 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neurosymbolic Approach to Natural Language Formalization and Verification
Nov 12, 2025Large Language Models perform well at natural language interpretation and reasoning, but their inherent stochasticity limits their adoption in regulated industries like finance and healthcare that operate under strict policies. To address this limitation, we present a two-stage neurosymbolic framework that (1) uses LLMs with optional human guidance to formalize natural language policies, allowing fine-grained control of the formalization process, and (2) uses inference-time autoformalization to validate logical correctness of natural language statements against those policies. When correctness is paramount, we perform multiple redundant formalization steps at inference time, cross checking the formalizations for semantic equivalence. Our benchmarks demonstrate that our approach exceeds 99% soundness, indicating a near-zero false positive rate in identifying logical validity. Our approach produces auditable logical artifacts that substantiate the verification outcomes and can be used to improve the original text.
Zero-knowledge LLM hallucination detection and mitigation through fine-grained cross-model consistency
Aug 19, 2025Large language models (LLMs) have demonstrated impressive capabilities across diverse tasks, but they remain susceptible to hallucinations--generating content that appears plausible but contains factual inaccuracies. We present Finch-Zk, a black-box framework that leverages FINe-grained Cross-model consistency to detect and mitigate Hallucinations in LLM outputs without requiring external knowledge sources. Finch-Zk introduces two key innovations: 1) a cross-model consistency checking strategy that reveals fine-grained inaccuracies by comparing responses generated by diverse models from semantically-equivalent prompts, and 2) a targeted mitigation technique that applies precise corrections to problematic segments while preserving accurate content. Experiments on the FELM dataset show Finch-Zk improves hallucination detection F1 scores by 6-39\% compared to existing approaches. For mitigation, Finch-Zk achieves 7-8 absolute percentage points improvement in answer accuracy on the GPQA-diamond dataset when applied to state-of-the-art models like Llama 4 Maverick and Claude 4 Sonnet. Extensive evaluation across multiple models demonstrates that Finch-Zk provides a practical, deployment-ready safeguard for enhancing factual reliability in production LLM systems.
TurboFuzzLLM: Turbocharging Mutation-based Fuzzing for Effectively Jailbreaking Large Language Models in Practice
Feb 21, 2025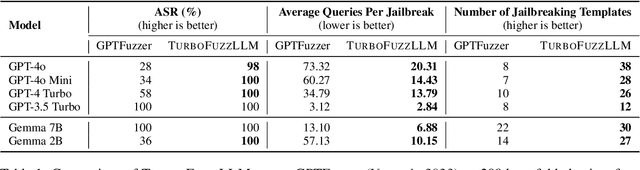
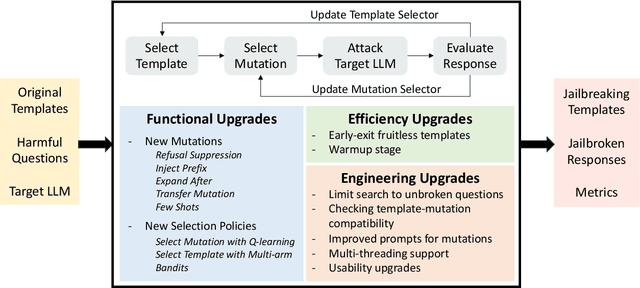


Jailbreaking large-language models (LLMs) involves testing their robustness against adversarial prompts and evaluating their ability to withstand prompt attacks that could elicit unauthorized or malicious responses. In this paper, we present TurboFuzzLLM, a mutation-based fuzzing technique for efficiently finding a collection of effective jailbreaking templates that, when combined with harmful questions, can lead a target LLM to produce harmful responses through black-box access via user prompts. We describe the limitations of directly applying existing template-based attacking techniques in practice, and present functional and efficiency-focused upgrades we added to mutation-based fuzzing to generate effective jailbreaking templates automatically. TurboFuzzLLM achieves $\geq$ 95\% attack success rates (ASR) on public datasets for leading LLMs (including GPT-4o \& GPT-4 Turbo), shows impressive generalizability to unseen harmful questions, and helps in improving model defenses to prompt attacks.
Interaction Mix and Match: Synthesizing Close Interaction using Conditional Hierarchical GAN with Multi-Hot Class Embedding
Aug 04, 2022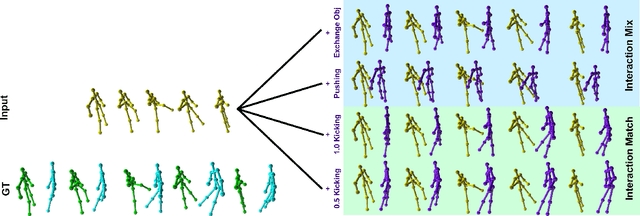
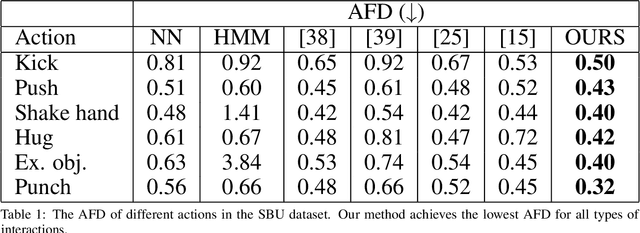
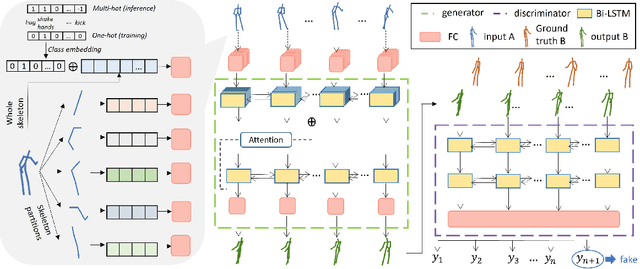

Synthesizing multi-character interactions is a challenging task due to the complex and varied interactions between the characters. In particular, precise spatiotemporal alignment between characters is required in generating close interactions such as dancing and fighting. Existing work in generating multi-character interactions focuses on generating a single type of reactive motion for a given sequence which results in a lack of variety of the resultant motions. In this paper, we propose a novel way to create realistic human reactive motions which are not presented in the given dataset by mixing and matching different types of close interactions. We propose a Conditional Hierarchical Generative Adversarial Network with Multi-Hot Class Embedding to generate the Mix and Match reactive motions of the follower from a given motion sequence of the leader. Experiments are conducted on both noisy (depth-based) and high-quality (MoCap-based) interaction datasets. The quantitative and qualitative results show that our approach outperforms the state-of-the-art methods on the given datasets. We also provide an augmented dataset with realistic reactive motions to stimulate future research in this area. The code is available at https://github.com/Aman-Goel1/IMM
GlocalNet: Class-aware Long-term Human Motion Synthesis
Dec 19, 2020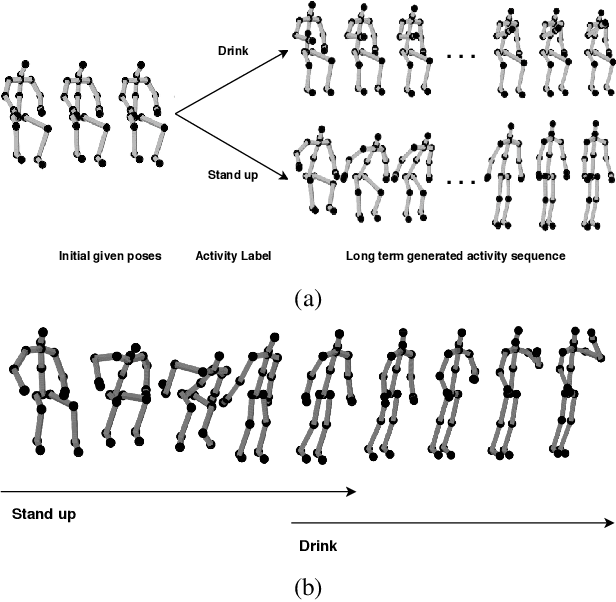
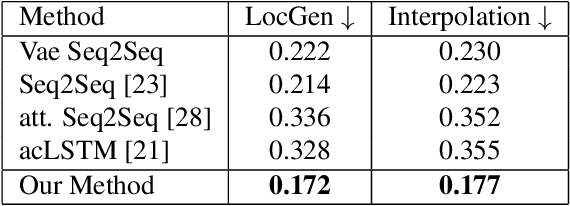
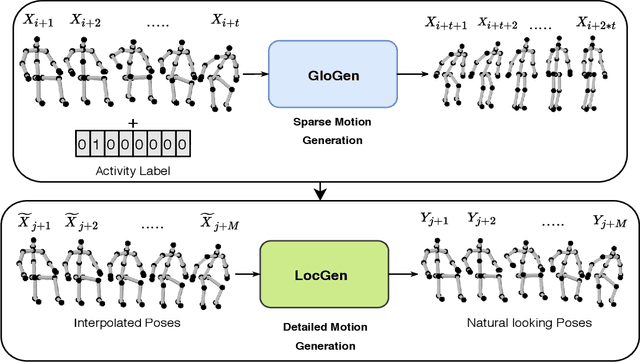
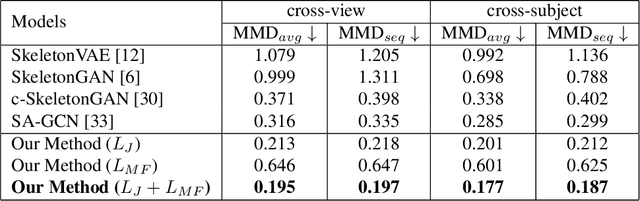
Synthesis of long-term human motion skeleton sequences is essential to aid human-centric video generation with potential applications in Augmented Reality, 3D character animations, pedestrian trajectory prediction, etc. Long-term human motion synthesis is a challenging task due to multiple factors like, long-term temporal dependencies among poses, cyclic repetition across poses, bi-directional and multi-scale dependencies among poses, variable speed of actions, and a large as well as partially overlapping space of temporal pose variations across multiple class/types of human activities. This paper aims to address these challenges to synthesize a long-term (> 6000 ms) human motion trajectory across a large variety of human activity classes (>50). We propose a two-stage activity generation method to achieve this goal, where the first stage deals with learning the long-term global pose dependencies in activity sequences by learning to synthesize a sparse motion trajectory while the second stage addresses the generation of dense motion trajectories taking the output of the first stage. We demonstrate the superiority of the proposed method over SOTA methods using various quantitative evaluation metrics on publicly available datasets.
* Appearing in 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)