 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMultiAgents: A Multi-Agent Framework for Video Question Answering
Apr 30, 2025Video Question Answering (VQA) inherently relies on multimodal reasoning, integrating visual, temporal, and linguistic cues to achieve a deeper understanding of video content. However, many existing methods rely on feeding frame-level captions into a single model, making it difficult to adequately capture temporal and interactive contexts. To address this limitation, we introduce VideoMultiAgents, a framework that integrates specialized agents for vision, scene graph analysis, and text processing. It enhances video understanding leveraging complementary multimodal reasoning from independently operating agents. Our approach is also supplemented with a question-guided caption generation, which produces captions that highlight objects, actions, and temporal transitions directly relevant to a given query, thus improving the answer accuracy. Experimental results demonstrate that our method achieves state-of-the-art performance on Intent-QA (79.0%, +6.2% over previous SOTA), EgoSchema subset (75.4%, +3.4%), and NExT-QA (79.6%, +0.4%). The source code is available at https://github.com/PanasonicConnect/VideoMultiAgents.
AdaVid: Adaptive Video-Language Pretraining
Apr 16, 2025Contrastive video-language pretraining has demonstrated great success in learning rich and robust video representations. However, deploying such video encoders on compute-constrained edge devices remains challenging due to their high computational demands. Additionally, existing models are typically trained to process only short video clips, often limited to 4 to 64 frames. In this paper, we introduce AdaVid, a flexible architectural framework designed to learn efficient video encoders that can dynamically adapt their computational footprint based on available resources. At the heart of AdaVid is an adaptive transformer block, inspired by Matryoshka Representation Learning, which allows the model to adjust its hidden embedding dimension at inference time. We show that AdaVid-EgoVLP, trained on video-narration pairs from the large-scale Ego4D dataset, matches the performance of the standard EgoVLP on short video-language benchmarks using only half the compute, and even outperforms EgoVLP when given equal computational resources. We further explore the trade-off between frame count and compute on the challenging Diving48 classification benchmark, showing that AdaVid enables the use of more frames without exceeding computational limits. To handle longer videos, we also propose a lightweight hierarchical network that aggregates short clip features, achieving a strong balance between compute efficiency and accuracy across several long video benchmarks.
Fast Registration of Photorealistic Avatars for VR Facial Animation
Jan 19, 2024



Virtual Reality (VR) bares promise of social interactions that can feel more immersive than other media. Key to this is the ability to accurately animate a photorealistic avatar of one's likeness while wearing a VR headset. Although high quality registration of person-specific avatars to headset-mounted camera (HMC) images is possible in an offline setting, the performance of generic realtime models are significantly degraded. Online registration is also challenging due to oblique camera views and differences in modality. In this work, we first show that the domain gap between the avatar and headset-camera images is one of the primary sources of difficulty, where a transformer-based architecture achieves high accuracy on domain-consistent data, but degrades when the domain-gap is re-introduced. Building on this finding, we develop a system design that decouples the problem into two parts: 1) an iterative refinement module that takes in-domain inputs, and 2) a generic avatar-guided image-to-image style transfer module that is conditioned on current estimation of expression and head pose. These two modules reinforce each other, as image style transfer becomes easier when close-to-ground-truth examples are shown, and better domain-gap removal helps registration. Our system produces high-quality results efficiently, obviating the need for costly offline registration to generate personalized labels. We validate the accuracy and efficiency of our approach through extensive experiments on a commodity headset, demonstrating significant improvements over direct regression methods as well as offline registration.
Evaluating Self and Semi-Supervised Methods for Remote Sensing Segmentation Tasks
Nov 19, 2021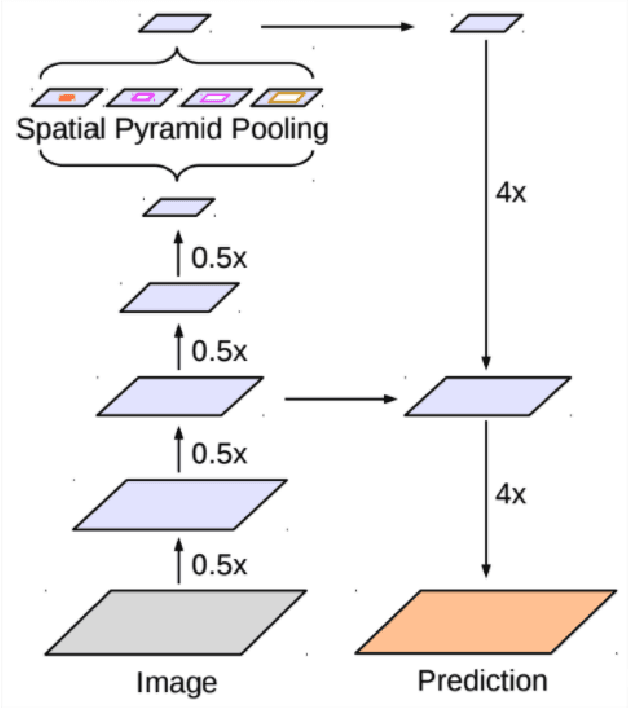
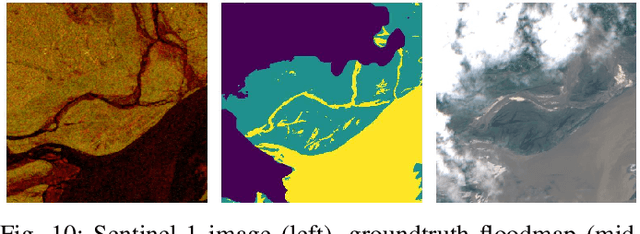


We perform a rigorous evaluation of recent self and semi-supervised ML techniques that leverage unlabeled data for improving downstream task performance, on three remote sensing tasks of riverbed segmentation, land cover mapping and flood mapping. These methods are especially valuable for remote sensing tasks since there is easy access to unlabeled imagery and getting ground truth labels can often be expensive. We quantify performance improvements one can expect on these remote sensing segmentation tasks when unlabeled imagery (outside of the labeled dataset) is made available for training. We also design experiments to test the effectiveness of these techniques when the test set has a domain shift relative to the training and validation sets.
TailorNet: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style
Mar 15, 2020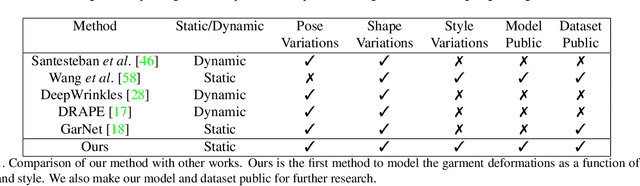
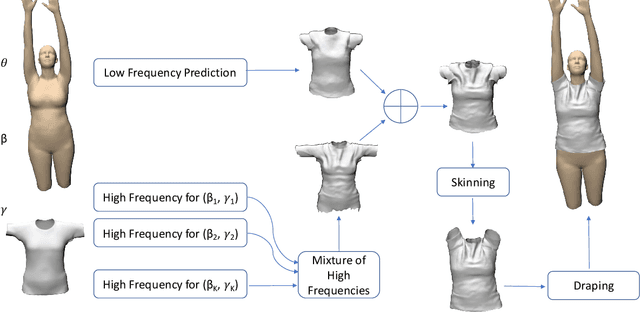


In this paper, we present TailorNet, a neural model which predicts clothing deformation in 3D as a function of three factors: pose, shape and style (garment geometry), while retaining wrinkle detail. This goes beyond prior models, which are either specific to one style and shape, or generalize to different shapes producing smooth results, despite being style specific. Our hypothesis is that (even non-linear) combinations of examples smooth out high frequency components such as fine-wrinkles, which makes learning the three factors jointly hard. At the heart of our technique is a decomposition of deformation into a high frequency and a low frequency component. While the low-frequency component is predicted from pose, shape and style parameters with an MLP, the high-frequency component is predicted with a mixture of shape-style specific pose models. The weights of the mixture are computed with a narrow bandwidth kernel to guarantee that only predictions with similar high-frequency patterns are combined. The style variation is obtained by computing, in a canonical pose, a subspace of deformation, which satisfies physical constraints such as inter-penetration, and draping on the body. TailorNet delivers 3D garments which retain the wrinkles from the physics based simulations (PBS) it is learned from, while running more than 1000 times faster. In contrast to PBS, TailorNet is easy to use and fully differentiable, which is crucial for computer vision algorithms. Several experiments demonstrate TailorNet produces more realistic results than prior work, and even generates temporally coherent deformations on sequences of the AMASS dataset, despite being trained on static poses from a different dataset. To stimulate further research in this direction, we will make a dataset consisting of 55800 frames, as well as our model publicly available at https://virtualhumans.mpi-inf.mpg.de/tailornet.
HumanMeshNet: Polygonal Mesh Recovery of Humans
Aug 19, 2019
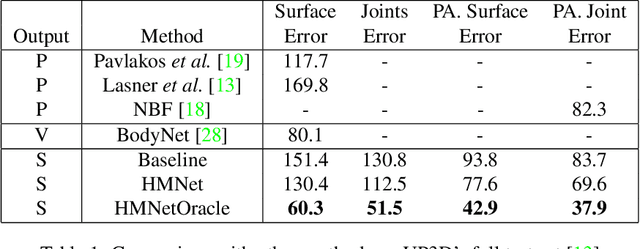
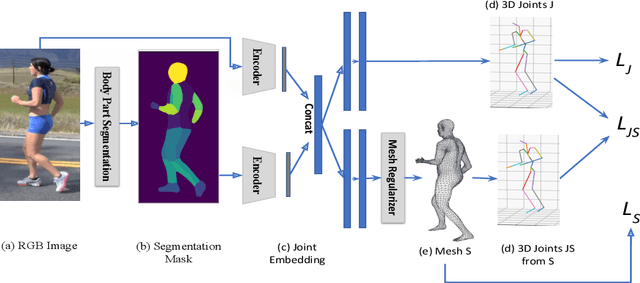
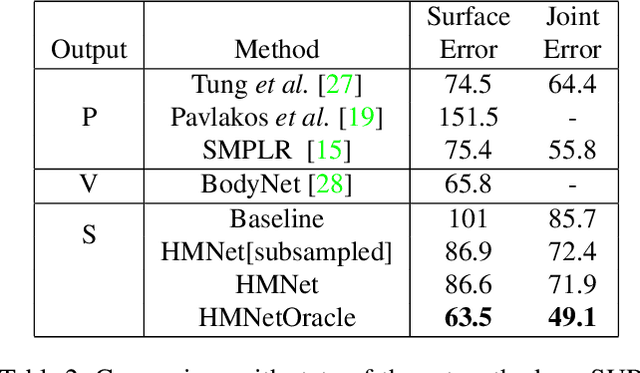
3D Human Body Reconstruction from a monocular image is an important problem in computer vision with applications in virtual and augmented reality platforms, animation industry, en-commerce domain, etc. While several of the existing works formulate it as a volumetric or parametric learning with complex and indirect reliance on re-projections of the mesh, we would like to focus on implicitly learning the mesh representation. To that end, we propose a novel model, HumanMeshNet, that regresses a template mesh's vertices, as well as receives a regularization by the 3D skeletal locations in a multi-branch, multi-task setup. The image to mesh vertex regression is further regularized by the neighborhood constraint imposed by mesh topology ensuring smooth surface reconstruction. The proposed paradigm can theoretically learn local surface deformations induced by body shape variations and can therefore learn high-resolution meshes going ahead. We show comparable performance with SoA (in terms of surface and joint error) with far lesser computational complexity, modeling cost and therefore real-time reconstructions on three publicly available datasets. We also show the generalizability of the proposed paradigm for a similar task of predicting hand mesh models. Given these initial results, we would like to exploit the mesh topology in an explicit manner going ahead.