 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion Based Attentive Networks for Sequential Music Recommendation
Oct 03, 2021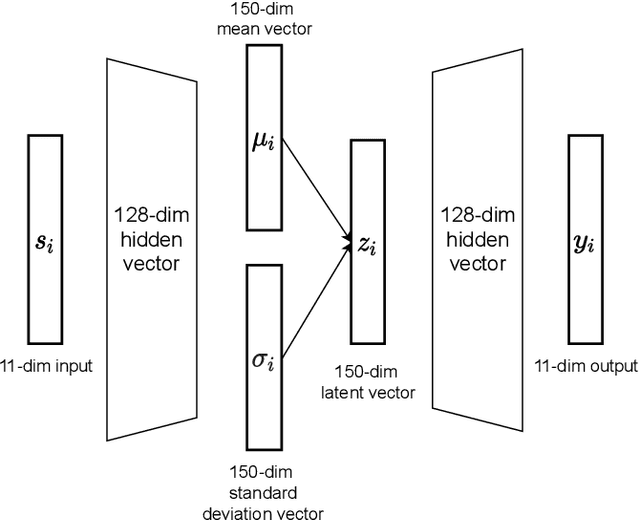
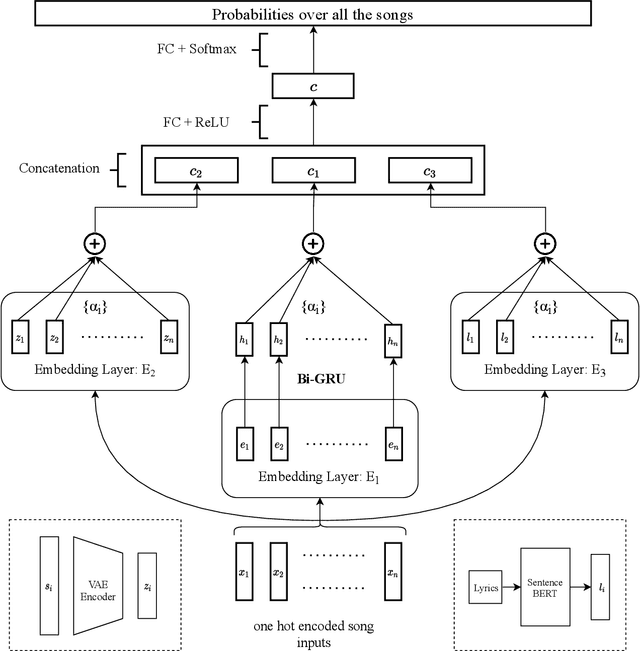

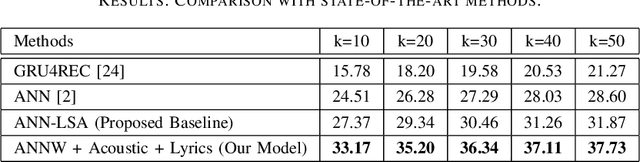
Music has the power to evoke intense emotional experiences and regulate the mood of an individual. With the advent of online streaming services, research in music recommendation services has seen tremendous progress. Modern methods leveraging the listening histories of users for session-based song recommendations have overlooked the significance of features extracted from lyrics and acoustic content. We address the task of song prediction through multiple modalities, including tags, lyrics, and acoustic content. In this paper, we propose a novel deep learning approach by refining Attentive Neural Networks using representations derived via a Transformer model for lyrics and Variational Autoencoder for acoustic features. Our model achieves significant improvement in performance over existing state-of-the-art models using lyrical and acoustic features alone. Furthermore, we conduct a study to investigate the impact of users' psychological health on our model's performance.
Transformer-based approach towards music emotion recognition from lyrics
Jan 06, 2021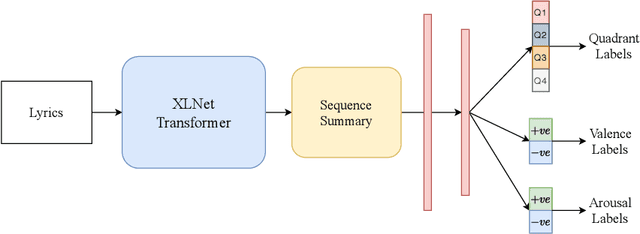

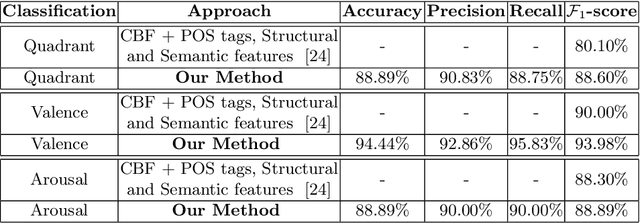
The task of identifying emotions from a given music track has been an active pursuit in the Music Information Retrieval (MIR) community for years. Music emotion recognition has typically relied on acoustic features, social tags, and other metadata to identify and classify music emotions. The role of lyrics in music emotion recognition remains under-appreciated in spite of several studies reporting superior performance of music emotion classifiers based on features extracted from lyrics. In this study, we use the transformer-based approach model using XLNet as the base architecture which, till date, has not been used to identify emotional connotations of music based on lyrics. Our proposed approach outperforms existing methods for multiple datasets. We used a robust methodology to enhance web-crawlers' accuracy for extracting lyrics. This study has important implications in improving applications involved in playlist generation of music based on emotions in addition to improving music recommendation systems.
GlocalNet: Class-aware Long-term Human Motion Synthesis
Dec 19, 2020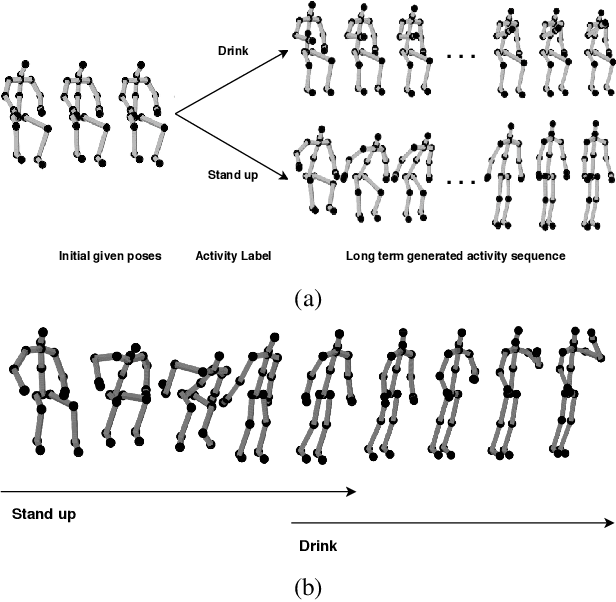
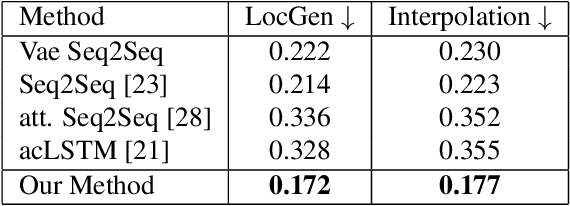
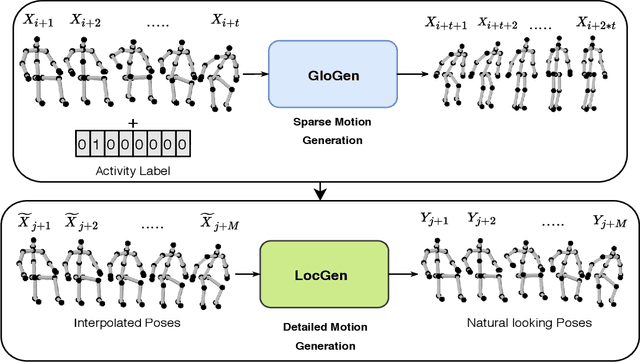
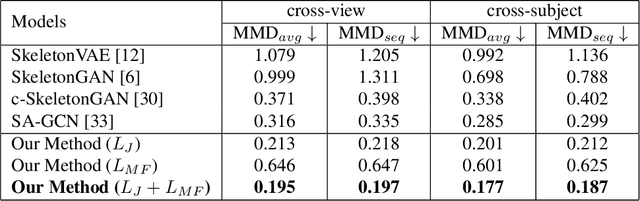
Synthesis of long-term human motion skeleton sequences is essential to aid human-centric video generation with potential applications in Augmented Reality, 3D character animations, pedestrian trajectory prediction, etc. Long-term human motion synthesis is a challenging task due to multiple factors like, long-term temporal dependencies among poses, cyclic repetition across poses, bi-directional and multi-scale dependencies among poses, variable speed of actions, and a large as well as partially overlapping space of temporal pose variations across multiple class/types of human activities. This paper aims to address these challenges to synthesize a long-term (> 6000 ms) human motion trajectory across a large variety of human activity classes (>50). We propose a two-stage activity generation method to achieve this goal, where the first stage deals with learning the long-term global pose dependencies in activity sequences by learning to synthesize a sparse motion trajectory while the second stage addresses the generation of dense motion trajectories taking the output of the first stage. We demonstrate the superiority of the proposed method over SOTA methods using various quantitative evaluation metrics on publicly available datasets.
* Appearing in 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)
Towards Multimodal MIR: Predicting individual differences from music-induced movement
Jul 21, 2020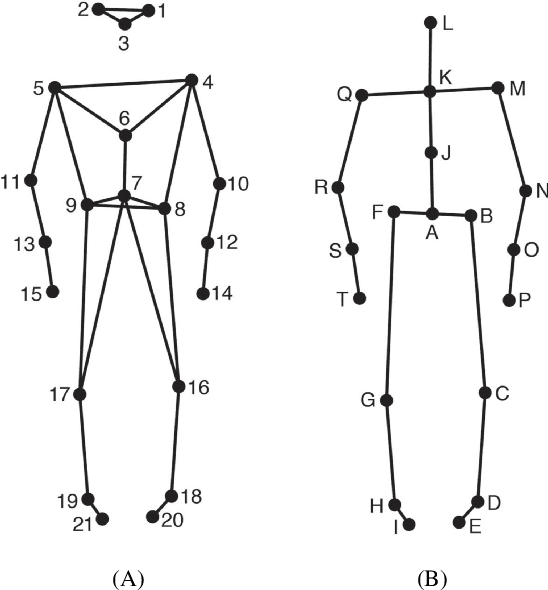
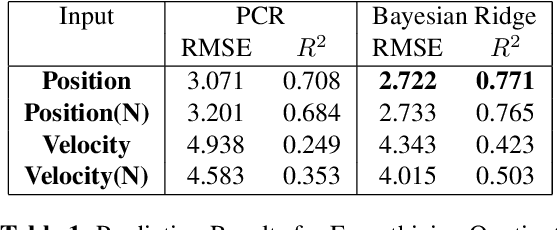
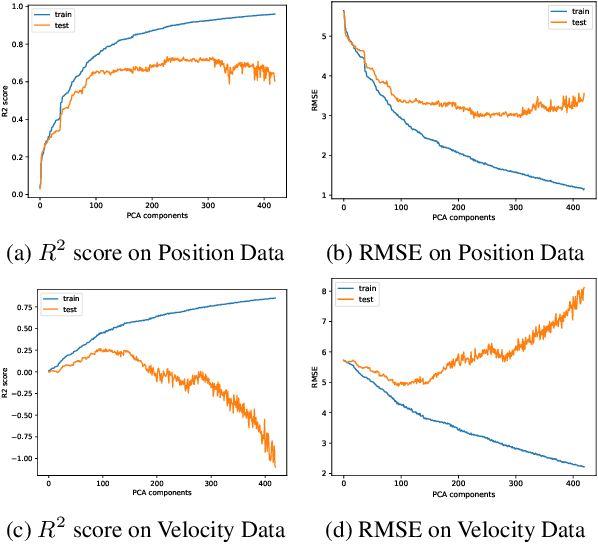
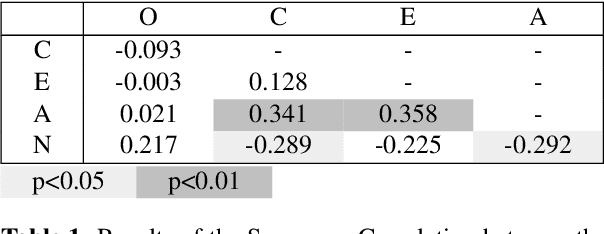
As the field of Music Information Retrieval grows, it is important to take into consideration the multi-modality of music and how aspects of musical engagement such as movement and gesture might be taken into account. Bodily movement is universally associated with music and reflective of important individual features related to music preference such as personality, mood, and empathy. Future multimodal MIR systems may benefit from taking these aspects into account. The current study addresses this by identifying individual differences, specifically Big Five personality traits, and scores on the Empathy and Systemizing Quotients (EQ/SQ) from participants' free dance movements. Our model successfully explored the unseen space for personality as well as EQ, SQ, which has not previously been accomplished for the latter. R2 scores for personality, EQ, and SQ were 76.3%, 77.1%, and 86.7% respectively. As a follow-up, we investigated which bodily joints were most important in defining these traits. We discuss how further research may explore how the mapping of these traits to movement patterns can be used to build a more personalized, multi-modal recommendation system, as well as potential therapeutic applications.
HumanMeshNet: Polygonal Mesh Recovery of Humans
Aug 19, 2019
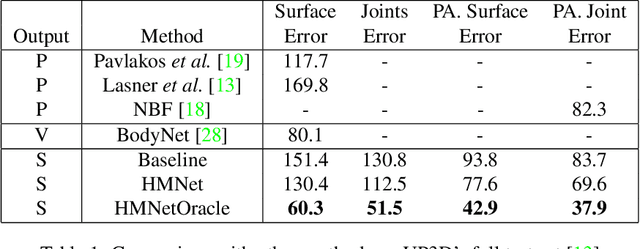
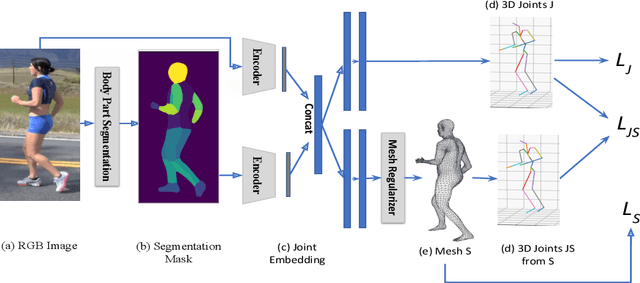
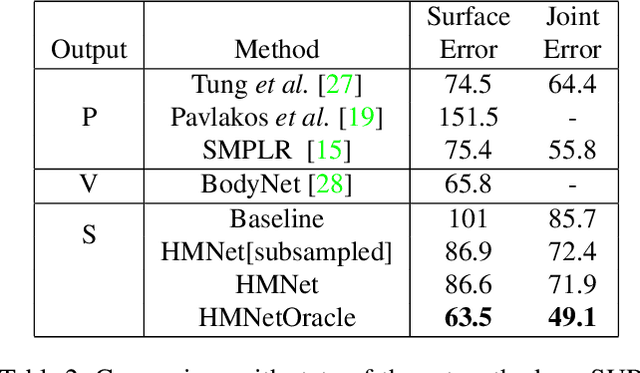
3D Human Body Reconstruction from a monocular image is an important problem in computer vision with applications in virtual and augmented reality platforms, animation industry, en-commerce domain, etc. While several of the existing works formulate it as a volumetric or parametric learning with complex and indirect reliance on re-projections of the mesh, we would like to focus on implicitly learning the mesh representation. To that end, we propose a novel model, HumanMeshNet, that regresses a template mesh's vertices, as well as receives a regularization by the 3D skeletal locations in a multi-branch, multi-task setup. The image to mesh vertex regression is further regularized by the neighborhood constraint imposed by mesh topology ensuring smooth surface reconstruction. The proposed paradigm can theoretically learn local surface deformations induced by body shape variations and can therefore learn high-resolution meshes going ahead. We show comparable performance with SoA (in terms of surface and joint error) with far lesser computational complexity, modeling cost and therefore real-time reconstructions on three publicly available datasets. We also show the generalizability of the proposed paradigm for a similar task of predicting hand mesh models. Given these initial results, we would like to exploit the mesh topology in an explicit manner going ahead.