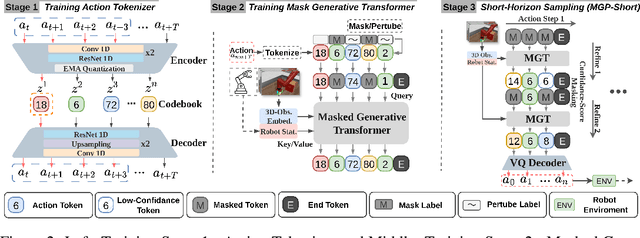

We present Masked Generative Policy (MGP), a novel framework for visuomotor imitation learning. We represent actions as discrete tokens, and train a conditional masked transformer that generates tokens in parallel and then rapidly refines only low-confidence tokens. We further propose two new sampling paradigms: MGP-Short, which performs parallel masked generation with score-based refinement for Markovian tasks, and MGP-Long, which predicts full trajectories in a single pass and dynamically refines low-confidence action tokens based on new observations. With globally coherent prediction and robust adaptive execution capabilities, MGP-Long enables reliable control on complex and non-Markovian tasks that prior methods struggle with. Extensive evaluations on 150 robotic manipulation tasks spanning the Meta-World and LIBERO benchmarks show that MGP achieves both rapid inference and superior success rates compared to state-of-the-art diffusion and autoregressive policies. Specifically, MGP increases the average success rate by 9% across 150 tasks while cutting per-sequence inference time by up to 35x. It further improves the average success rate by 60% in dynamic and missing-observation environments, and solves two non-Markovian scenarios where other state-of-the-art methods fail.
Multi-Person Interaction Generation from Two-Person Motion Priors
May 23, 2025Generating realistic human motion with high-level controls is a crucial task for social understanding, robotics, and animation. With high-quality MOCAP data becoming more available recently, a wide range of data-driven approaches have been presented. However, modelling multi-person interactions still remains a less explored area. In this paper, we present Graph-driven Interaction Sampling, a method that can generate realistic and diverse multi-person interactions by leveraging existing two-person motion diffusion models as motion priors. Instead of training a new model specific to multi-person interaction synthesis, our key insight is to spatially and temporally separate complex multi-person interactions into a graph structure of two-person interactions, which we name the Pairwise Interaction Graph. We thus decompose the generation task into simultaneous single-person motion generation conditioned on one other's motion. In addition, to reduce artifacts such as interpenetrations of body parts in generated multi-person interactions, we introduce two graph-dependent guidance terms into the diffusion sampling scheme. Unlike previous work, our method can produce various high-quality multi-person interactions without having repetitive individual motions. Extensive experiments demonstrate that our approach consistently outperforms existing methods in reducing artifacts when generating a wide range of two-person and multi-person interactions.
Flat'n'Fold: A Diverse Multi-Modal Dataset for Garment Perception and Manipulation
Sep 26, 2024



We present Flat'n'Fold, a novel large-scale dataset for garment manipulation that addresses critical gaps in existing datasets. Comprising 1,212 human and 887 robot demonstrations of flattening and folding 44 unique garments across 8 categories, Flat'n'Fold surpasses prior datasets in size, scope, and diversity. Our dataset uniquely captures the entire manipulation process from crumpled to folded states, providing synchronized multi-view RGB-D images, point clouds, and action data, including hand or gripper positions and rotations. We quantify the dataset's diversity and complexity compared to existing benchmarks and show that our dataset features natural and diverse manipulations of real-world demonstrations of human and robot demonstrations in terms of visual and action information. To showcase Flat'n'Fold's utility, we establish new benchmarks for grasping point prediction and subtask decomposition. Our evaluation of state-of-the-art models on these tasks reveals significant room for improvement. This underscores Flat'n'Fold's potential to drive advances in robotic perception and manipulation of deformable objects. Our dataset can be downloaded at https://cvas-ug.github.io/flat-n-fold
Missing-modality Enabled Multi-modal Fusion Architecture for Medical Data
Sep 27, 2023Fusing multi-modal data can improve the performance of deep learning models. However, missing modalities are common for medical data due to patients' specificity, which is detrimental to the performance of multi-modal models in applications. Therefore, it is critical to adapt the models to missing modalities. This study aimed to develop an efficient multi-modal fusion architecture for medical data that was robust to missing modalities and further improved the performance on disease diagnosis.X-ray chest radiographs for the image modality, radiology reports for the text modality, and structured value data for the tabular data modality were fused in this study. Each modality pair was fused with a Transformer-based bi-modal fusion module, and the three bi-modal fusion modules were then combined into a tri-modal fusion framework. Additionally, multivariate loss functions were introduced into the training process to improve model's robustness to missing modalities in the inference process. Finally, we designed comparison and ablation experiments for validating the effectiveness of the fusion, the robustness to missing modalities and the enhancements from each key component. Experiments were conducted on MIMIC-IV, MIMIC-CXR with the 14-label disease diagnosis task. Areas under the receiver operating characteristic curve (AUROC), the area under the precision-recall curve (AUPRC) were used to evaluate models' performance. The experimental results demonstrated that our proposed multi-modal fusion architecture effectively fused three modalities and showed strong robustness to missing modalities. This method is hopeful to be scaled to more modalities to enhance the clinical practicality of the model.
A Fast Location Algorithm for Very Sparse Point Clouds Based on Object Detection
Oct 21, 2021

Limited by the performance factor, it is arduous to recognize target object and locate it in Augmented Reality (AR) scenes on low-end mobile devices, especially which using monocular cameras. In this paper, we proposed an algorithm which can quickly locate the target object through image object detection in the circumstances of having very sparse feature points. We introduce YOLOv3-Tiny to our algorithm as the object detection module to filter the possible points and using Principal Component Analysis (PCA) to determine the location. We conduct the experiment in a manually designed scene by holding a smartphone and the results represent high positioning speed and accuracy of our method.
A Medical Pre-Diagnosis System for Histopathological Image of Breast Cancer
Sep 16, 2021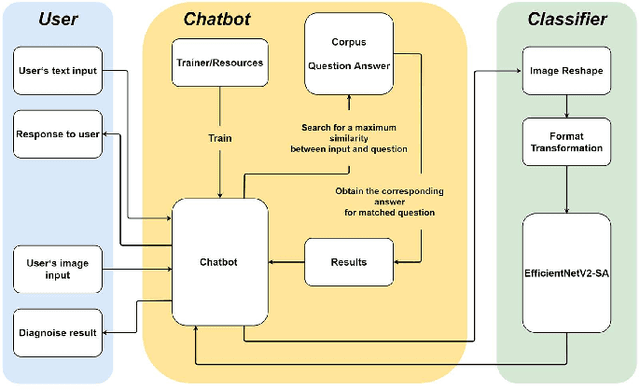
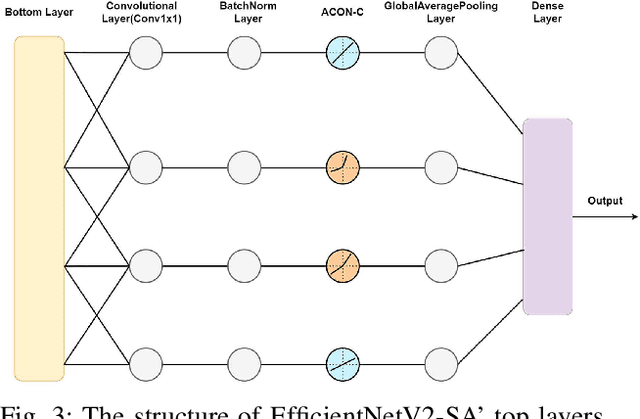

This paper constructs a novel intelligent medical diagnosis system, which can realize automatic communication and breast cancer pathological image recognition. This system contains two main parts, including a pre-training chatbot called M-Chatbot and an improved neural network model of EfficientNetV2-S named EfficientNetV2-SA, in which the activation function in top layers is replaced by ACON-C. Using information retrieval mechanism, M-Chatbot instructs patients to send breast pathological image to EfficientNetV2-SA network, and then the classifier trained by transfer learning will return the diagnosis results. We verify the performance of our chatbot and classification on the extrinsic metrics and BreaKHis dataset, respectively. The task completion rate of M-Chatbot reached 63.33\%. For the BreaKHis dataset, the highest accuracy of EfficientNetV2-SA network have achieved 84.71\%. All these experimental results illustrate that the proposed model can improve the accuracy performance of image recognition and our new intelligent medical diagnosis system is successful and efficient in providing automatic diagnosis of breast cancer.