 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-xLSTM: Generative modeling, representation and in-context learning of biological and chemical sequences
Paper and Code
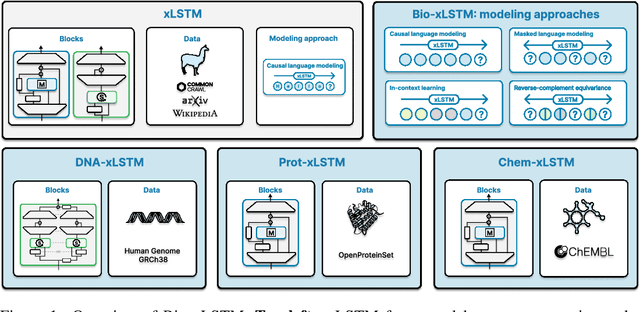
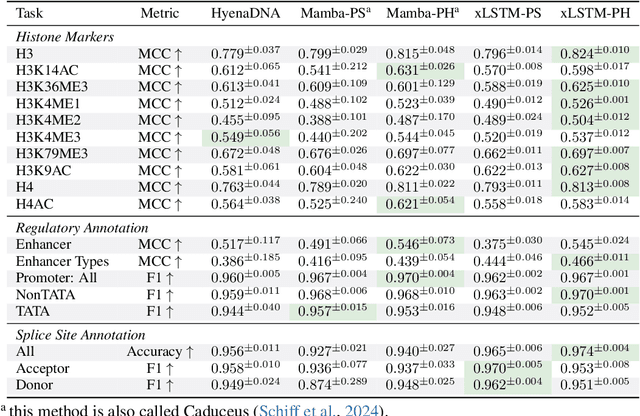
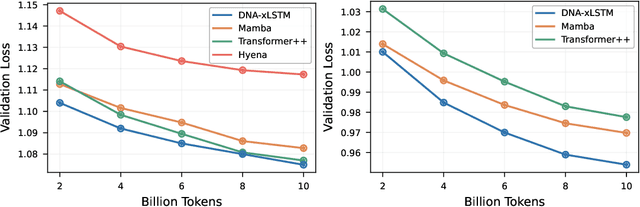
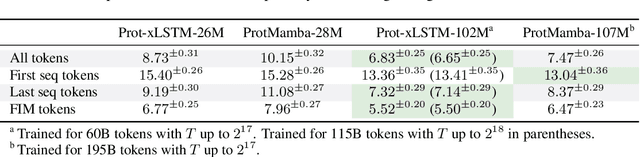
Language models for biological and chemical sequences enable crucial applications such as drug discovery, protein engineering, and precision medicine. Currently, these language models are predominantly based on Transformer architectures. While Transformers have yielded impressive results, their quadratic runtime dependency on the sequence length complicates their use for long genomic sequences and in-context learning on proteins and chemical sequences. Recently, the recurrent xLSTM architecture has been shown to perform favorably compared to Transformers and modern state-space model (SSM) architectures in the natural language domain. Similar to SSMs, xLSTMs have a linear runtime dependency on the sequence length and allow for constant-memory decoding at inference time, which makes them prime candidates for modeling long-range dependencies in biological and chemical sequences. In this work, we tailor xLSTM towards these domains and propose a suite of architectural variants called Bio-xLSTM. Extensive experiments in three large domains, genomics, proteins, and chemistry, were performed to assess xLSTM's ability to model biological and chemical sequences. The results show that models based on Bio-xLSTM a) can serve as proficient generative models for DNA, protein, and chemical sequences, b) learn rich representations for those modalities, and c) can perform in-context learning for proteins and small molecules.