 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling 3D Pedestrian-Vehicle Interactions for Vehicle-Conditioned Pose Forecasting
Feb 09, 2026Accurately predicting pedestrian motion is crucial for safe and reliable autonomous driving in complex urban environments. In this work, we present a 3D vehicle-conditioned pedestrian pose forecasting framework that explicitly incorporates surrounding vehicle information. To support this, we enhance the Waymo-3DSkelMo dataset with aligned 3D vehicle bounding boxes, enabling realistic modeling of multi-agent pedestrian-vehicle interactions. We introduce a sampling scheme to categorize scenes by pedestrian and vehicle count, facilitating training across varying interaction complexities. Our proposed network adapts the TBIFormer architecture with a dedicated vehicle encoder and pedestrian-vehicle interaction cross-attention module to fuse pedestrian and vehicle features, allowing predictions to be conditioned on both historical pedestrian motion and surrounding vehicles. Extensive experiments demonstrate substantial improvements in forecasting accuracy and validate different approaches for modeling pedestrian-vehicle interactions, highlighting the importance of vehicle-aware 3D pose prediction for autonomous driving. Code is available at: https://github.com/GuangxunZhu/VehCondPose3D
CardioMorphNet: Cardiac Motion Prediction Using a Shape-Guided Bayesian Recurrent Deep Network
Aug 28, 2025Accurate cardiac motion estimation from cine cardiac magnetic resonance (CMR) images is vital for assessing cardiac function and detecting its abnormalities. Existing methods often struggle to capture heart motion accurately because they rely on intensity-based image registration similarity losses that may overlook cardiac anatomical regions. To address this, we propose CardioMorphNet, a recurrent Bayesian deep learning framework for 3D cardiac shape-guided deformable registration using short-axis (SAX) CMR images. It employs a recurrent variational autoencoder to model spatio-temporal dependencies over the cardiac cycle and two posterior models for bi-ventricular segmentation and motion estimation. The derived loss function from the Bayesian formulation guides the framework to focus on anatomical regions by recursively registering segmentation maps without using intensity-based image registration similarity loss, while leveraging sequential SAX volumes and spatio-temporal features. The Bayesian modelling also enables computation of uncertainty maps for the estimated motion fields. Validated on the UK Biobank dataset by comparing warped mask shapes with ground truth masks, CardioMorphNet demonstrates superior performance in cardiac motion estimation, outperforming state-of-the-art methods. Uncertainty assessment shows that it also yields lower uncertainty values for estimated motion fields in the cardiac region compared with other probabilistic-based cardiac registration methods, indicating higher confidence in its predictions.
Multi-Person Interaction Generation from Two-Person Motion Priors
May 23, 2025Generating realistic human motion with high-level controls is a crucial task for social understanding, robotics, and animation. With high-quality MOCAP data becoming more available recently, a wide range of data-driven approaches have been presented. However, modelling multi-person interactions still remains a less explored area. In this paper, we present Graph-driven Interaction Sampling, a method that can generate realistic and diverse multi-person interactions by leveraging existing two-person motion diffusion models as motion priors. Instead of training a new model specific to multi-person interaction synthesis, our key insight is to spatially and temporally separate complex multi-person interactions into a graph structure of two-person interactions, which we name the Pairwise Interaction Graph. We thus decompose the generation task into simultaneous single-person motion generation conditioned on one other's motion. In addition, to reduce artifacts such as interpenetrations of body parts in generated multi-person interactions, we introduce two graph-dependent guidance terms into the diffusion sampling scheme. Unlike previous work, our method can produce various high-quality multi-person interactions without having repetitive individual motions. Extensive experiments demonstrate that our approach consistently outperforms existing methods in reducing artifacts when generating a wide range of two-person and multi-person interactions.
Gla-AI4BioMed at RRG24: Visual Instruction-tuned Adaptation for Radiology Report Generation
Dec 06, 2024
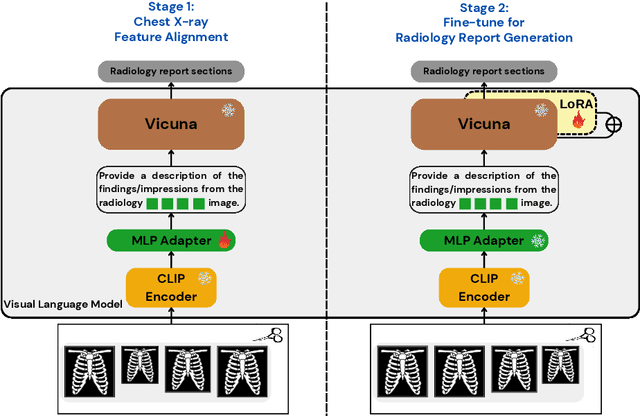

We introduce a radiology-focused visual language model designed to generate radiology reports from chest X-rays. Building on previous findings that large language models (LLMs) can acquire multimodal capabilities when aligned with pretrained vision encoders, we demonstrate similar potential with chest X-ray images. This integration enhances the ability of model to understand and describe chest X-ray images. Our model combines an image encoder with a fine-tuned LLM based on the Vicuna-7B architecture, enabling it to generate different sections of a radiology report with notable accuracy. The training process involves a two-stage approach: (i) initial alignment of chest X-ray features with the LLM (ii) followed by fine-tuning for radiology report generation.
Artificial Intelligence for Geometry-Based Feature Extraction, Analysis and Synthesis in Artistic Images: A Survey
Dec 02, 2024Artificial Intelligence significantly enhances the visual art industry by analyzing, identifying and generating digitized artistic images. This review highlights the substantial benefits of integrating geometric data into AI models, addressing challenges such as high inter-class variations, domain gaps, and the separation of style from content by incorporating geometric information. Models not only improve AI-generated graphics synthesis quality, but also effectively distinguish between style and content, utilizing inherent model biases and shared data traits. We explore methods like geometric data extraction from artistic images, the impact on human perception, and its use in discriminative tasks. The review also discusses the potential for improving data quality through innovative annotation techniques and the use of geometric data to enhance model adaptability and output refinement. Overall, incorporating geometric guidance boosts model performance in classification and synthesis tasks, providing crucial insights for future AI applications in the visual arts domain.
Libra: Leveraging Temporal Images for Biomedical Radiology Analysis
Nov 28, 2024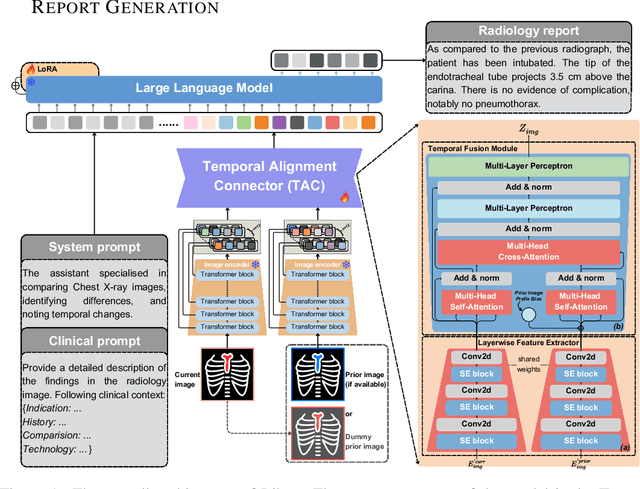



Radiology report generation (RRG) is a challenging task, as it requires a thorough understanding of medical images, integration of multiple temporal inputs, and accurate report generation. Effective interpretation of medical images, such as chest X-rays (CXRs), demands sophisticated visual-language reasoning to map visual findings to structured reports. Recent studies have shown that multimodal large language models (MLLMs) can acquire multimodal capabilities by aligning with pre-trained vision encoders. However, current approaches predominantly focus on single-image analysis or utilise rule-based symbolic processing to handle multiple images, thereby overlooking the essential temporal information derived from comparing current images with prior ones. To overcome this critical limitation, we introduce Libra, a temporal-aware MLLM tailored for CXR report generation using temporal images. Libra integrates a radiology-specific image encoder with a MLLM and utilises a novel Temporal Alignment Connector to capture and synthesise temporal information of images across different time points with unprecedented precision. Extensive experiments show that Libra achieves new state-of-the-art performance among the same parameter scale MLLMs for RRG tasks on the MIMIC-CXR. Specifically, Libra improves the RadCliQ metric by 12.9% and makes substantial gains across all lexical metrics compared to previous models.
Geometric Features Enhanced Human-Object Interaction Detection
Jun 26, 2024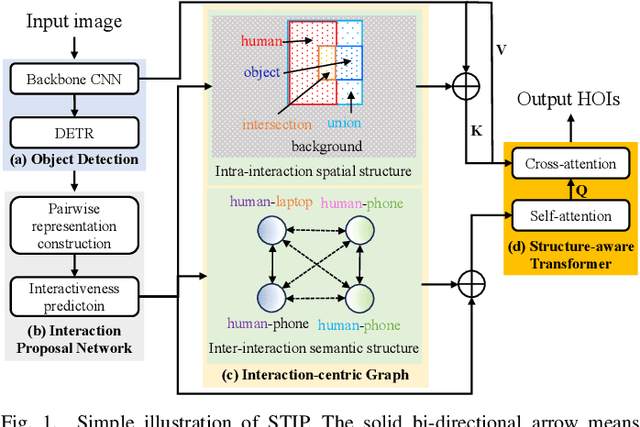


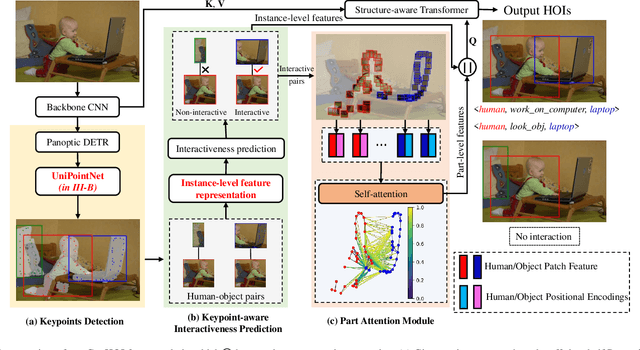
Cameras are essential vision instruments to capture images for pattern detection and measurement. Human-object interaction (HOI) detection is one of the most popular pattern detection approaches for captured human-centric visual scenes. Recently, Transformer-based models have become the dominant approach for HOI detection due to their advanced network architectures and thus promising results. However, most of them follow the one-stage design of vanilla Transformer, leaving rich geometric priors under-exploited and leading to compromised performance especially when occlusion occurs. Given that geometric features tend to outperform visual ones in occluded scenarios and offer information that complements visual cues, we propose a novel end-to-end Transformer-style HOI detection model, i.e., geometric features enhanced HOI detector (GeoHOI). One key part of the model is a new unified self-supervised keypoint learning method named UniPointNet that bridges the gap of consistent keypoint representation across diverse object categories, including humans. GeoHOI effectively upgrades a Transformer-based HOI detector benefiting from the keypoints similarities measuring the likelihood of human-object interactions as well as local keypoint patches to enhance interaction query representation, so as to boost HOI predictions. Extensive experiments show that the proposed method outperforms the state-of-the-art models on V-COCO and achieves competitive performance on HICO-DET. Case study results on the post-disaster rescue with vision-based instruments showcase the applicability of the proposed GeoHOI in real-world applications.
Two-Person Interaction Augmentation with Skeleton Priors
Apr 09, 2024Close and continuous interaction with rich contacts is a crucial aspect of human activities (e.g. hugging, dancing) and of interest in many domains like activity recognition, motion prediction, character animation, etc. However, acquiring such skeletal motion is challenging. While direct motion capture is expensive and slow, motion editing/generation is also non-trivial, as complex contact patterns with topological and geometric constraints have to be retained. To this end, we propose a new deep learning method for two-body skeletal interaction motion augmentation, which can generate variations of contact-rich interactions with varying body sizes and proportions while retaining the key geometric/topological relations between two bodies. Our system can learn effectively from a relatively small amount of data and generalize to drastically different skeleton sizes. Through exhaustive evaluation and comparison, we show it can generate high-quality motions, has strong generalizability and outperforms traditional optimization-based methods and alternative deep learning solutions.
Pose-based Tremor Type and Level Analysis for Parkinson's Disease from Video
Dec 21, 2023Purpose:Current methods for diagnosis of PD rely on clinical examination. The accuracy of diagnosis ranges between 73% and 84%, and is influenced by the experience of the clinical assessor. Hence, an automatic, effective and interpretable supporting system for PD symptom identification would support clinicians in making more robust PD diagnostic decisions. Methods: We propose to analyze Parkinson's tremor (PT) to support the analysis of PD, since PT is one of the most typical symptoms of PD with broad generalizability. To realize the idea, we present SPA-PTA, a deep learning-based PT classification and severity estimation system that takes consumer-grade videos of front-facing humans as input. The core of the system is a novel attention module with a lightweight pyramidal channel-squeezing-fusion architecture that effectively extracts relevant PT information and filters noise. It enhances modeling performance while improving system interpretability. Results:We validate our system via individual-based leave-one-out cross-validation on two tasks: the PT classification task and the tremor severity rating estimation task. Our system presents a 91.3% accuracy and 80.0% F1-score in classifying PT with non-PT class, while providing a 76.4% accuracy and 76.7% F1-score in more complex multiclass tremor rating classification task. Conclusion: Our system offers a cost-effective PT classification and tremor severity estimation results as warning signs of PD for undiagnosed patients with PT symptoms. In addition, it provides a potential solution for supporting PD diagnosis in regions with limited clinical resources.
Social Interaction-Aware Dynamical Models and Decision Making for Autonomous Vehicles
Oct 31, 2023Interaction-aware Autonomous Driving (IAAD) is a rapidly growing field of research that focuses on the development of autonomous vehicles (AVs) that are capable of interacting safely and efficiently with human road users. This is a challenging task, as it requires the autonomous vehicle to be able to understand and predict the behaviour of human road users. In this literature review, the current state of IAAD research is surveyed in this work. Commencing with an examination of terminology, attention is drawn to challenges and existing models employed for modelling the behaviour of drivers and pedestrians. Next, a comprehensive review is conducted on various techniques proposed for interaction modelling, encompassing cognitive methods, machine learning approaches, and game-theoretic methods. The conclusion is reached through a discussion of potential advantages and risks associated with IAAD, along with the illumination of pivotal research inquiries necessitating future exploration.