 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Building and Road Detection from Sentinel-2
Oct 17, 2023



Mapping buildings and roads automatically with remote sensing typically requires high-resolution imagery, which is expensive to obtain and often sparsely available. In this work we demonstrate how multiple 10 m resolution Sentinel-2 images can be used to generate 50 cm resolution building and road segmentation masks. This is done by training a `student' model with access to Sentinel-2 images to reproduce the predictions of a `teacher' model which has access to corresponding high-resolution imagery. While the predictions do not have all the fine detail of the teacher model, we find that we are able to retain much of the performance: for building segmentation we achieve 78.3% mIoU, compared to the high-resolution teacher model accuracy of 85.3% mIoU. We also describe a related method for counting individual buildings in a Sentinel-2 patch which achieves R^2 = 0.91 against true counts. This work opens up new possibilities for using freely available Sentinel-2 imagery for a range of tasks that previously could only be done with high-resolution satellite imagery.
AI Increases Global Access to Reliable Flood Forecasts
Aug 10, 2023



Floods are one of the most common and impactful natural disasters, with a disproportionate impact in developing countries that often lack dense streamflow monitoring networks. Accurate and timely warnings are critical for mitigating flood risks, but accurate hydrological simulation models typically must be calibrated to long data records in each watershed where they are applied. We developed an Artificial Intelligence (AI) model to predict extreme hydrological events at timescales up to 7 days in advance. This model significantly outperforms current state of the art global hydrology models (the Copernicus Emergency Management Service Global Flood Awareness System) across all continents, lead times, and return periods. AI is especially effective at forecasting in ungauged basins, which is important because only a few percent of the world's watersheds have stream gauges, with a disproportionate number of ungauged basins in developing countries that are especially vulnerable to the human impacts of flooding. We produce forecasts of extreme events in South America and Africa that achieve reliability approaching the current state of the art in Europe and North America, and we achieve reliability at between 4 and 6-day lead times that are similar to current state of the art nowcasts (0-day lead time). Additionally, we achieve accuracies over 10-year return period events that are similar to current accuracies over 2-year return period events, meaning that AI can provide warnings earlier and over larger and more impactful events. The model that we develop in this paper has been incorporated into an operational early warning system that produces publicly available (free and open) forecasts in real time in over 80 countries. This work using AI and open data highlights a need for increasing the availability of hydrological data to continue to improve global access to reliable flood warnings.
On pseudo-absence generation and machine learning for locust breeding ground prediction in Africa
Nov 06, 2021


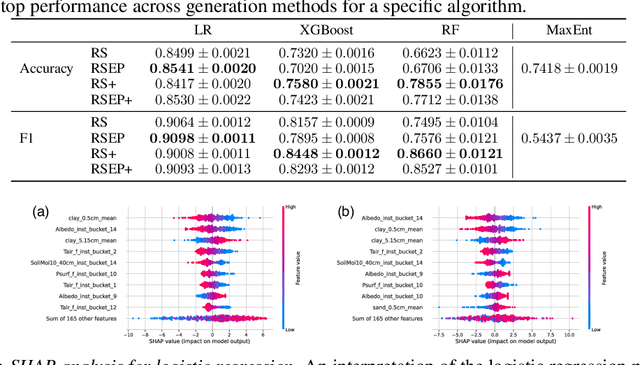
Desert locust outbreaks threaten the food security of a large part of Africa and have affected the livelihoods of millions of people over the years. Machine learning (ML) has been demonstrated as an effective approach to locust distribution modelling which could assist in early warning. ML requires a significant amount of labelled data to train. Most publicly available labelled data on locusts are presence-only data, where only the sightings of locusts being present at a location are recorded. Therefore, prior work using ML have resorted to pseudo-absence generation methods as a way to circumvent this issue. The most commonly used approach is to randomly sample points in a region of interest while ensuring that these sampled pseudo-absence points are at least a specific distance away from true presence points. In this paper, we compare this random sampling approach to more advanced pseudo-absence generation methods, such as environmental profiling and optimal background extent limitation, specifically for predicting desert locust breeding grounds in Africa. Interestingly, we find that for the algorithms we tested, namely logistic regression, gradient boosting, random forests and maximum entropy, all popular in prior work, the logistic model performed significantly better than the more sophisticated ensemble methods, both in terms of prediction accuracy and F1 score. Although background extent limitation combined with random sampling boosted performance for ensemble methods, for LR this was not the case, and instead, a significant improvement was obtained when using environmental profiling. In light of this, we conclude that a simpler ML approach such as logistic regression combined with more advanced pseudo-absence generation, specifically environmental profiling, can be a sensible and effective approach to predicting locust breeding grounds across Africa.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021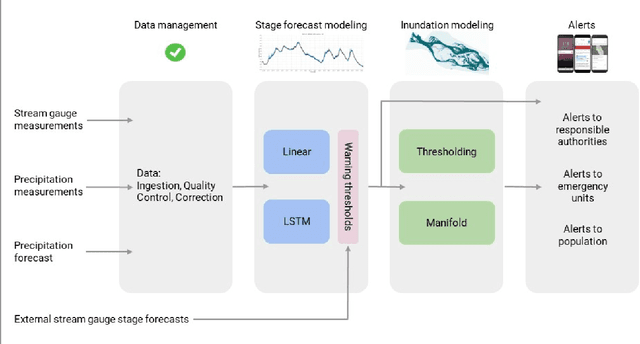
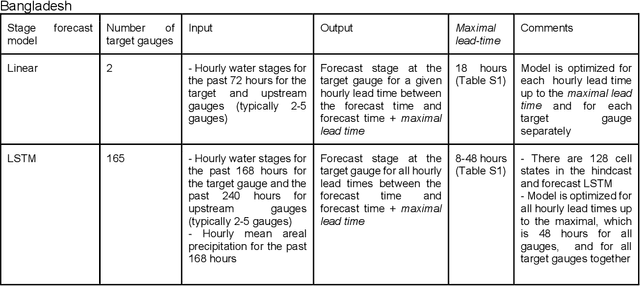
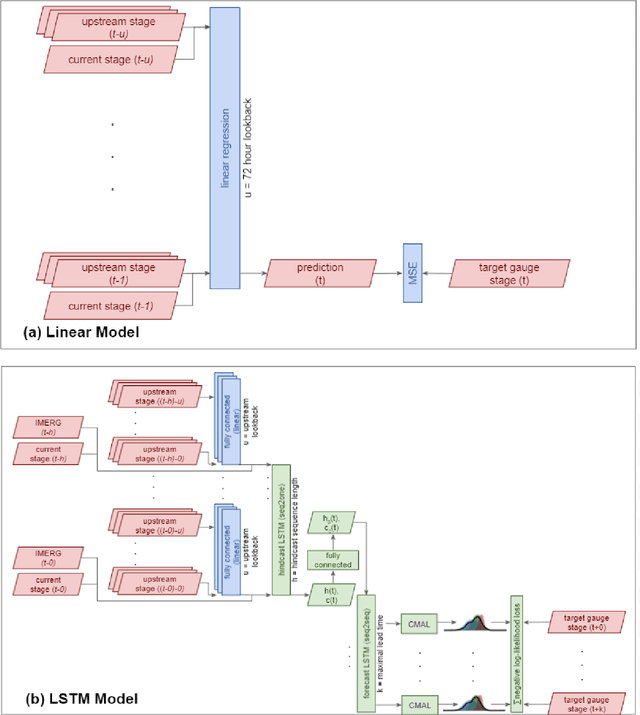
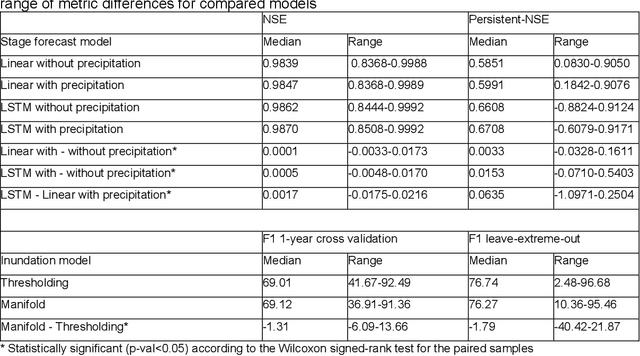
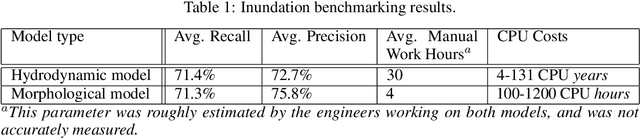
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
Physics-Aware Downsampling with Deep Learning for Scalable Flood Modeling
Jun 14, 2021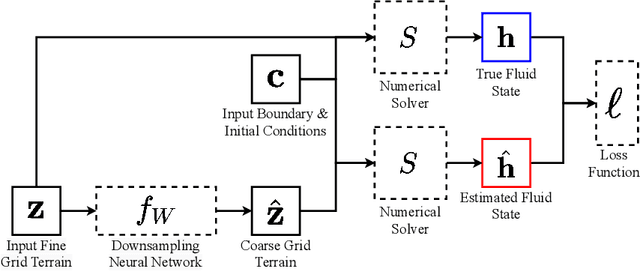
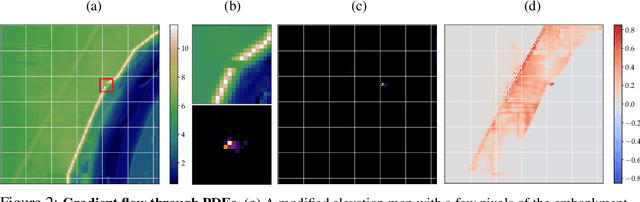
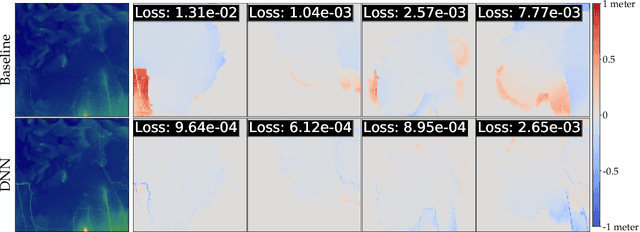

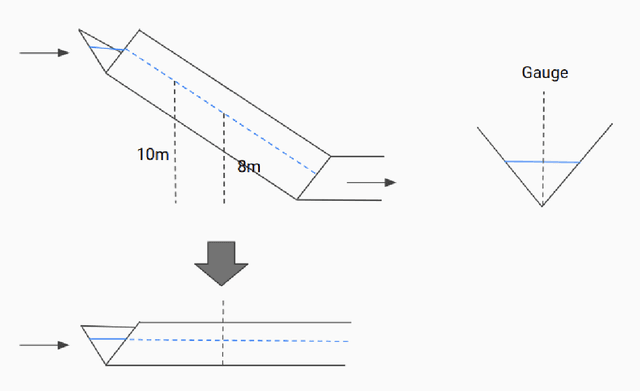
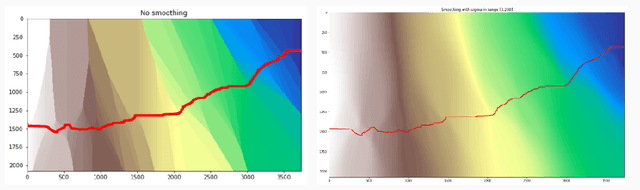
Background: Floods are the most common natural disaster in the world, affecting the lives of hundreds of millions. Flood forecasting is therefore a vitally important endeavor, typically achieved using physical water flow simulations, which rely on accurate terrain elevation maps. However, such simulations, based on solving partial differential equations, are computationally prohibitive on a large scale. This scalability issue is commonly alleviated using a coarse grid representation of the elevation map, though this representation may distort crucial terrain details, leading to significant inaccuracies in the simulation. Contributions: We train a deep neural network to perform physics-informed downsampling of the terrain map: we optimize the coarse grid representation of the terrain maps, so that the flood prediction will match the fine grid solution. For the learning process to succeed, we configure a dataset specifically for this task. We demonstrate that with this method, it is possible to achieve a significant reduction in computational cost, while maintaining an accurate solution. A reference implementation accompanies the paper as well as documentation and code for dataset reproduction.
ML-based Flood Forecasting: Advances in Scale, Accuracy and Reach
Dec 06, 2020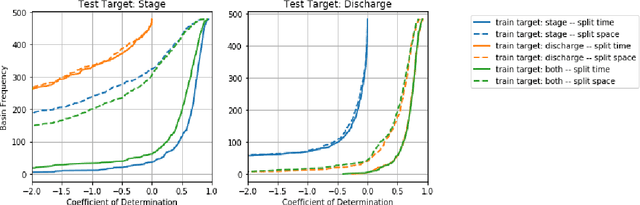
Floods are among the most common and deadly natural disasters in the world, and flood warning systems have been shown to be effective in reducing harm. Yet the majority of the world's vulnerable population does not have access to reliable and actionable warning systems, due to core challenges in scalability, computational costs, and data availability. In this paper we present two components of flood forecasting systems which were developed over the past year, providing access to these critical systems to 75 million people who didn't have this access before.
HydroNets: Leveraging River Structure for Hydrologic Modeling
Jul 01, 2020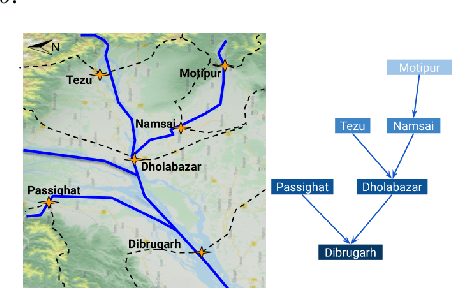
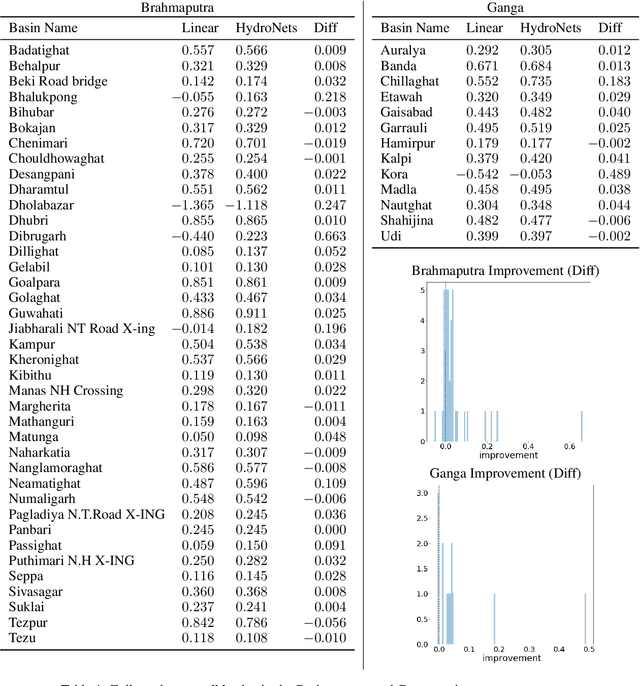
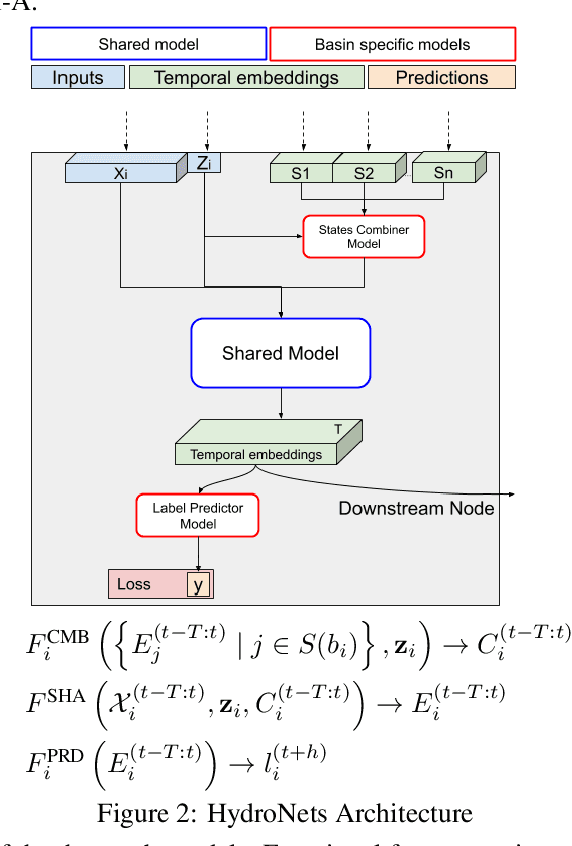

Accurate and scalable hydrologic models are essential building blocks of several important applications, from water resource management to timely flood warnings. However, as the climate changes, precipitation and rainfall-runoff pattern variations become more extreme, and accurate training data that can account for the resulting distributional shifts become more scarce. In this work we present a novel family of hydrologic models, called HydroNets, which leverages river network structure. HydroNets are deep neural network models designed to exploit both basin specific rainfall-runoff signals, and upstream network dynamics, which can lead to improved predictions at longer horizons. The injection of the river structure prior knowledge reduces sample complexity and allows for scalable and more accurate hydrologic modeling even with only a few years of data. We present an empirical study over two large basins in India that convincingly support the proposed model and its advantages.
Accurate Hydrologic Modeling Using Less Information
Nov 21, 2019
Joint models are a common and important tool in the intersection of machine learning and the physical sciences, particularly in contexts where real-world measurements are scarce. Recent developments in rainfall-runoff modeling, one of the prime challenges in hydrology, show the value of a joint model with shared representation in this important context. However, current state-of-the-art models depend on detailed and reliable attributes characterizing each site to help the model differentiate correctly between the behavior of different sites. This dependency can present a challenge in data-poor regions. In this paper, we show that we can replace the need for such location-specific attributes with a completely data-driven learned embedding, and match previous state-of-the-art results with less information.
Inundation Modeling in Data Scarce Regions
Oct 30, 2019

Flood forecasts are crucial for effective individual and governmental protective action. The vast majority of flood-related casualties occur in developing countries, where providing spatially accurate forecasts is a challenge due to scarcity of data and lack of funding. This paper describes an operational system providing flood extent forecast maps covering several flood-prone regions in India, with the goal of being sufficiently scalable and cost-efficient to facilitate the establishment of effective flood forecasting systems globally.
Spectral Algorithm for Low-rank Multitask Regression
Oct 27, 2019

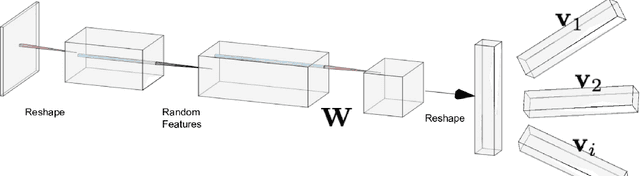

Multitask learning, i.e. taking advantage of the relatedness of individual tasks in order to improve performance on all of them, is a core challenge in the field of machine learning. We focus on matrix regression tasks where the rank of the weight matrix is constrained to reduce sample complexity. We introduce the common mechanism regression (CMR) model which assumes a shared left low-rank component across all tasks, but allows an individual per-task right low-rank component. This dramatically reduces the number of samples needed for accurate estimation. The problem of jointly recovering the common and the local components has a non-convex bi-linear structure. We overcome this hurdle and provide a provably beneficial non-iterative spectral algorithm. Appealingly, the solution has favorable behavior as a function of the number of related tasks and the small number of samples available for each one. We demonstrate the efficacy of our approach for the challenging task of remote river discharge estimation across multiple river sites, where data for each task is naturally scarce. In this scenario sharing a low-rank component between the tasks translates to a shared spectral reflection of the water, which is a true underlying physical model. We also show the benefit of the approach on the markedly different setting of image classification where the common component can be interpreted as the shared convolution filters.