 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023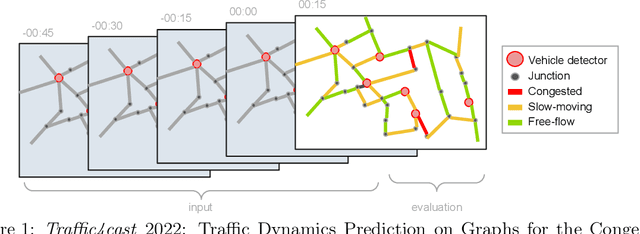
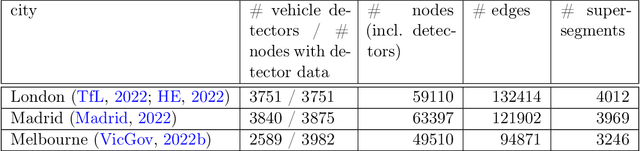
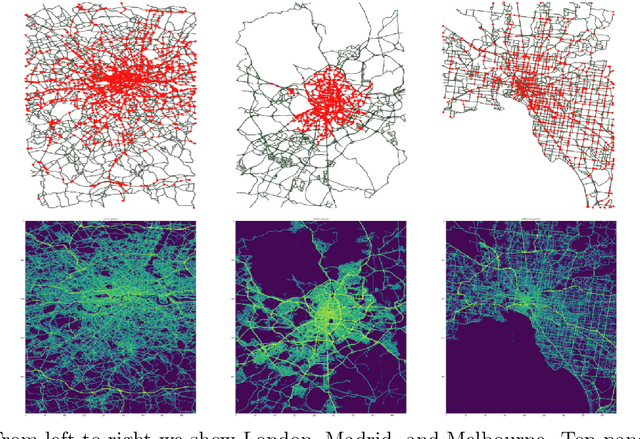
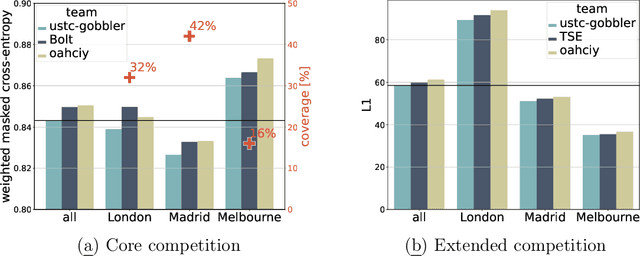
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Landslide4Sense: Reference Benchmark Data and Deep Learning Models for Landslide Detection
Jun 01, 2022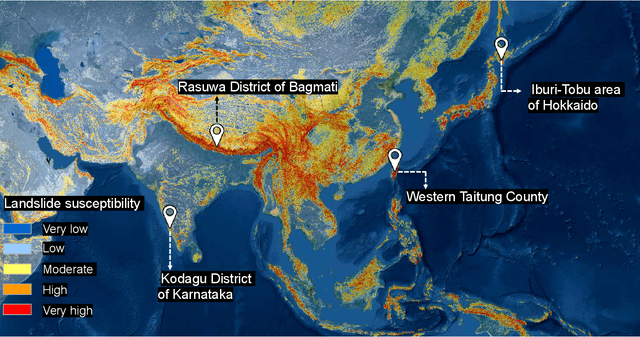
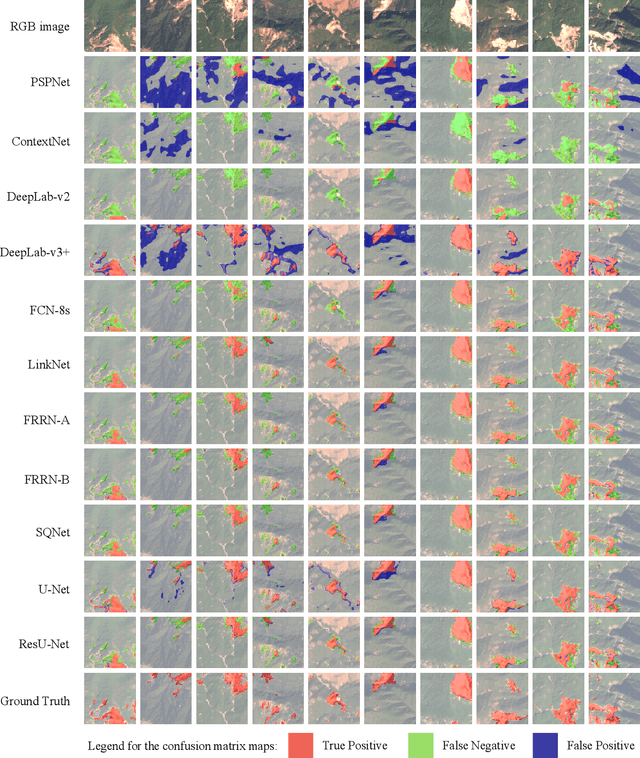
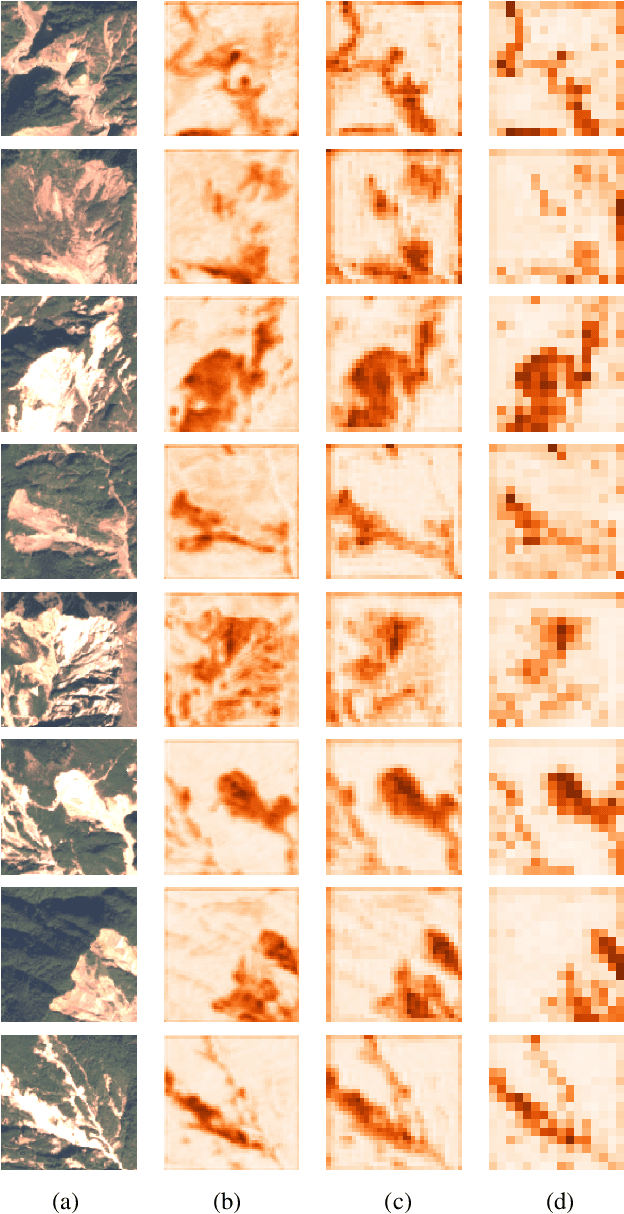
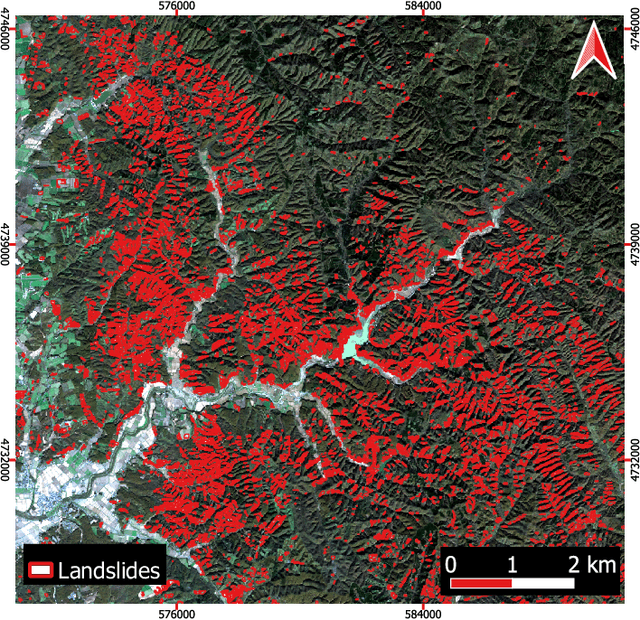
This study introduces \textit{Landslide4Sense}, a reference benchmark for landslide detection from remote sensing. The repository features 3,799 image patches fusing optical layers from Sentinel-2 sensors with the digital elevation model and slope layer derived from ALOS PALSAR. The added topographical information facilitates an accurate detection of landslide borders, which recent researches have shown to be challenging using optical data alone. The extensive data set supports deep learning (DL) studies in landslide detection and the development and validation of methods for the systematic update of landslide inventories. The benchmark data set has been collected at four different times and geographical locations: Iburi (September 2018), Kodagu (August 2018), Gorkha (April 2015), and Taiwan (August 2009). Each image pixel is labelled as belonging to a landslide or not, incorporating various sources and thorough manual annotation. We then evaluate the landslide detection performance of 11 state-of-the-art DL segmentation models: U-Net, ResU-Net, PSPNet, ContextNet, DeepLab-v2, DeepLab-v3+, FCN-8s, LinkNet, FRRN-A, FRRN-B, and SQNet. All models were trained from scratch on patches from one quarter of each study area and tested on independent patches from the other three quarters. Our experiments demonstrate that ResU-Net outperformed the other models for the landslide detection task. We make the multi-source landslide benchmark data (Landslide4Sense) and the tested DL models publicly available at \url{www.landslide4sense.org}, establishing an important resource for remote sensing, computer vision, and machine learning communities in studies of image classification in general and applications to landslide detection in particular.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022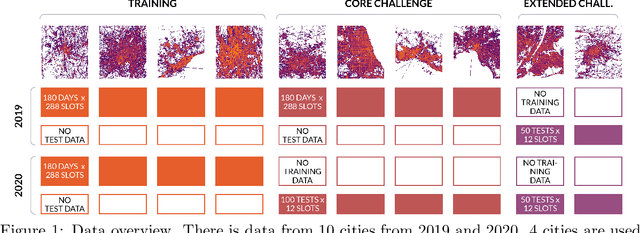
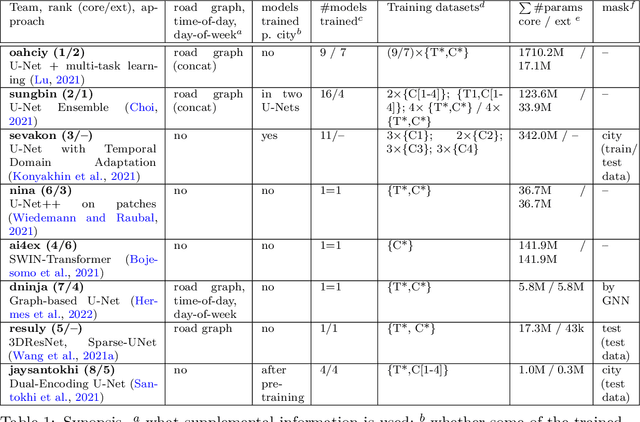
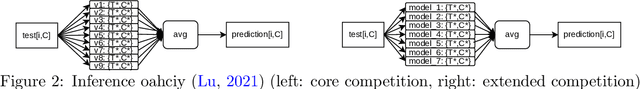
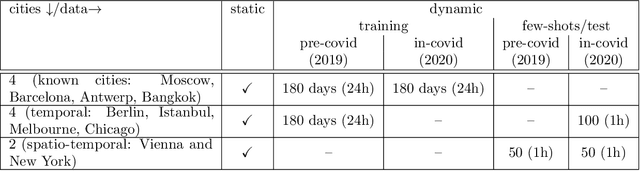
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
Oct 21, 2021
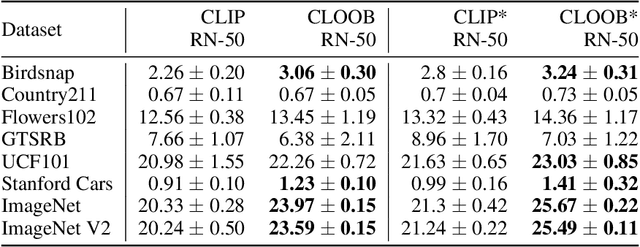
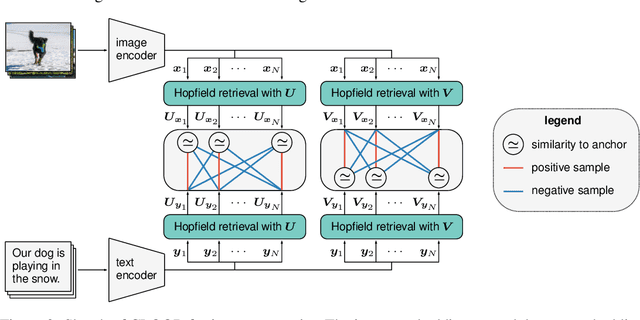
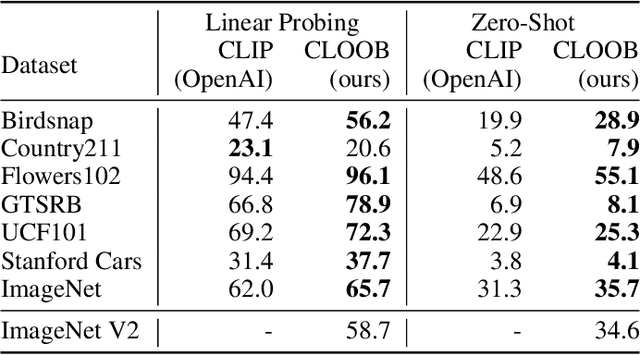
Contrastive learning with the InfoNCE objective is exceptionally successful in various self-supervised learning tasks. Recently, the CLIP model yielded impressive results on zero-shot transfer learning when using InfoNCE for learning visual representations from natural language supervision. However, InfoNCE as a lower bound on the mutual information has been shown to perform poorly for high mutual information. In contrast, the InfoLOOB upper bound (leave one out bound) works well for high mutual information but suffers from large variance and instabilities. We introduce "Contrastive Leave One Out Boost" (CLOOB), where modern Hopfield networks boost learning with the InfoLOOB objective. Modern Hopfield networks replace the original embeddings by retrieved embeddings in the InfoLOOB objective. The retrieved embeddings give InfoLOOB two assets. Firstly, the retrieved embeddings stabilize InfoLOOB, since they are less noisy and more similar to one another than the original embeddings. Secondly, they are enriched by correlations, since the covariance structure of embeddings is reinforced through retrievals. We compare CLOOB to CLIP after learning on the Conceptual Captions and the YFCC dataset with respect to their zero-shot transfer learning performance on other datasets. CLOOB consistently outperforms CLIP at zero-shot transfer learning across all considered architectures and datasets.
Cross-Domain Few-Shot Learning by Representation Fusion
Oct 13, 2020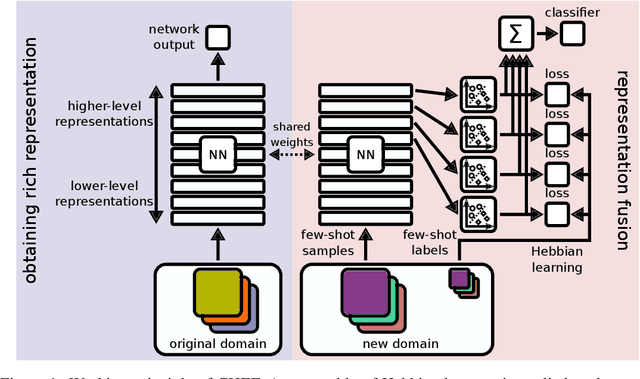

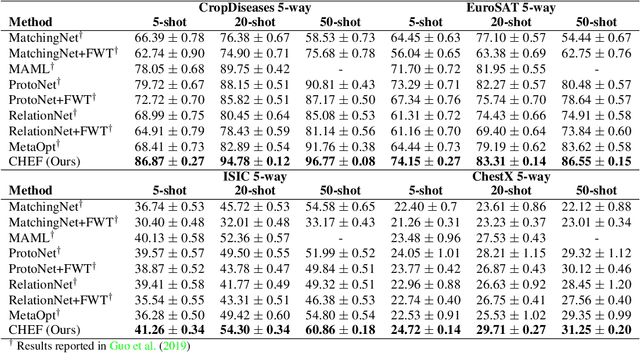
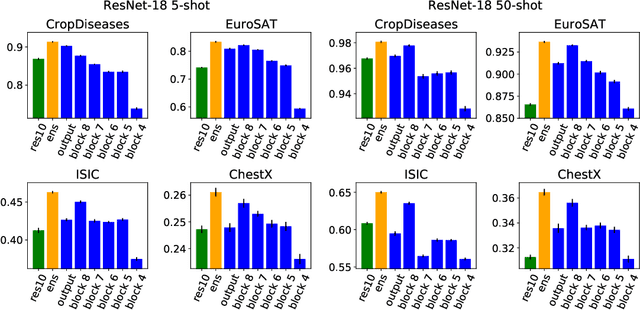
In order to quickly adapt to new data, few-shot learning aims at learning from few examples, often by using already acquired knowledge. The new data often differs from the previously seen data due to a domain shift, that is, a change of the input-target distribution. While several methods perform well on small domain shifts like new target classes with similar inputs, larger domain shifts are still challenging. Large domain shifts may result in high-level concepts that are not shared between the original and the new domain. However, low-level concepts like edges in images might still be shared and useful. For cross-domain few-shot learning, we suggest representation fusion to unify different abstraction levels of a deep neural network into one representation. We propose Cross-domain Hebbian Ensemble Few-shot learning (CHEF), which achieves representation fusion by an ensemble of Hebbian learners acting on different layers of a deep neural network that was trained on the original domain. On the few-shot datasets miniImagenet and tieredImagenet, where the domain shift is small, CHEF is competitive with state-of-the-art methods. On cross-domain few-shot benchmark challenges with larger domain shifts, CHEF establishes novel state-of-the-art results in all categories. We further apply CHEF on a real-world cross-domain application in drug discovery. We consider a domain shift from bioactive molecules to environmental chemicals and drugs with twelve associated toxicity prediction tasks. On these tasks, that are highly relevant for computational drug discovery, CHEF significantly outperforms all its competitors. Github: https://github.com/ml-jku/chef
Hopfield Networks is All You Need
Jul 16, 2020
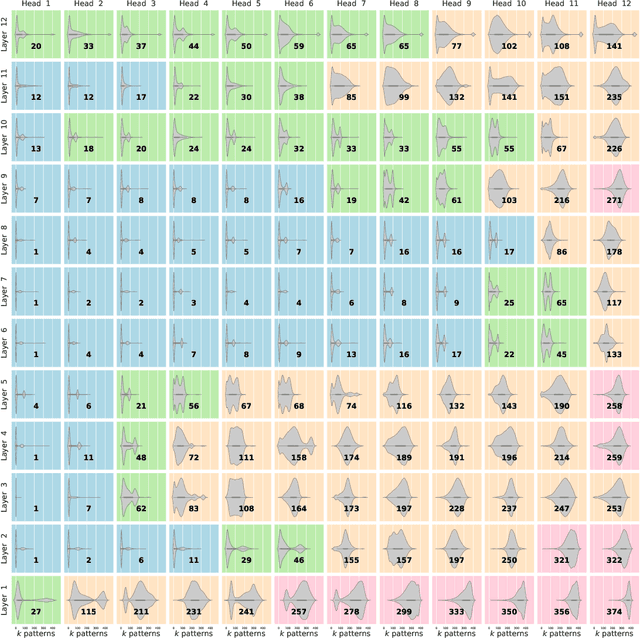
We show that the transformer attention mechanism is the update rule of a modern Hopfield network with continuous states. This new Hopfield network can store exponentially (with the dimension) many patterns, converges with one update, and has exponentially small retrieval errors. The number of stored patterns is traded off against convergence speed and retrieval error. The new Hopfield network has three types of energy minima (fixed points of the update): (1) global fixed point averaging over all patterns, (2) metastable states averaging over a subset of patterns, and (3) fixed points which store a single pattern. Transformer and BERT models operate in their first layers preferably in the global averaging regime, while they operate in higher layers in metastable states. The gradient in transformers is maximal for metastable states, is uniformly distributed for global averaging, and vanishes for a fixed point near a stored pattern. Using the Hopfield network interpretation, we analyzed learning of transformer and BERT models. Learning starts with attention heads that average and then most of them switch to metastable states. However, the majority of heads in the first layers still averages and can be replaced by averaging, e.g. our proposed Gaussian weighting. In contrast, heads in the last layers steadily learn and seem to use metastable states to collect information created in lower layers. These heads seem to be a promising target for improving transformers. Neural networks with Hopfield networks outperform other methods on immune repertoire classification, where the Hopfield net stores several hundreds of thousands of patterns. We provide a new PyTorch layer called "Hopfield", which allows to equip deep learning architectures with modern Hopfield networks as a new powerful concept comprising pooling, memory, and attention. GitHub: https://github.com/ml-jku/hopfield-layers