 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatellite Sunroof: High-res Digital Surface Models and Roof Segmentation for Global Solar Mapping
Aug 26, 2024



The transition to renewable energy, particularly solar, is key to mitigating climate change. Google's Solar API aids this transition by estimating solar potential from aerial imagery, but its impact is constrained by geographical coverage. This paper proposes expanding the API's reach using satellite imagery, enabling global solar potential assessment. We tackle challenges involved in building a Digital Surface Model (DSM) and roof instance segmentation from lower resolution and single oblique views using deep learning models. Our models, trained on aligned satellite and aerial datasets, produce 25cm DSMs and roof segments. With ~1m DSM MAE on buildings, ~5deg roof pitch error and ~56% IOU on roof segmentation, they significantly enhance the Solar API's potential to promote solar adoption.
Cross Modal Distillation for Flood Extent Mapping
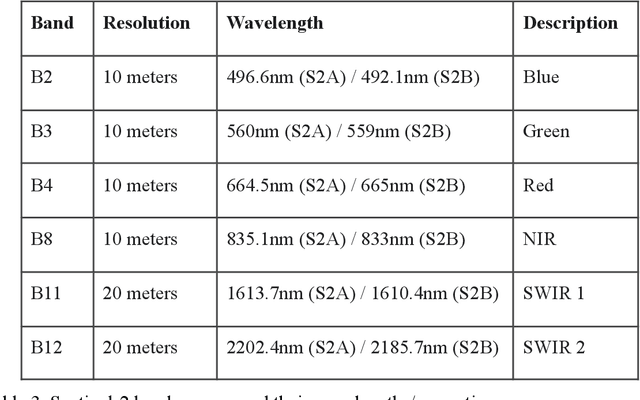
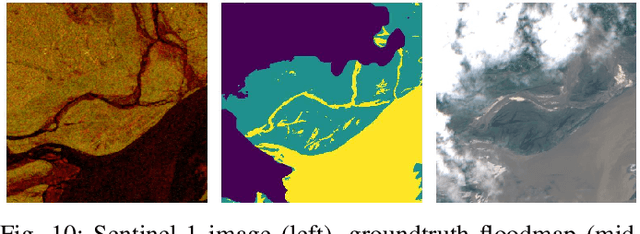
Feb 16, 2023The increasing intensity and frequency of floods is one of the many consequences of our changing climate. In this work, we explore ML techniques that improve the flood detection module of an operational early flood warning system. Our method exploits an unlabelled dataset of paired multi-spectral and Synthetic Aperture Radar (SAR) imagery to reduce the labeling requirements of a purely supervised learning method. Prior works have used unlabelled data by creating weak labels out of them. However, from our experiments we noticed that such a model still ends up learning the label mistakes in those weak labels. Motivated by knowledge distillation and semi supervised learning, we explore the use of a teacher to train a student with the help of a small hand labelled dataset and a large unlabelled dataset. Unlike the conventional self distillation setup, we propose a cross modal distillation framework that transfers supervision from a teacher trained on richer modality (multi-spectral images) to a student model trained on SAR imagery. The trained models are then tested on the Sen1Floods11 dataset. Our model outperforms the Sen1Floods11 baseline model trained on the weak labeled SAR imagery by an absolute margin of 6.53% Intersection-over-Union (IoU) on the test split.
Multimodal contrastive learning for remote sensing tasks
Sep 06, 2022
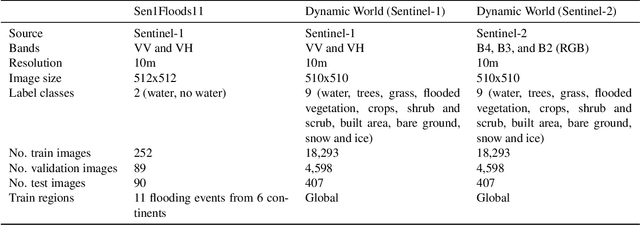

Self-supervised methods have shown tremendous success in the field of computer vision, including applications in remote sensing and medical imaging. Most popular contrastive-loss based methods like SimCLR, MoCo, MoCo-v2 use multiple views of the same image by applying contrived augmentations on the image to create positive pairs and contrast them with negative examples. Although these techniques work well, most of these techniques have been tuned on ImageNet (and similar computer vision datasets). While there have been some attempts to capture a richer set of deformations in the positive samples, in this work, we explore a promising alternative to generating positive examples for remote sensing data within the contrastive learning framework. Images captured from different sensors at the same location and nearby timestamps can be thought of as strongly augmented instances of the same scene, thus removing the need to explore and tune a set of hand crafted strong augmentations. In this paper, we propose a simple dual-encoder framework, which is pre-trained on a large unlabeled dataset (~1M) of Sentinel-1 and Sentinel-2 image pairs. We test the embeddings on two remote sensing downstream tasks: flood segmentation and land cover mapping, and empirically show that embeddings learnt from this technique outperform the conventional technique of collecting positive examples via aggressive data augmentations.
A Machine Learning Data Fusion Model for Soil Moisture Retrieval
Jun 20, 2022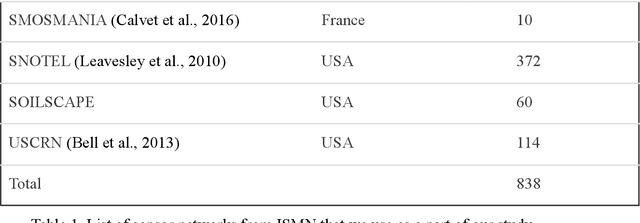
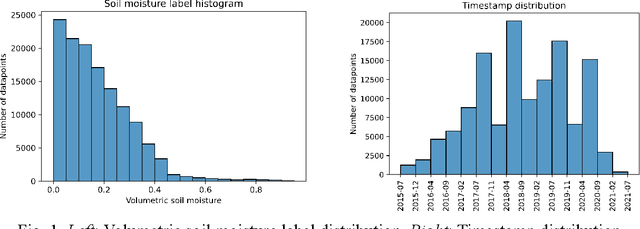
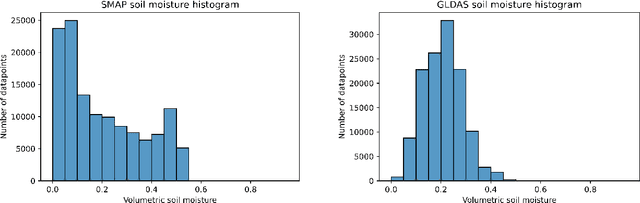
We develop a deep learning based convolutional-regression model that estimates the volumetric soil moisture content in the top ~5 cm of soil. Input predictors include Sentinel-1 (active radar), Sentinel-2 (optical imagery), and SMAP (passive radar) as well as geophysical variables from SoilGrids and modelled soil moisture fields from GLDAS. The model was trained and evaluated on data from ~1300 in-situ sensors globally over the period 2015 - 2021 and obtained an average per-sensor correlation of 0.727 and ubRMSE of 0.054, and can be used to produce a soil moisture map at a nominal 320m resolution. These results are benchmarked against 13 other soil moisture works at different locations, and an ablation study was used to identify important predictors.
Evaluating Self and Semi-Supervised Methods for Remote Sensing Segmentation Tasks
Nov 19, 2021


We perform a rigorous evaluation of recent self and semi-supervised ML techniques that leverage unlabeled data for improving downstream task performance, on three remote sensing tasks of riverbed segmentation, land cover mapping and flood mapping. These methods are especially valuable for remote sensing tasks since there is easy access to unlabeled imagery and getting ground truth labels can often be expensive. We quantify performance improvements one can expect on these remote sensing segmentation tasks when unlabeled imagery (outside of the labeled dataset) is made available for training. We also design experiments to test the effectiveness of these techniques when the test set has a domain shift relative to the training and validation sets.
Inundation Modeling in Data Scarce Regions
Oct 30, 2019

Flood forecasts are crucial for effective individual and governmental protective action. The vast majority of flood-related casualties occur in developing countries, where providing spatially accurate forecasts is a challenge due to scarcity of data and lack of funding. This paper describes an operational system providing flood extent forecast maps covering several flood-prone regions in India, with the goal of being sufficiently scalable and cost-efficient to facilitate the establishment of effective flood forecasting systems globally.
Grader variability and the importance of reference standards for evaluating machine learning models for diabetic retinopathy
Jul 03, 2018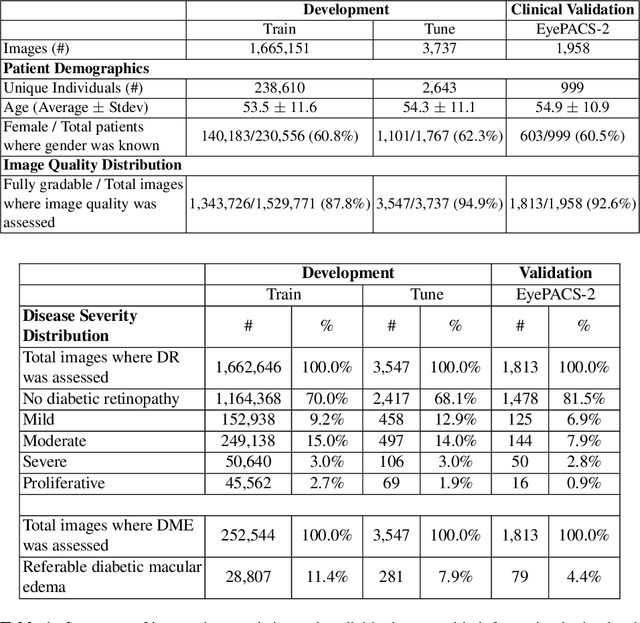
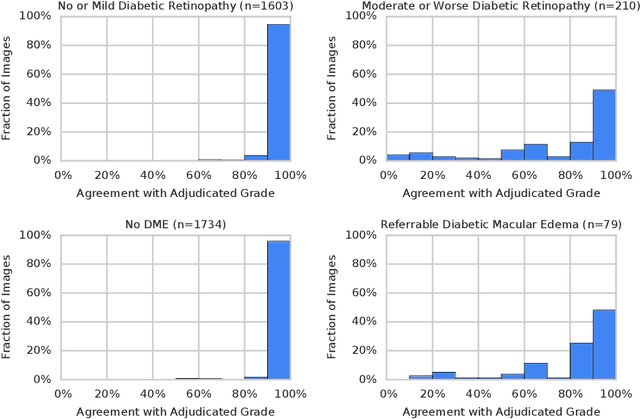
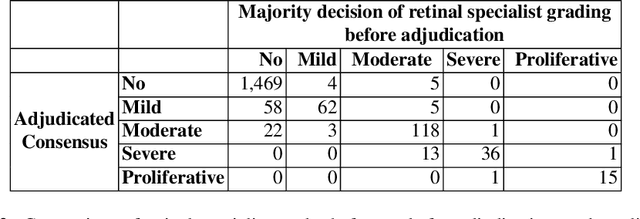
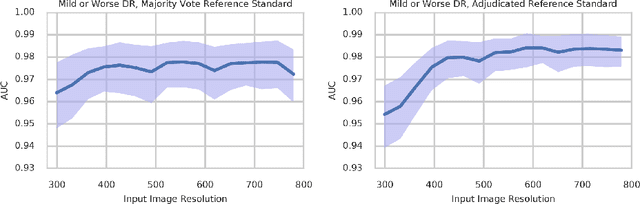
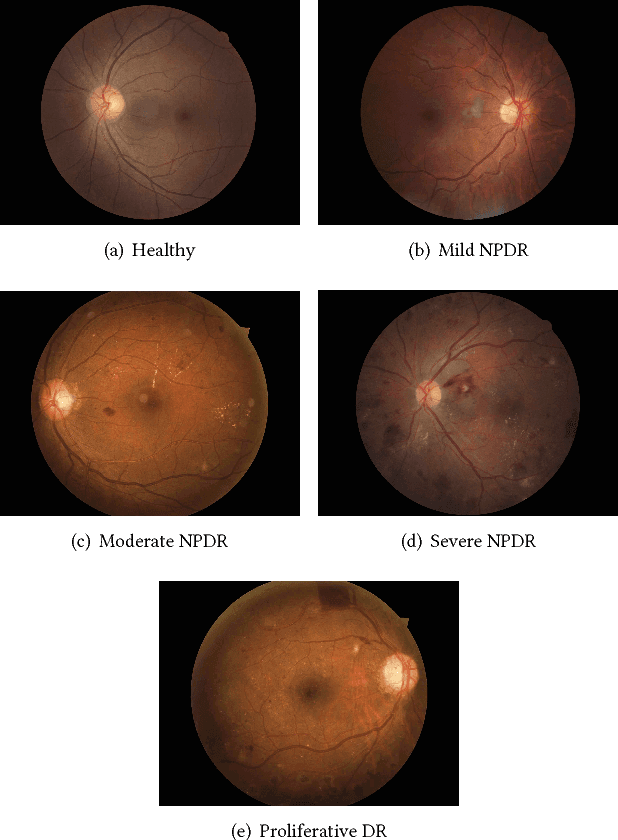
Diabetic retinopathy (DR) and diabetic macular edema are common complications of diabetes which can lead to vision loss. The grading of DR is a fairly complex process that requires the detection of fine features such as microaneurysms, intraretinal hemorrhages, and intraretinal microvascular abnormalities. Because of this, there can be a fair amount of grader variability. There are different methods of obtaining the reference standard and resolving disagreements between graders, and while it is usually accepted that adjudication until full consensus will yield the best reference standard, the difference between various methods of resolving disagreements has not been examined extensively. In this study, we examine the variability in different methods of grading, definitions of reference standards, and their effects on building deep learning models for the detection of diabetic eye disease. We find that a small set of adjudicated DR grades allows substantial improvements in algorithm performance. The resulting algorithm's performance was on par with that of individual U.S. board-certified ophthalmologists and retinal specialists.
Who Said What: Modeling Individual Labelers Improves Classification
Jan 04, 2018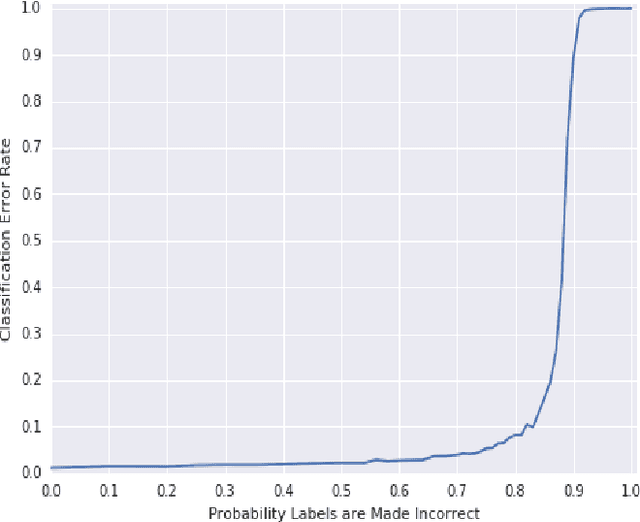
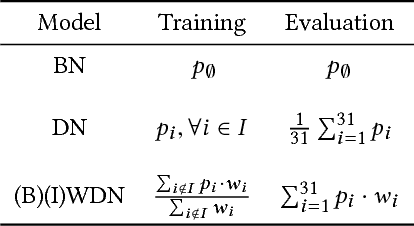
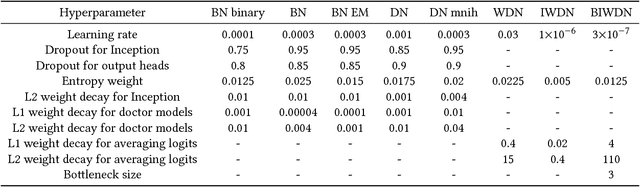
Data are often labeled by many different experts with each expert only labeling a small fraction of the data and each data point being labeled by several experts. This reduces the workload on individual experts and also gives a better estimate of the unobserved ground truth. When experts disagree, the standard approaches are to treat the majority opinion as the correct label or to model the correct label as a distribution. These approaches, however, do not make any use of potentially valuable information about which expert produced which label. To make use of this extra information, we propose modeling the experts individually and then learning averaging weights for combining them, possibly in sample-specific ways. This allows us to give more weight to more reliable experts and take advantage of the unique strengths of individual experts at classifying certain types of data. Here we show that our approach leads to improvements in computer-aided diagnosis of diabetic retinopathy. We also show that our method performs better than competing algorithms by Welinder and Perona (2010), and by Mnih and Hinton (2012). Our work offers an innovative approach for dealing with the myriad real-world settings that use expert opinions to define labels for training.