 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-xLSTM: Generative modeling, representation and in-context learning of biological and chemical sequences
Nov 06, 2024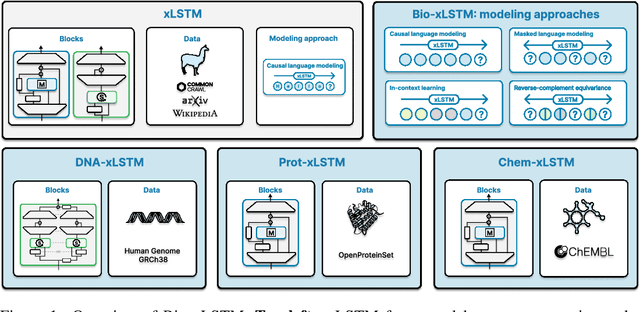
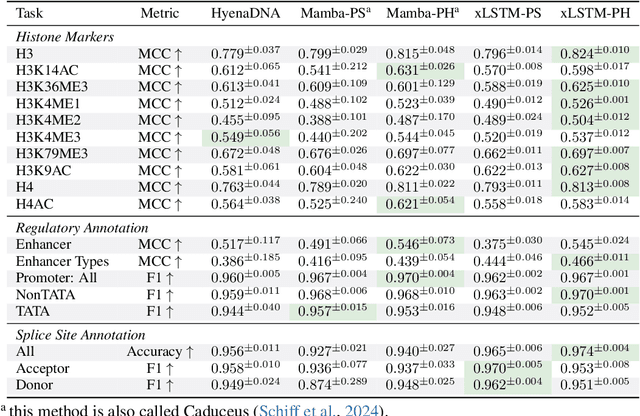
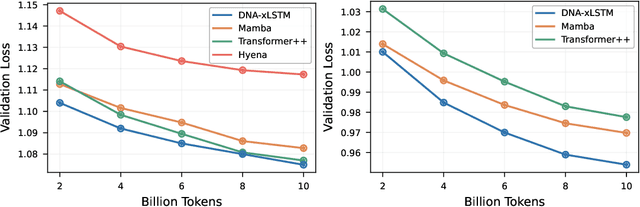
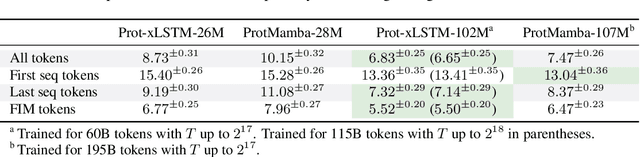
Language models for biological and chemical sequences enable crucial applications such as drug discovery, protein engineering, and precision medicine. Currently, these language models are predominantly based on Transformer architectures. While Transformers have yielded impressive results, their quadratic runtime dependency on the sequence length complicates their use for long genomic sequences and in-context learning on proteins and chemical sequences. Recently, the recurrent xLSTM architecture has been shown to perform favorably compared to Transformers and modern state-space model (SSM) architectures in the natural language domain. Similar to SSMs, xLSTMs have a linear runtime dependency on the sequence length and allow for constant-memory decoding at inference time, which makes them prime candidates for modeling long-range dependencies in biological and chemical sequences. In this work, we tailor xLSTM towards these domains and propose a suite of architectural variants called Bio-xLSTM. Extensive experiments in three large domains, genomics, proteins, and chemistry, were performed to assess xLSTM's ability to model biological and chemical sequences. The results show that models based on Bio-xLSTM a) can serve as proficient generative models for DNA, protein, and chemical sequences, b) learn rich representations for those modalities, and c) can perform in-context learning for proteins and small molecules.
Principled Weight Initialisation for Input-Convex Neural Networks
Dec 19, 2023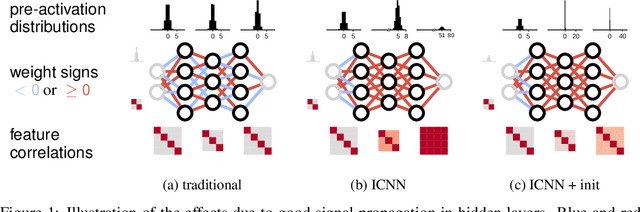
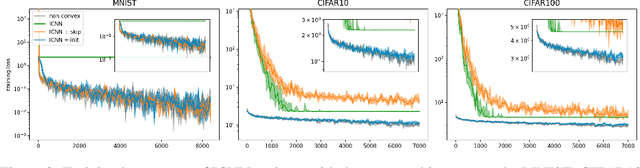
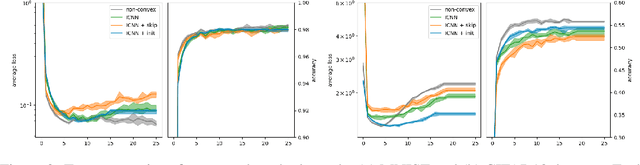
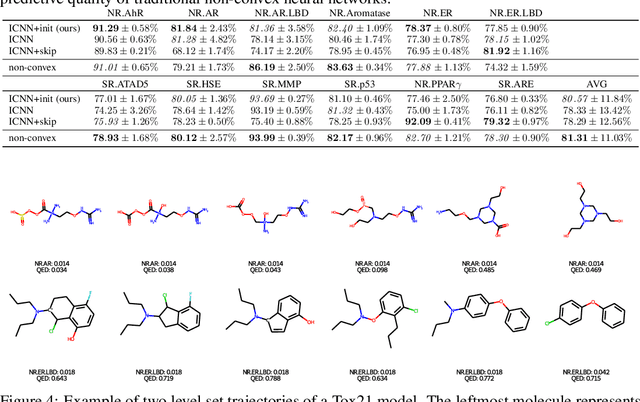
Input-Convex Neural Networks (ICNNs) are networks that guarantee convexity in their input-output mapping. These networks have been successfully applied for energy-based modelling, optimal transport problems and learning invariances. The convexity of ICNNs is achieved by using non-decreasing convex activation functions and non-negative weights. Because of these peculiarities, previous initialisation strategies, which implicitly assume centred weights, are not effective for ICNNs. By studying signal propagation through layers with non-negative weights, we are able to derive a principled weight initialisation for ICNNs. Concretely, we generalise signal propagation theory by removing the assumption that weights are sampled from a centred distribution. In a set of experiments, we demonstrate that our principled initialisation effectively accelerates learning in ICNNs and leads to better generalisation. Moreover, we find that, in contrast to common belief, ICNNs can be trained without skip-connections when initialised correctly. Finally, we apply ICNNs to a real-world drug discovery task and show that they allow for more effective molecular latent space exploration.
MC-LSTM: Mass-Conserving LSTM
Feb 08, 2021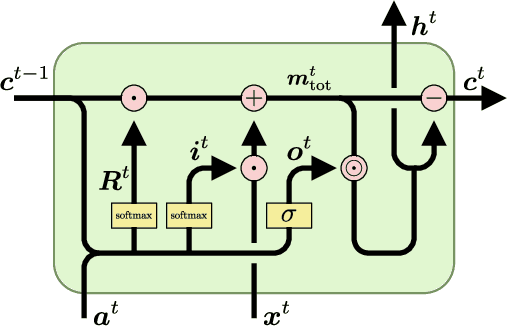
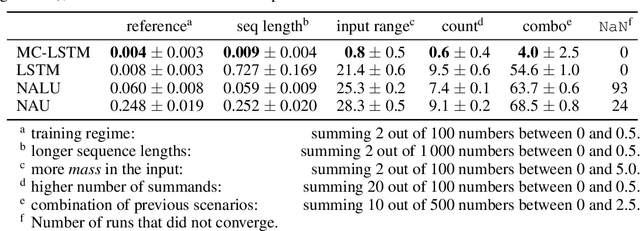
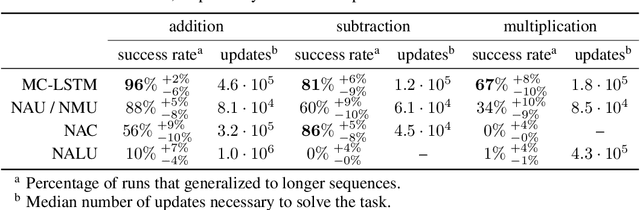
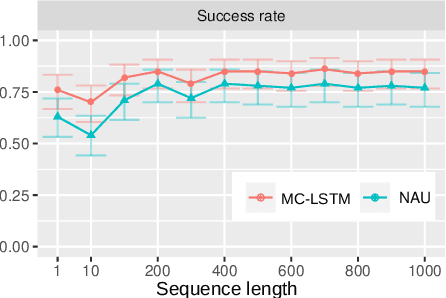
The success of Convolutional Neural Networks (CNNs) in computer vision is mainly driven by their strong inductive bias, which is strong enough to allow CNNs to solve vision-related tasks with random weights, meaning without learning. Similarly, Long Short-Term Memory (LSTM) has a strong inductive bias towards storing information over time. However, many real-world systems are governed by conservation laws, which lead to the redistribution of particular quantities -- e.g. in physical and economical systems. Our novel Mass-Conserving LSTM (MC-LSTM) adheres to these conservation laws by extending the inductive bias of LSTM to model the redistribution of those stored quantities. MC-LSTMs set a new state-of-the-art for neural arithmetic units at learning arithmetic operations, such as addition tasks, which have a strong conservation law, as the sum is constant over time. Further, MC-LSTM is applied to traffic forecasting, modelling a pendulum, and a large benchmark dataset in hydrology, where it sets a new state-of-the-art for predicting peak flows. In the hydrology example, we show that MC-LSTM states correlate with real-world processes and are therefore interpretable.
Using LSTMs for climate change assessment studies on droughts and floods
Nov 28, 2019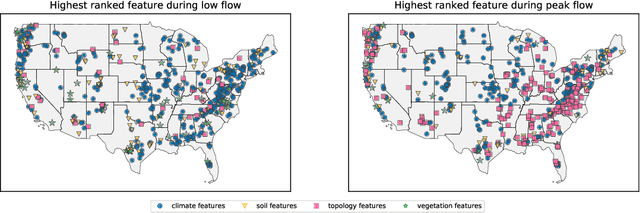
Climate change affects occurrences of floods and droughts worldwide. However, predicting climate impacts over individual watersheds is difficult, primarily because accurate hydrological forecasts require models that are calibrated to past data. In this work we present a large-scale LSTM-based modeling approach that -- by training on large data sets -- learns a diversity of hydrological behaviors. Previous work shows that this model is more accurate than current state-of-the-art models, even when the LSTM-based approach operates out-of-sample and the latter in-sample. In this work, we show how this model can assess the sensitivity of the underlying systems with regard to extreme (high and low) flows in individual watersheds over the continental US.