 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation of Time-Series Data in Human Movement Biomechanics: A Scoping Review
Apr 04, 2025The integration of machine learning and deep learning has transformed data analytics in biomechanics, enabled by extensive wearable sensor data. However, the field faces challenges such as limited large-scale datasets and high data acquisition costs, which hinder the development of robust algorithms. Data augmentation techniques show promise in addressing these issues, but their application to biomechanical time-series data requires comprehensive evaluation. This scoping review investigates data augmentation methods for time-series data in the biomechanics domain. It analyzes current approaches for augmenting and generating time-series datasets, evaluates their effectiveness, and offers recommendations for applying these techniques in biomechanics. Four databases, PubMed, IEEE Xplore, Scopus, and Web of Science, were searched for studies published between 2013 and 2024. Following PRISMA-ScR guidelines, a two-stage screening identified 21 relevant publications. Results show that there is no universally preferred method for augmenting biomechanical time-series data; instead, methods vary based on study objectives. A major issue identified is the absence of soft tissue artifacts in synthetic data, leading to discrepancies referred to as the synthetic gap. Moreover, many studies lack proper evaluation of augmentation methods, making it difficult to assess their effects on model performance and data quality. This review highlights the critical role of data augmentation in addressing limited dataset availability and improving model generalization in biomechanics. Tailoring augmentation strategies to the characteristics of biomechanical data is essential for advancing predictive modeling. A better understanding of how different augmentation methods impact data quality and downstream tasks will be key to developing more effective and realistic techniques.
MC-LSTM: Mass-Conserving LSTM
Feb 08, 2021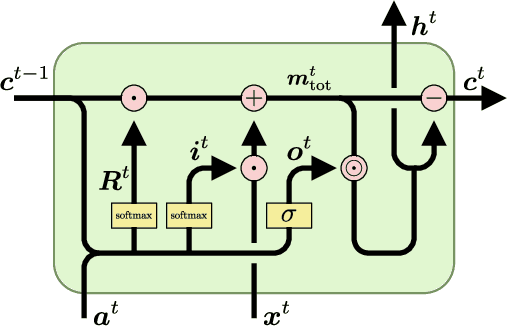
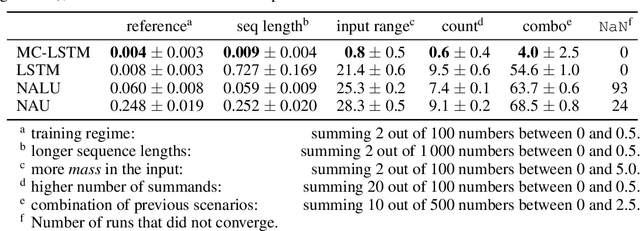
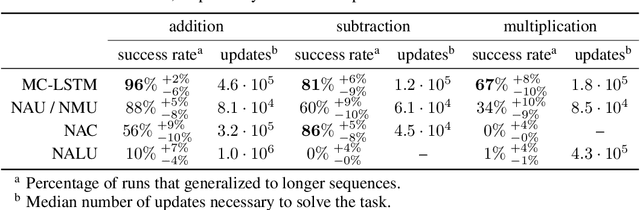
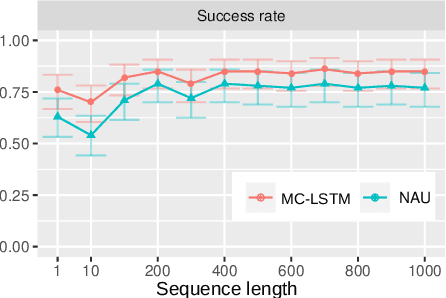
The success of Convolutional Neural Networks (CNNs) in computer vision is mainly driven by their strong inductive bias, which is strong enough to allow CNNs to solve vision-related tasks with random weights, meaning without learning. Similarly, Long Short-Term Memory (LSTM) has a strong inductive bias towards storing information over time. However, many real-world systems are governed by conservation laws, which lead to the redistribution of particular quantities -- e.g. in physical and economical systems. Our novel Mass-Conserving LSTM (MC-LSTM) adheres to these conservation laws by extending the inductive bias of LSTM to model the redistribution of those stored quantities. MC-LSTMs set a new state-of-the-art for neural arithmetic units at learning arithmetic operations, such as addition tasks, which have a strong conservation law, as the sum is constant over time. Further, MC-LSTM is applied to traffic forecasting, modelling a pendulum, and a large benchmark dataset in hydrology, where it sets a new state-of-the-art for predicting peak flows. In the hydrology example, we show that MC-LSTM states correlate with real-world processes and are therefore interpretable.