 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepHuMS: Deep Human Motion Signature for 3D Skeletal Sequences
Aug 19, 2019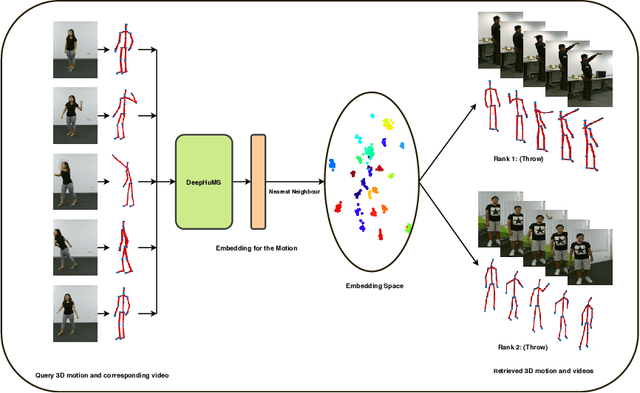
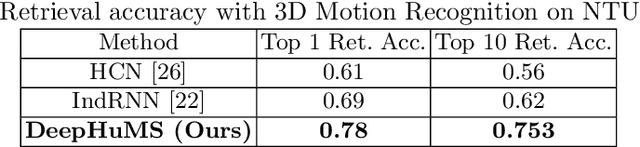
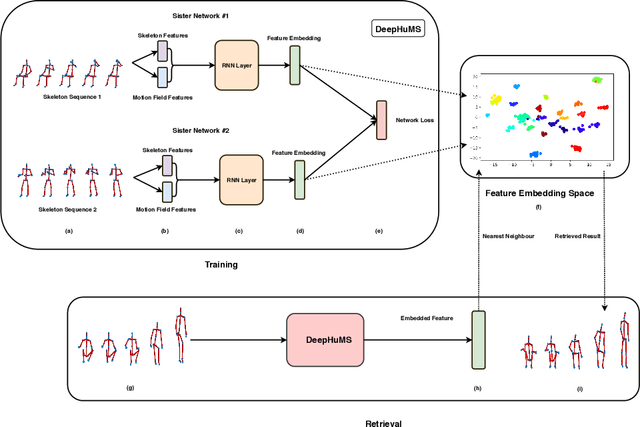
3D Human Motion Indexing and Retrieval is an interesting problem due to the rise of several data-driven applications aimed at analyzing and/or re-utilizing 3D human skeletal data, such as data-driven animation, analysis of sports bio-mechanics, human surveillance etc. Spatio-temporal articulations of humans, noisy/missing data, different speeds of the same motion etc. make it challenging and several of the existing state of the art methods use hand-craft features along with optimization based or histogram based comparison in order to perform retrieval. Further, they demonstrate it only for very small datasets and few classes. We make a case for using a learned representation that should recognize the motion as well as enforce a discriminative ranking. To that end, we propose, a 3D human motion descriptor learned using a deep network. Our learned embedding is generalizable and applicable to real-world data - addressing the aforementioned challenges and further enables sub-motion searching in its embedding space using another network. Our model exploits the inter-class similarity using trajectory cues, and performs far superior in a self-supervised setting. State of the art results on all these fronts is shown on two large scale 3D human motion datasets - NTU RGB+D and HDM05.
HumanMeshNet: Polygonal Mesh Recovery of Humans
Aug 19, 2019
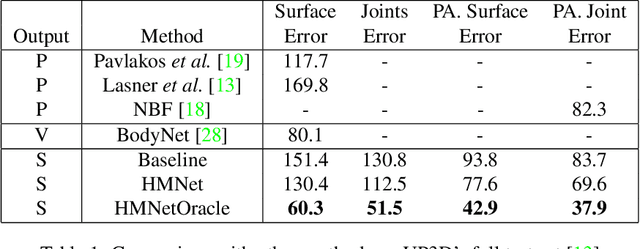
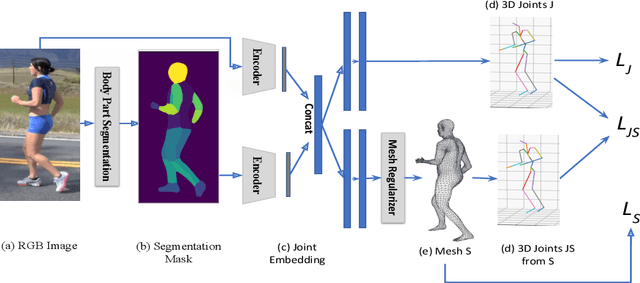
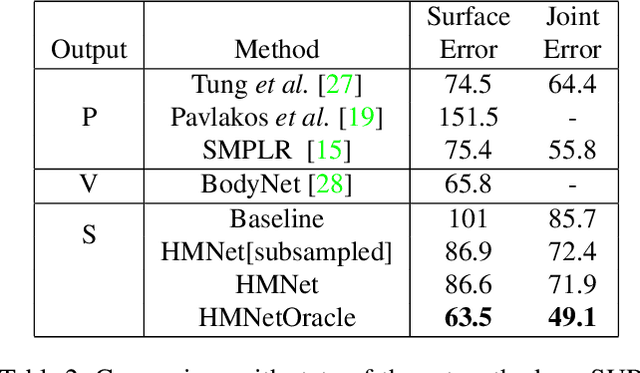
3D Human Body Reconstruction from a monocular image is an important problem in computer vision with applications in virtual and augmented reality platforms, animation industry, en-commerce domain, etc. While several of the existing works formulate it as a volumetric or parametric learning with complex and indirect reliance on re-projections of the mesh, we would like to focus on implicitly learning the mesh representation. To that end, we propose a novel model, HumanMeshNet, that regresses a template mesh's vertices, as well as receives a regularization by the 3D skeletal locations in a multi-branch, multi-task setup. The image to mesh vertex regression is further regularized by the neighborhood constraint imposed by mesh topology ensuring smooth surface reconstruction. The proposed paradigm can theoretically learn local surface deformations induced by body shape variations and can therefore learn high-resolution meshes going ahead. We show comparable performance with SoA (in terms of surface and joint error) with far lesser computational complexity, modeling cost and therefore real-time reconstructions on three publicly available datasets. We also show the generalizability of the proposed paradigm for a similar task of predicting hand mesh models. Given these initial results, we would like to exploit the mesh topology in an explicit manner going ahead.
Deep Textured 3D Reconstruction of Human Bodies
Sep 18, 2018
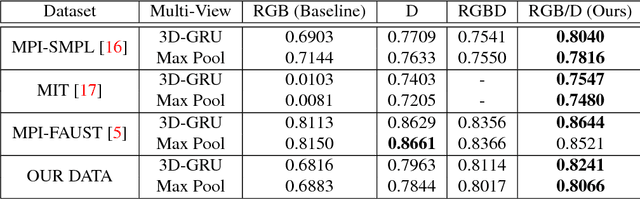


Recovering textured 3D models of non-rigid human body shapes is challenging due to self-occlusions caused by complex body poses and shapes, clothing obstructions, lack of surface texture, background clutter, sparse set of cameras with non-overlapping fields of view, etc. Further, a calibration-free environment adds additional complexity to both - reconstruction and texture recovery. In this paper, we propose a deep learning based solution for textured 3D reconstruction of human body shapes from a single view RGB image. This is achieved by first recovering the volumetric grid of the non-rigid human body given a single view RGB image followed by orthographic texture view synthesis using the respective depth projection of the reconstructed (volumetric) shape and input RGB image. We propose to co-learn the depth information readily available with affordable RGBD sensors (e.g., Kinect) while showing multiple views of the same object during the training phase. We show superior reconstruction performance in terms of quantitative and qualitative results, on both, publicly available datasets (by simulating the depth channel with virtual Kinect) as well as real RGBD data collected with our calibrated multi Kinect setup.