 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Recurrent Action Model: xLSTM enables Fast Inference for Robotics Tasks
Oct 29, 2024In recent years, there has been a trend in the field of Reinforcement Learning (RL) towards large action models trained offline on large-scale datasets via sequence modeling. Existing models are primarily based on the Transformer architecture, which result in powerful agents. However, due to slow inference times, Transformer-based approaches are impractical for real-time applications, such as robotics. Recently, modern recurrent architectures, such as xLSTM and Mamba, have been proposed that exhibit parallelization benefits during training similar to the Transformer architecture while offering fast inference. In this work, we study the aptitude of these modern recurrent architectures for large action models. Consequently, we propose a Large Recurrent Action Model (LRAM) with an xLSTM at its core that comes with linear-time inference complexity and natural sequence length extrapolation abilities. Experiments on 432 tasks from 6 domains show that LRAM compares favorably to Transformers in terms of performance and speed.
SITTA: A Semantic Image-Text Alignment for Image Captioning
Jul 10, 2023Textual and semantic comprehension of images is essential for generating proper captions. The comprehension requires detection of objects, modeling of relations between them, an assessment of the semantics of the scene and, finally, representing the extracted knowledge in a language space. To achieve rich language capabilities while ensuring good image-language mappings, pretrained language models (LMs) were conditioned on pretrained multi-modal (image-text) models that allow for image inputs. This requires an alignment of the image representation of the multi-modal model with the language representations of a generative LM. However, it is not clear how to best transfer semantics detected by the vision encoder of the multi-modal model to the LM. We introduce two novel ways of constructing a linear mapping that successfully transfers semantics between the embedding spaces of the two pretrained models. The first aligns the embedding space of the multi-modal language encoder with the embedding space of the pretrained LM via token correspondences. The latter leverages additional data that consists of image-text pairs to construct the mapping directly from vision to language space. Using our semantic mappings, we unlock image captioning for LMs without access to gradient information. By using different sources of data we achieve strong captioning performance on MS-COCO and Flickr30k datasets. Even in the face of limited data, our method partly exceeds the performance of other zero-shot and even finetuned competitors. Our ablation studies show that even LMs at a scale of merely 250M parameters can generate decent captions employing our semantic mappings. Our approach makes image captioning more accessible for institutions with restricted computational resources.
Semantic HELM: An Interpretable Memory for Reinforcement Learning
Jun 15, 2023Reinforcement learning agents deployed in the real world often have to cope with partially observable environments. Therefore, most agents employ memory mechanisms to approximate the state of the environment. Recently, there have been impressive success stories in mastering partially observable environments, mostly in the realm of computer games like Dota 2, StarCraft II, or MineCraft. However, none of these methods are interpretable in the sense that it is not comprehensible for humans how the agent decides which actions to take based on its inputs. Yet, human understanding is necessary in order to deploy such methods in high-stake domains like autonomous driving or medical applications. We propose a novel memory mechanism that operates on human language to illuminate the decision-making process. First, we use CLIP to associate visual inputs with language tokens. Then we feed these tokens to a pretrained language model that serves the agent as memory and provides it with a coherent and interpretable representation of the past. Our memory mechanism achieves state-of-the-art performance in environments where memorizing the past is crucial to solve tasks. Further, we present situations where our memory component excels or fails to demonstrate strengths and weaknesses of our new approach.
Few-Shot Learning by Dimensionality Reduction in Gradient Space
Jun 07, 2022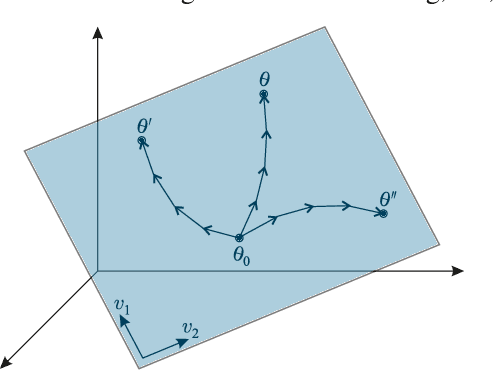
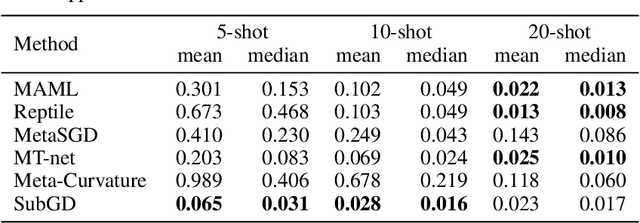
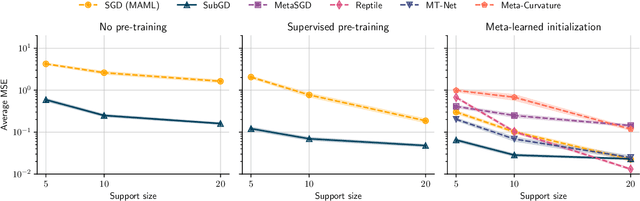
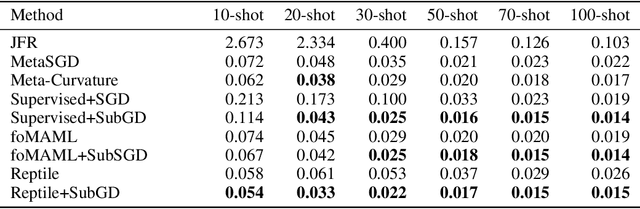
We introduce SubGD, a novel few-shot learning method which is based on the recent finding that stochastic gradient descent updates tend to live in a low-dimensional parameter subspace. In experimental and theoretical analyses, we show that models confined to a suitable predefined subspace generalize well for few-shot learning. A suitable subspace fulfills three criteria across the given tasks: it (a) allows to reduce the training error by gradient flow, (b) leads to models that generalize well, and (c) can be identified by stochastic gradient descent. SubGD identifies these subspaces from an eigendecomposition of the auto-correlation matrix of update directions across different tasks. Demonstrably, we can identify low-dimensional suitable subspaces for few-shot learning of dynamical systems, which have varying properties described by one or few parameters of the analytical system description. Such systems are ubiquitous among real-world applications in science and engineering. We experimentally corroborate the advantages of SubGD on three distinct dynamical systems problem settings, significantly outperforming popular few-shot learning methods both in terms of sample efficiency and performance.
History Compression via Language Models in Reinforcement Learning
May 24, 2022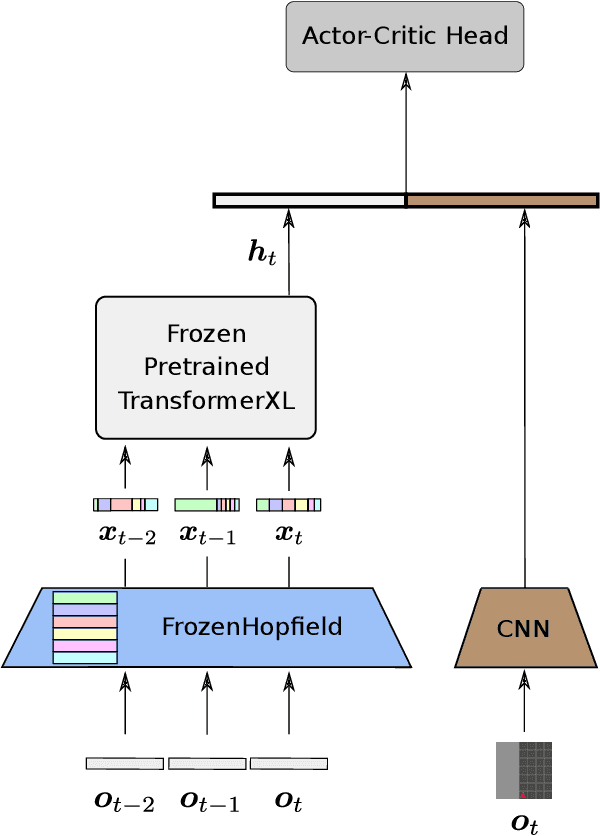

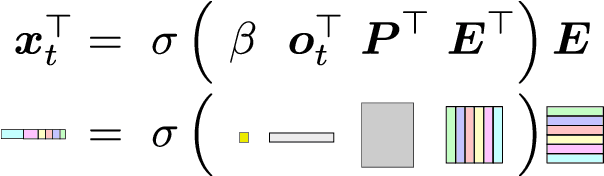

In a partially observable Markov decision process (POMDP), an agent typically uses a representation of the past to approximate the underlying MDP. We propose to utilize a frozen Pretrained Language Transformer (PLT) for history representation and compression to improve sample efficiency. To avoid training of the Transformer, we introduce FrozenHopfield, which automatically associates observations with original token embeddings. To form these associations, a modern Hopfield network stores the original token embeddings, which are retrieved by queries that are obtained by a random but fixed projection of observations. Our new method, HELM, enables actor-critic network architectures that contain a pretrained language Transformer for history representation as a memory module. Since a representation of the past need not be learned, HELM is much more sample efficient than competitors. On Minigrid and Procgen environments HELM achieves new state-of-the-art results. Our code is available at https://github.com/ml-jku/helm.
Cross-Domain Few-Shot Learning by Representation Fusion
Oct 13, 2020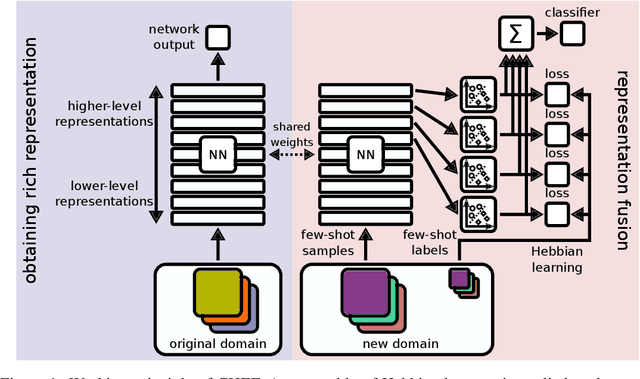

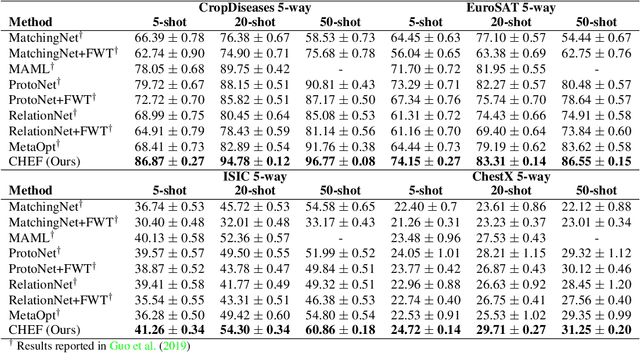
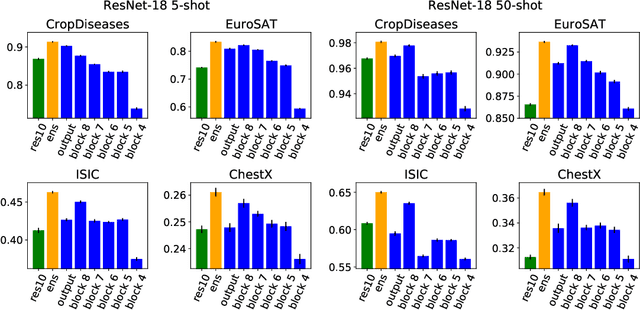
In order to quickly adapt to new data, few-shot learning aims at learning from few examples, often by using already acquired knowledge. The new data often differs from the previously seen data due to a domain shift, that is, a change of the input-target distribution. While several methods perform well on small domain shifts like new target classes with similar inputs, larger domain shifts are still challenging. Large domain shifts may result in high-level concepts that are not shared between the original and the new domain. However, low-level concepts like edges in images might still be shared and useful. For cross-domain few-shot learning, we suggest representation fusion to unify different abstraction levels of a deep neural network into one representation. We propose Cross-domain Hebbian Ensemble Few-shot learning (CHEF), which achieves representation fusion by an ensemble of Hebbian learners acting on different layers of a deep neural network that was trained on the original domain. On the few-shot datasets miniImagenet and tieredImagenet, where the domain shift is small, CHEF is competitive with state-of-the-art methods. On cross-domain few-shot benchmark challenges with larger domain shifts, CHEF establishes novel state-of-the-art results in all categories. We further apply CHEF on a real-world cross-domain application in drug discovery. We consider a domain shift from bioactive molecules to environmental chemicals and drugs with twelve associated toxicity prediction tasks. On these tasks, that are highly relevant for computational drug discovery, CHEF significantly outperforms all its competitors. Github: https://github.com/ml-jku/chef
Quantum Optical Experiments Modeled by Long Short-Term Memory
Oct 30, 2019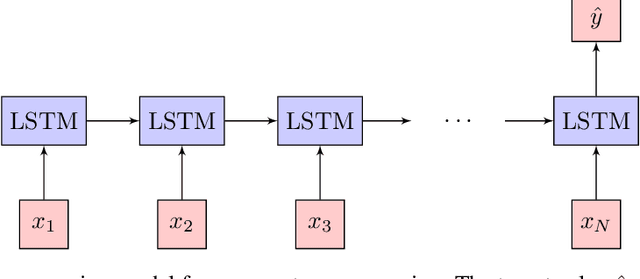

We demonstrate how machine learning is able to model experiments in quantum physics. Quantum entanglement is a cornerstone for upcoming quantum technologies such as quantum computation and quantum cryptography. Of particular interest are complex quantum states with more than two particles and a large number of entangled quantum levels. Given such a multiparticle high-dimensional quantum state, it is usually impossible to reconstruct an experimental setup that produces it. To search for interesting experiments, one thus has to randomly create millions of setups on a computer and calculate the respective output states. In this work, we show that machine learning models can provide significant improvement over random search. We demonstrate that a long short-term memory (LSTM) neural network can successfully learn to model quantum experiments by correctly predicting output state characteristics for given setups without the necessity of computing the states themselves. This approach not only allows for faster search but is also an essential step towards automated design of multiparticle high-dimensional quantum experiments using generative machine learning models.
Patch Refinement -- Localized 3D Object Detection
Oct 09, 2019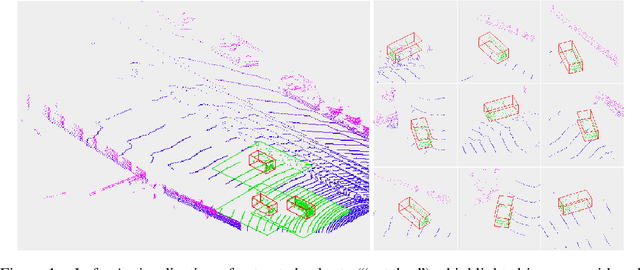
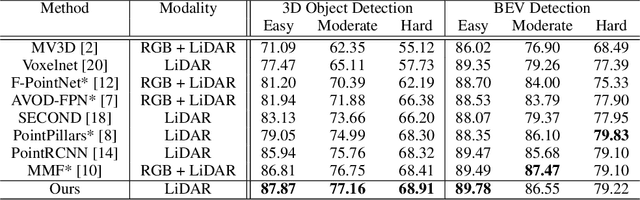
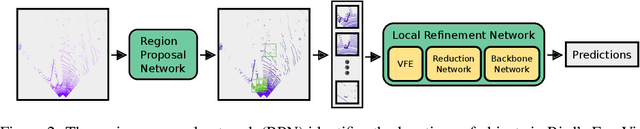
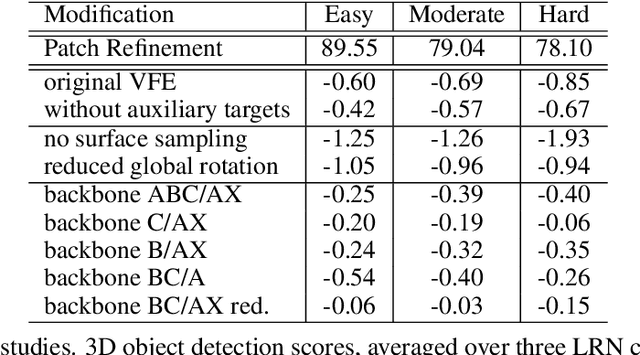
We introduce Patch Refinement a two-stage model for accurate 3D object detection and localization from point cloud data. Patch Refinement is composed of two independently trained Voxelnet-based networks, a Region Proposal Network (RPN) and a Local Refinement Network (LRN). We decompose the detection task into a preliminary Bird's Eye View (BEV) detection step and a local 3D detection step. Based on the proposed BEV locations by the RPN, we extract small point cloud subsets ("patches"), which are then processed by the LRN, which is less limited by memory constraints due to the small area of each patch. Therefore, we can apply encoding with a higher voxel resolution locally. The independence of the LRN enables the use of additional augmentation techniques and allows for an efficient, regression focused training as it uses only a small fraction of each scene. Evaluated on the KITTI 3D object detection benchmark, our submission from January 28, 2019, outperformed all previous entries on all three difficulties of the class car, using only 50 % of the available training data and only LiDAR information.