 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Human-Like Nature of Machine-Generated Texts: Theory and Detection Enhancement
May 22, 2026Machine-generated texts (MGTs) produced by large language models (LLMs) are increasingly prevalent across various applications, while their potential misuse in fake news propagation and phishing has raised serious concerns, highlighting the need for MGT detection. Existing paragraph-level detection methods commonly treat MGTs as entirely machine-like, overlooking the hidden human-like nature of machine-generated texts: even fully machine-generated texts may contain spans that are highly consistent with human writing. To this end, we first reveal the existence of such hidden human-like spans, and then theoretically analyze their impact on detection. Our analysis shows that these spans increase the sentence complexity for detection, thereby making MGT detection intrinsically harder. Based on this finding, we propose a model-agnostic stacked enhancement framework that improves existing detectors by reducing the influence of hidden human-like spans. Specifically, we model span-level retention decisions as a latent-variable problem and instantiate the optimization with a hard-EM-inspired procedure, where the detector iteratively filters confidently human-like subsequences and refines itself on the remaining text. Extensive experiments across various LLMs and practical scenarios demonstrate that the proposed framework consistently enhances existing detectors. Notably, the framework can also work in a training-free manner, offering flexibility and scalability for practical deployment.
Beyond Raw Detection Scores: Markov-Informed Calibration for Boosting Machine-Generated Text Detection
Feb 08, 2026While machine-generated texts (MGTs) offer great convenience, they also pose risks such as disinformation and phishing, highlighting the need for reliable detection. Metric-based methods, which extract statistically distinguishable features of MGTs, are often more practical than complex model-based methods that are prone to overfitting. Given their diverse designs, we first place representative metric-based methods within a unified framework, enabling a clear assessment of their advantages and limitations. Our analysis identifies a core challenge across these methods: the token-level detection score is easily biased by the inherent randomness of the MGTs generation process. To address this, we theoretically and empirically reveal two relationships of context detection scores that may aid calibration: Neighbor Similarity and Initial Instability. We then propose a Markov-informed score calibration strategy that models these relationships using Markov random fields, and implements it as a lightweight component via a mean-field approximation, allowing our method to be seamlessly integrated into existing detectors. Extensive experiments in various real-world scenarios, such as cross-LLM and paraphrasing attacks, demonstrate significant gains over baselines with negligible computational overhead. The code is available at https://github.com/tmlr-group/MRF_Calibration.
Learning to Substitute Components for Compositional Generalization
Feb 28, 2025Despite the rising prevalence of neural language models, recent empirical evidence suggests their deficiency in compositional generalization. One of the current de-facto solutions to this problem is compositional data augmentation, which aims to introduce additional compositional inductive bias. However, existing handcrafted augmentation strategies offer limited improvement when systematic generalization of neural language models requires multi-grained compositional bias (i.e., not limited to either lexical or structural biases alone) or when training sentences have an imbalanced difficulty distribution. To address these challenges, we first propose a novel compositional augmentation strategy called Component Substitution (CompSub), which enables multi-grained composition of substantial substructures across the entire training set. Furthermore, we introduce the Learning Component Substitution (LCS) framework. This framework empowers the learning of component substitution probabilities in CompSub in an end-to-end manner by maximizing the loss of neural language models, thereby prioritizing challenging compositions with elusive concepts and novel contexts. We extend the key ideas of CompSub and LCS to the recently emerging in-context learning scenarios of pre-trained large language models (LLMs), proposing the LCS-ICL algorithm to enhance the few-shot compositional generalization of state-of-the-art (SOTA) LLMs. Theoretically, we provide insights into why applying our algorithms to language models can improve compositional generalization performance. Empirically, our results on four standard compositional generalization benchmarks(SCAN, COGS, GeoQuery, and COGS-QL) demonstrate the superiority of CompSub, LCS, and LCS-ICL, with improvements of up to 66.5%, 10.3%, 1.4%, and 8.8%, respectively.
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Apr 25, 2024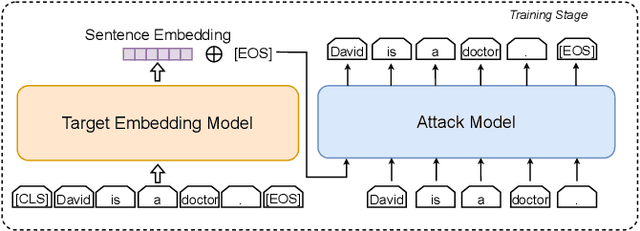
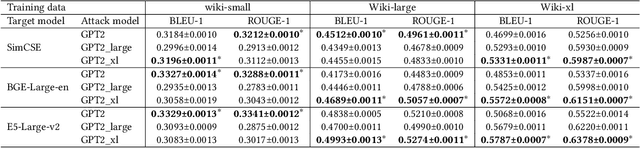

Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
Securing Recommender System via Cooperative Training
Jan 23, 2024Recommender systems are often susceptible to well-crafted fake profiles, leading to biased recommendations. Among existing defense methods, data-processing-based methods inevitably exclude normal samples, while model-based methods struggle to enjoy both generalization and robustness. To this end, we suggest integrating data processing and the robust model to propose a general framework, Triple Cooperative Defense (TCD), which employs three cooperative models that mutually enhance data and thereby improve recommendation robustness. Furthermore, Considering that existing attacks struggle to balance bi-level optimization and efficiency, we revisit poisoning attacks in recommender systems and introduce an efficient attack strategy, Co-training Attack (Co-Attack), which cooperatively optimizes the attack optimization and model training, considering the bi-level setting while maintaining attack efficiency. Moreover, we reveal a potential reason for the insufficient threat of existing attacks is their default assumption of optimizing attacks in undefended scenarios. This overly optimistic setting limits the potential of attacks. Consequently, we put forth a Game-based Co-training Attack (GCoAttack), which frames the proposed CoAttack and TCD as a game-theoretic process, thoroughly exploring CoAttack's attack potential in the cooperative training of attack and defense. Extensive experiments on three real datasets demonstrate TCD's superiority in enhancing model robustness. Additionally, we verify that the two proposed attack strategies significantly outperform existing attacks, with game-based GCoAttack posing a greater poisoning threat than CoAttack.
Model Stealing Attack against Graph Classification with Authenticity, Uncertainty and Diversity
Dec 26, 2023Recent research demonstrates that GNNs are vulnerable to the model stealing attack, a nefarious endeavor geared towards duplicating the target model via query permissions. However, they mainly focus on node classification tasks, neglecting the potential threats entailed within the domain of graph classification tasks. Furthermore, their practicality is questionable due to unreasonable assumptions, specifically concerning the large data requirements and extensive model knowledge. To this end, we advocate following strict settings with limited real data and hard-label awareness to generate synthetic data, thereby facilitating the stealing of the target model. Specifically, following important data generation principles, we introduce three model stealing attacks to adapt to different actual scenarios: MSA-AU is inspired by active learning and emphasizes the uncertainty to enhance query value of generated samples; MSA-AD introduces diversity based on Mixup augmentation strategy to alleviate the query inefficiency issue caused by over-similar samples generated by MSA-AU; MSA-AUD combines the above two strategies to seamlessly integrate the authenticity, uncertainty, and diversity of the generated samples. Finally, extensive experiments consistently demonstrate the superiority of the proposed methods in terms of concealment, query efficiency, and stealing performance.
Model Stealing Attack against Recommender System
Dec 26, 2023Recent studies have demonstrated the vulnerability of recommender systems to data privacy attacks. However, research on the threat to model privacy in recommender systems, such as model stealing attacks, is still in its infancy. Some adversarial attacks have achieved model stealing attacks against recommender systems, to some extent, by collecting abundant training data of the target model (target data) or making a mass of queries. In this paper, we constrain the volume of available target data and queries and utilize auxiliary data, which shares the item set with the target data, to promote model stealing attacks. Although the target model treats target and auxiliary data differently, their similar behavior patterns allow them to be fused using an attention mechanism to assist attacks. Besides, we design stealing functions to effectively extract the recommendation list obtained by querying the target model. Experimental results show that the proposed methods are applicable to most recommender systems and various scenarios and exhibit excellent attack performance on multiple datasets.
Toward Robust Recommendation via Real-time Vicinal Defense
Sep 29, 2023Recommender systems have been shown to be vulnerable to poisoning attacks, where malicious data is injected into the dataset to cause the recommender system to provide biased recommendations. To defend against such attacks, various robust learning methods have been proposed. However, most methods are model-specific or attack-specific, making them lack generality, while other methods, such as adversarial training, are oriented towards evasion attacks and thus have a weak defense strength in poisoning attacks. In this paper, we propose a general method, Real-time Vicinal Defense (RVD), which leverages neighboring training data to fine-tune the model before making a recommendation for each user. RVD works in the inference phase to ensure the robustness of the specific sample in real-time, so there is no need to change the model structure and training process, making it more practical. Extensive experimental results demonstrate that RVD effectively mitigates targeted poisoning attacks across various models without sacrificing accuracy. Moreover, the defensive effect can be further amplified when our method is combined with other strategies.
When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities
Jul 31, 2023The advent of large language models marks a revolutionary breakthrough in artificial intelligence. With the unprecedented scale of training and model parameters, the capability of large language models has been dramatically improved, leading to human-like performances in understanding, language synthesizing, and common-sense reasoning, etc. Such a major leap-forward in general AI capacity will change the pattern of how personalization is conducted. For one thing, it will reform the way of interaction between humans and personalization systems. Instead of being a passive medium of information filtering, large language models present the foundation for active user engagement. On top of such a new foundation, user requests can be proactively explored, and user's required information can be delivered in a natural and explainable way. For another thing, it will also considerably expand the scope of personalization, making it grow from the sole function of collecting personalized information to the compound function of providing personalized services. By leveraging large language models as general-purpose interface, the personalization systems may compile user requests into plans, calls the functions of external tools to execute the plans, and integrate the tools' outputs to complete the end-to-end personalization tasks. Today, large language models are still being developed, whereas the application in personalization is largely unexplored. Therefore, we consider it to be the right time to review the challenges in personalization and the opportunities to address them with LLMs. In particular, we dedicate this perspective paper to the discussion of the following aspects: the development and challenges for the existing personalization system, the newly emerged capabilities of large language models, and the potential ways of making use of large language models for personalization.
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023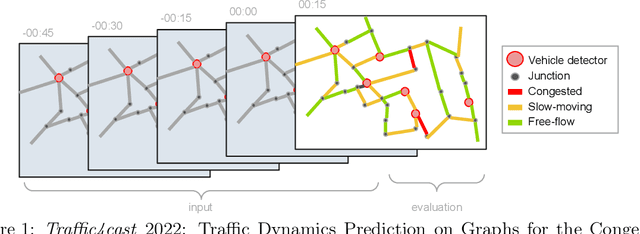
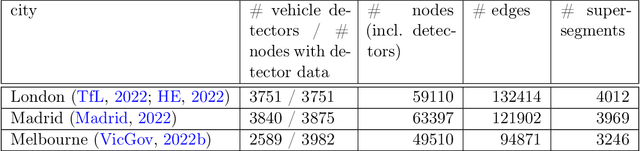
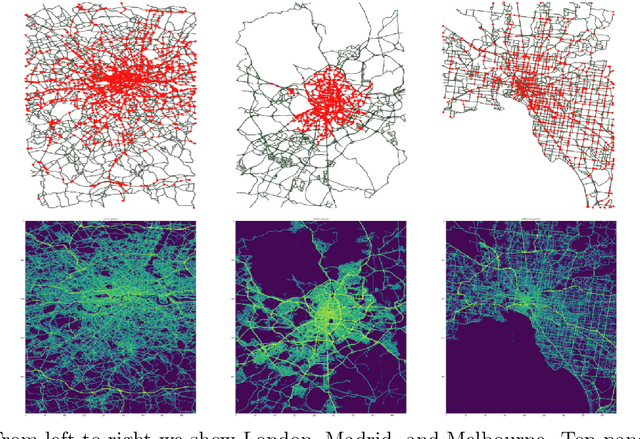
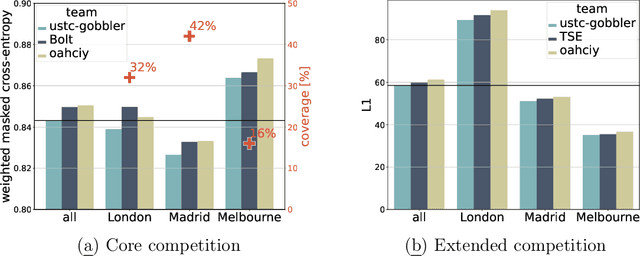
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.