 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP-OOD: Attention Pooling for Out-of-Distribution Detection
Feb 05, 2026Out-of-distribution (OOD) detection, which maps high-dimensional data into a scalar OOD score, is critical for the reliable deployment of machine learning models. A key challenge in recent research is how to effectively leverage and aggregate token embeddings from language models to obtain the OOD score. In this work, we propose AP-OOD, a novel OOD detection method for natural language that goes beyond simple average-based aggregation by exploiting token-level information. AP-OOD is a semi-supervised approach that flexibly interpolates between unsupervised and supervised settings, enabling the use of limited auxiliary outlier data. Empirically, AP-OOD sets a new state of the art in OOD detection for text: in the unsupervised setting, it reduces the FPR95 (false positive rate at 95% true positives) from 27.84% to 4.67% on XSUM summarization, and from 77.08% to 70.37% on WMT15 En-Fr translation.
Pre-trained Forecasting Models: Strong Zero-Shot Feature Extractors for Time Series Classification
Oct 30, 2025



Recent research on time series foundation models has primarily focused on forecasting, leaving it unclear how generalizable their learned representations are. In this study, we examine whether frozen pre-trained forecasting models can provide effective representations for classification. To this end, we compare different representation extraction strategies and introduce two model-agnostic embedding augmentations. Our experiments show that the best forecasting models achieve classification accuracy that matches or even surpasses that of state-of-the-art models pre-trained specifically for classification. Moreover, we observe a positive correlation between forecasting and classification performance. These findings challenge the assumption that task-specific pre-training is necessary, and suggest that learning to forecast may provide a powerful route toward constructing general-purpose time series foundation models.
TiRex: Zero-Shot Forecasting Across Long and Short Horizons with Enhanced In-Context Learning
May 29, 2025In-context learning, the ability of large language models to perform tasks using only examples provided in the prompt, has recently been adapted for time series forecasting. This paradigm enables zero-shot prediction, where past values serve as context for forecasting future values, making powerful forecasting tools accessible to non-experts and increasing the performance when training data are scarce. Most existing zero-shot forecasting approaches rely on transformer architectures, which, despite their success in language, often fall short of expectations in time series forecasting, where recurrent models like LSTMs frequently have the edge. Conversely, while LSTMs are well-suited for time series modeling due to their state-tracking capabilities, they lack strong in-context learning abilities. We introduce TiRex that closes this gap by leveraging xLSTM, an enhanced LSTM with competitive in-context learning skills. Unlike transformers, state-space models, or parallelizable RNNs such as RWKV, TiRex retains state-tracking, a critical property for long-horizon forecasting. To further facilitate its state-tracking ability, we propose a training-time masking strategy called CPM. TiRex sets a new state of the art in zero-shot time series forecasting on the HuggingFace benchmarks GiftEval and Chronos-ZS, outperforming significantly larger models including TabPFN-TS (Prior Labs), Chronos Bolt (Amazon), TimesFM (Google), and Moirai (Salesforce) across both short- and long-term forecasts.
Simplified priors for Object-Centric Learning
Oct 01, 2024



Humans excel at abstracting data and constructing \emph{reusable} concepts, a capability lacking in current continual learning systems. The field of object-centric learning addresses this by developing abstract representations, or slots, from data without human supervision. Different methods have been proposed to tackle this task for images, whereas most are overly complex, non-differentiable, or poorly scalable. In this paper, we introduce a conceptually simple, fully-differentiable, non-iterative, and scalable method called SAMP Simplified Slot Attention with Max Pool Priors). It is implementable using only Convolution and MaxPool layers and an Attention layer. Our method encodes the input image with a Convolutional Neural Network and then uses a branch of alternating Convolution and MaxPool layers to create specialized sub-networks and extract primitive slots. These primitive slots are then used as queries for a Simplified Slot Attention over the encoded image. Despite its simplicity, our method is competitive or outperforms previous methods on standard benchmarks.
Energy-based Hopfield Boosting for Out-of-Distribution Detection
May 14, 2024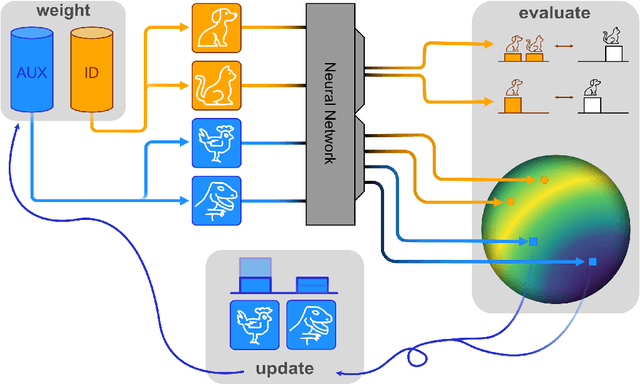
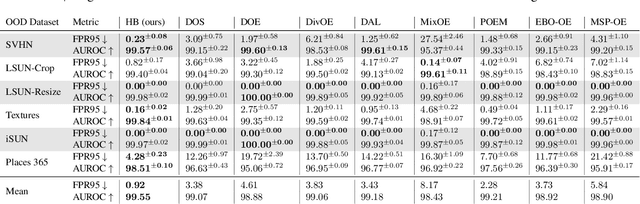
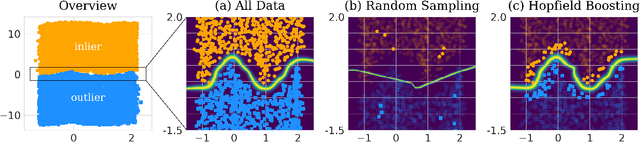
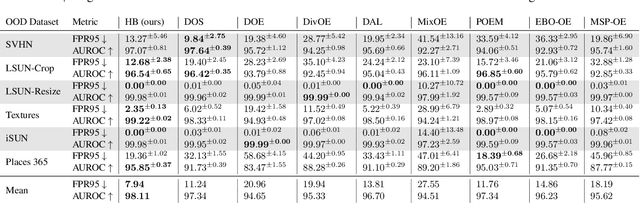
Out-of-distribution (OOD) detection is critical when deploying machine learning models in the real world. Outlier exposure methods, which incorporate auxiliary outlier data in the training process, can drastically improve OOD detection performance compared to approaches without advanced training strategies. We introduce Hopfield Boosting, a boosting approach, which leverages modern Hopfield energy (MHE) to sharpen the decision boundary between the in-distribution and OOD data. Hopfield Boosting encourages the model to concentrate on hard-to-distinguish auxiliary outlier examples that lie close to the decision boundary between in-distribution and auxiliary outlier data. Our method achieves a new state-of-the-art in OOD detection with outlier exposure, improving the FPR95 metric from 2.28 to 0.92 on CIFAR-10 and from 11.76 to 7.94 on CIFAR-100.
Conformal Prediction for Time Series with Modern Hopfield Networks
Mar 22, 2023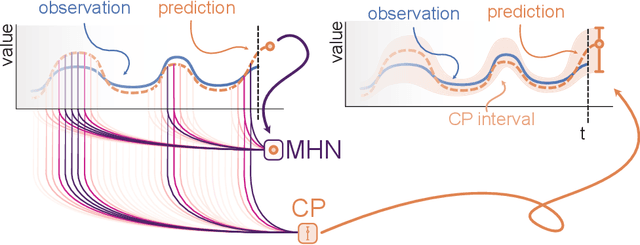
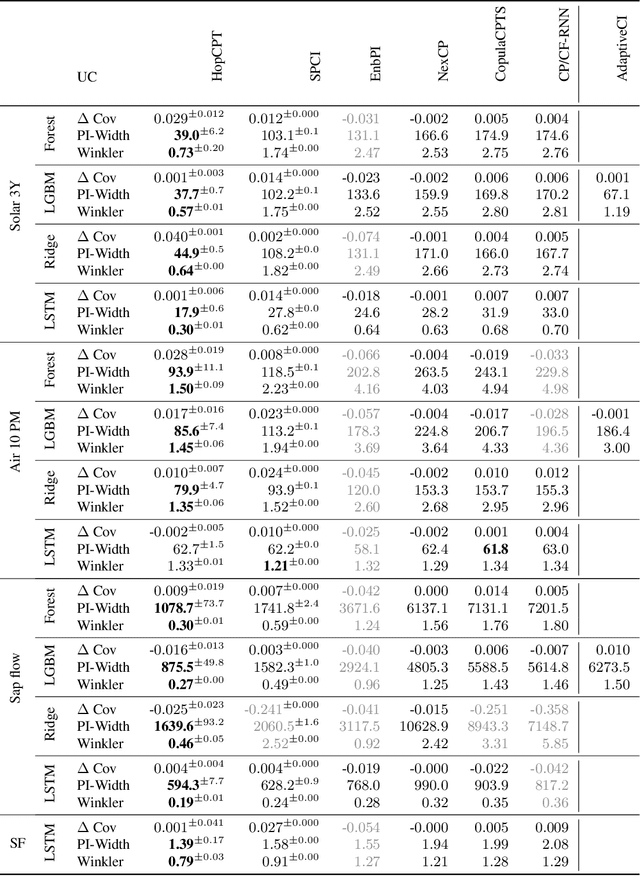
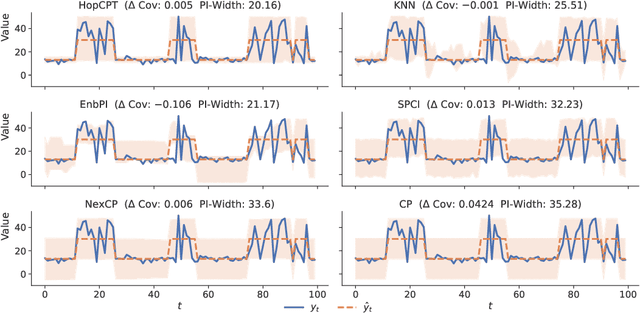
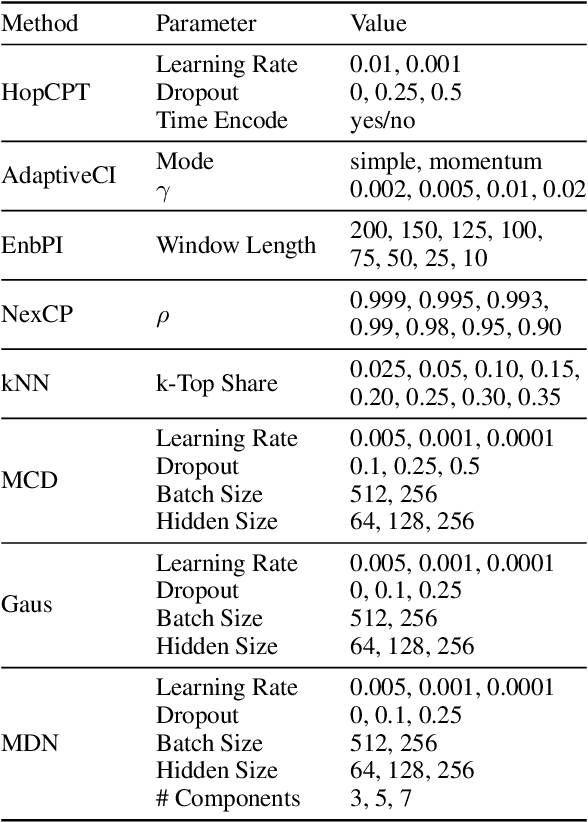
To quantify uncertainty, conformal prediction methods are gaining continuously more interest and have already been successfully applied to various domains. However, they are difficult to apply to time series as the autocorrelative structure of time series violates basic assumptions required by conformal prediction. We propose HopCPT, a novel conformal prediction approach for time series that not only copes with temporal structures but leverages them. We show that our approach is theoretically well justified for time series where temporal dependencies are present. In experiments, we demonstrate that our new approach outperforms state-of-the-art conformal prediction methods on multiple real-world time series datasets from four different domains.
Few-Shot Learning by Dimensionality Reduction in Gradient Space
Jun 07, 2022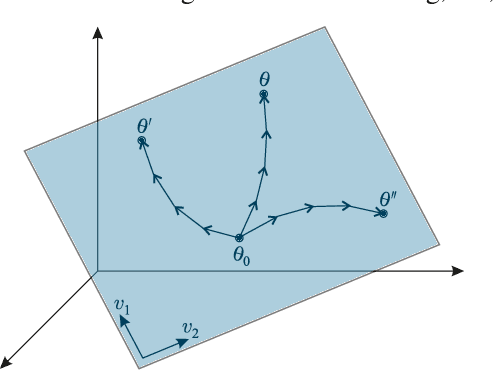
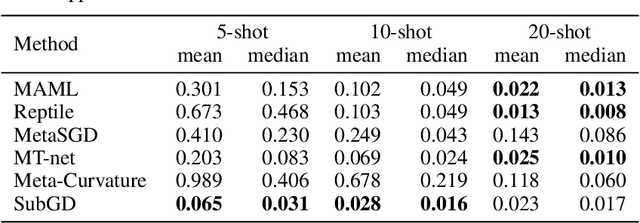
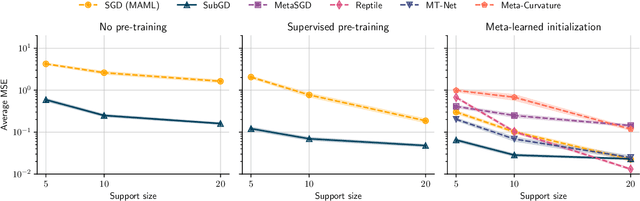
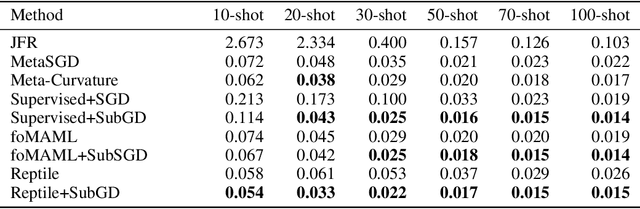
We introduce SubGD, a novel few-shot learning method which is based on the recent finding that stochastic gradient descent updates tend to live in a low-dimensional parameter subspace. In experimental and theoretical analyses, we show that models confined to a suitable predefined subspace generalize well for few-shot learning. A suitable subspace fulfills three criteria across the given tasks: it (a) allows to reduce the training error by gradient flow, (b) leads to models that generalize well, and (c) can be identified by stochastic gradient descent. SubGD identifies these subspaces from an eigendecomposition of the auto-correlation matrix of update directions across different tasks. Demonstrably, we can identify low-dimensional suitable subspaces for few-shot learning of dynamical systems, which have varying properties described by one or few parameters of the analytical system description. Such systems are ubiquitous among real-world applications in science and engineering. We experimentally corroborate the advantages of SubGD on three distinct dynamical systems problem settings, significantly outperforming popular few-shot learning methods both in terms of sample efficiency and performance.
MC-LSTM: Mass-Conserving LSTM
Feb 08, 2021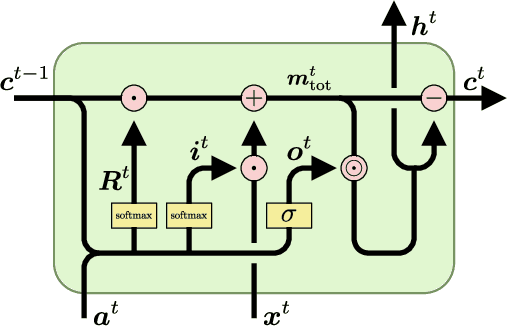
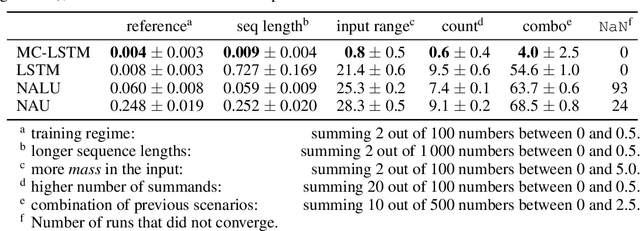
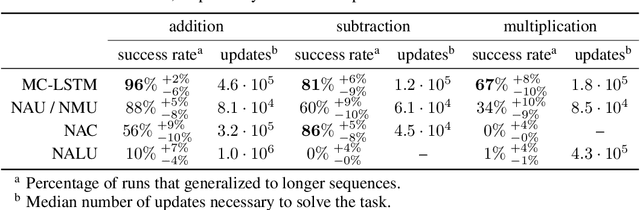
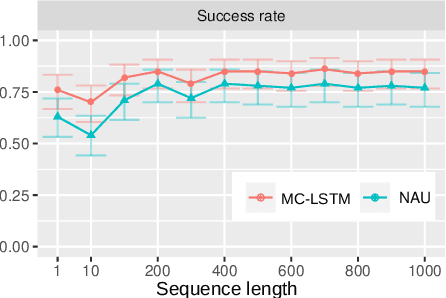
The success of Convolutional Neural Networks (CNNs) in computer vision is mainly driven by their strong inductive bias, which is strong enough to allow CNNs to solve vision-related tasks with random weights, meaning without learning. Similarly, Long Short-Term Memory (LSTM) has a strong inductive bias towards storing information over time. However, many real-world systems are governed by conservation laws, which lead to the redistribution of particular quantities -- e.g. in physical and economical systems. Our novel Mass-Conserving LSTM (MC-LSTM) adheres to these conservation laws by extending the inductive bias of LSTM to model the redistribution of those stored quantities. MC-LSTMs set a new state-of-the-art for neural arithmetic units at learning arithmetic operations, such as addition tasks, which have a strong conservation law, as the sum is constant over time. Further, MC-LSTM is applied to traffic forecasting, modelling a pendulum, and a large benchmark dataset in hydrology, where it sets a new state-of-the-art for predicting peak flows. In the hydrology example, we show that MC-LSTM states correlate with real-world processes and are therefore interpretable.
Uncertainty Estimation with Deep Learning for Rainfall-Runoff Modelling
Dec 15, 2020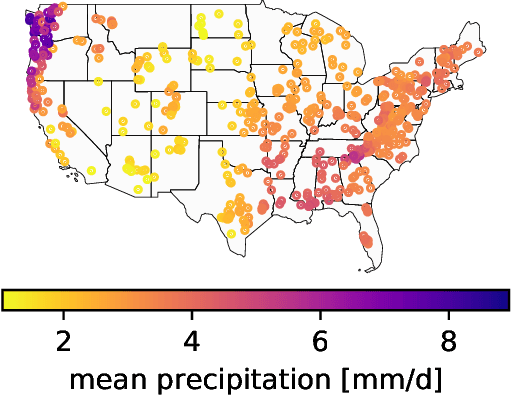
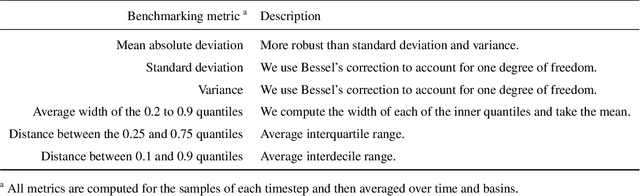
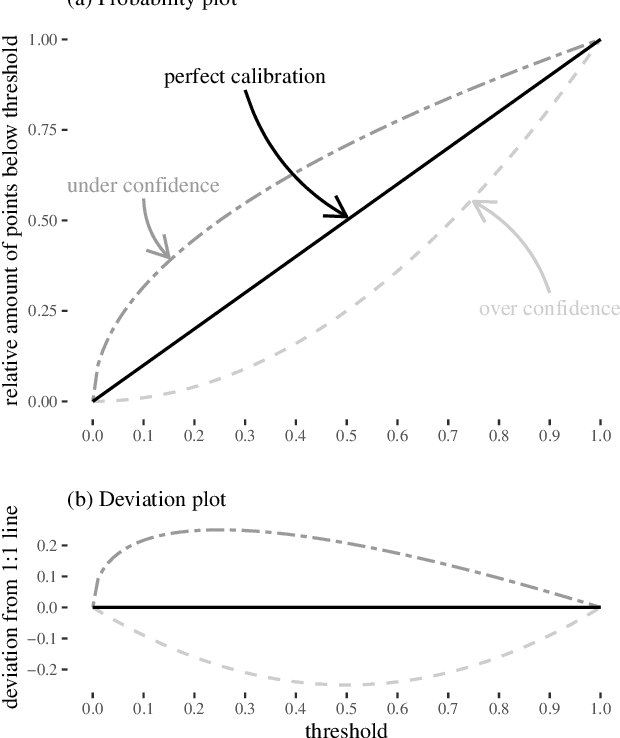
Deep Learning is becoming an increasingly important way to produce accurate hydrological predictions across a wide range of spatial and temporal scales. Uncertainty estimations are critical for actionable hydrological forecasting, and while standardized community benchmarks are becoming an increasingly important part of hydrological model development and research, similar tools for benchmarking uncertainty estimation are lacking. We establish an uncertainty estimation benchmarking procedure and present four Deep Learning baselines, out of which three are based on Mixture Density Networks and one is based on Monte Carlo dropout. Additionally, we provide a post-hoc model analysis to put forward some qualitative understanding of the resulting models. Most importantly however, we show that accurate, precise, and reliable uncertainty estimation can be achieved with Deep Learning.
Rainfall-Runoff Prediction at Multiple Timescales with a Single Long Short-Term Memory Network
Oct 15, 2020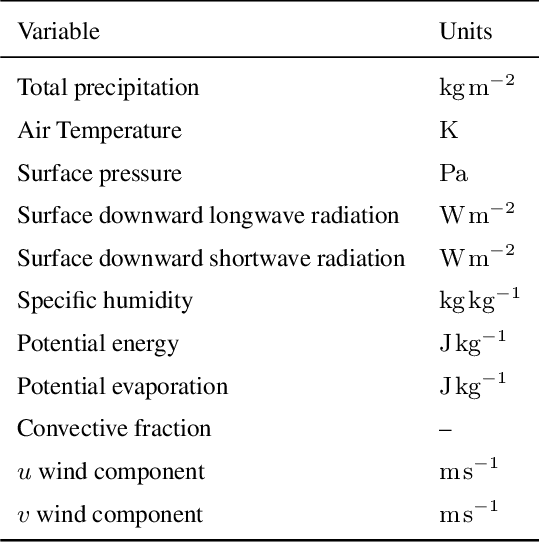
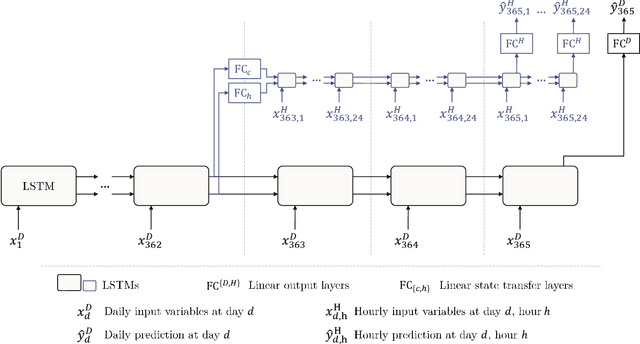

Long Short-Term Memory Networks (LSTMs) have been applied to daily discharge prediction with remarkable success. Many practical scenarios, however, require predictions at more granular timescales. For instance, accurate prediction of short but extreme flood peaks can make a life-saving difference, yet such peaks may escape the coarse temporal resolution of daily predictions. Naively training an LSTM on hourly data, however, entails very long input sequences that make learning hard and computationally expensive. In this study, we propose two Multi-Timescale LSTM (MTS-LSTM) architectures that jointly predict multiple timescales within one model, as they process long-past inputs at a single temporal resolution and branch out into each individual timescale for more recent input steps. We test these models on 516 basins across the continental United States and benchmark against the US National Water Model. Compared to naive prediction with a distinct LSTM per timescale, the multi-timescale architectures are computationally more efficient with no loss in accuracy. Beyond prediction quality, the multi-timescale LSTM can process different input variables at different timescales, which is especially relevant to operational applications where the lead time of meteorological forcings depends on their temporal resolution.