 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Softmax Loss All You Need? A Principled Analysis of Softmax-family Loss
Jan 30, 2026The Softmax loss is one of the most widely employed surrogate objectives for classification and ranking tasks. To elucidate its theoretical properties, the Fenchel-Young framework situates it as a canonical instance within a broad family of surrogates. Concurrently, another line of research has addressed scalability when the number of classes is exceedingly large, in which numerous approximations have been proposed to retain the benefits of the exact objective while improving efficiency. Building on these two perspectives, we present a principled investigation of the Softmax-family losses. We examine whether different surrogates achieve consistency with classification and ranking metrics, and analyze their gradient dynamics to reveal distinct convergence behaviors. We also introduce a systematic bias-variance decomposition for approximate methods that provides convergence guarantees, and further derive a per-epoch complexity analysis, showing explicit trade-offs between effectiveness and efficiency. Extensive experiments on a representative task demonstrate a strong alignment between consistency, convergence, and empirical performance. Together, these results establish a principled foundation and offer practical guidance for loss selections in large-class machine learning applications.
NDCG-Consistent Softmax Approximation with Accelerated Convergence
Jun 11, 2025
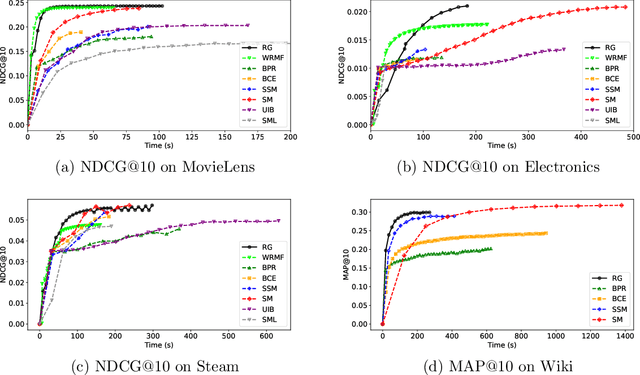

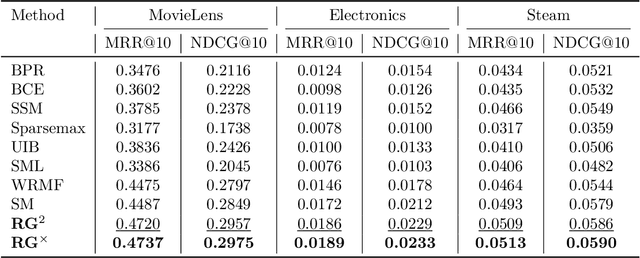
Ranking tasks constitute fundamental components of extreme similarity learning frameworks, where extremely large corpora of objects are modeled through relative similarity relationships adhering to predefined ordinal structures. Among various ranking surrogates, Softmax (SM) Loss has been widely adopted due to its natural capability to handle listwise ranking via global negative comparisons, along with its flexibility across diverse application scenarios. However, despite its effectiveness, SM Loss often suffers from significant computational overhead and scalability limitations when applied to large-scale object spaces. To address this challenge, we propose novel loss formulations that align directly with ranking metrics: the Ranking-Generalizable \textbf{squared} (RG$^2$) Loss and the Ranking-Generalizable interactive (RG$^\times$) Loss, both derived through Taylor expansions of the SM Loss. Notably, RG$^2$ reveals the intrinsic mechanisms underlying weighted squared losses (WSL) in ranking methods and uncovers fundamental connections between sampling-based and non-sampling-based loss paradigms. Furthermore, we integrate the proposed RG losses with the highly efficient Alternating Least Squares (ALS) optimization method, providing both generalization guarantees and convergence rate analyses. Empirical evaluations on real-world datasets demonstrate that our approach achieves comparable or superior ranking performance relative to SM Loss, while significantly accelerating convergence. This framework offers the similarity learning community both theoretical insights and practically efficient tools, with methodologies applicable to a broad range of tasks where balancing ranking quality and computational efficiency is essential.
Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction
Aug 29, 2024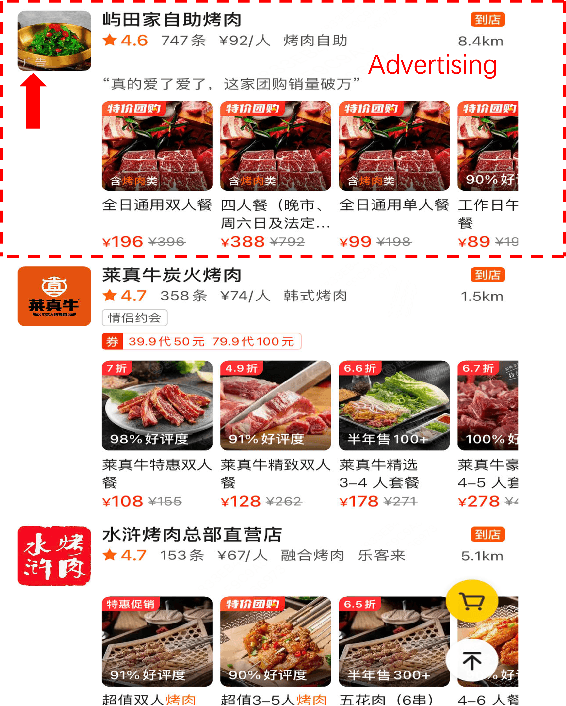
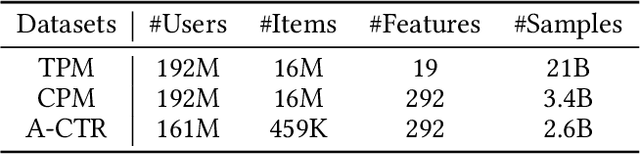
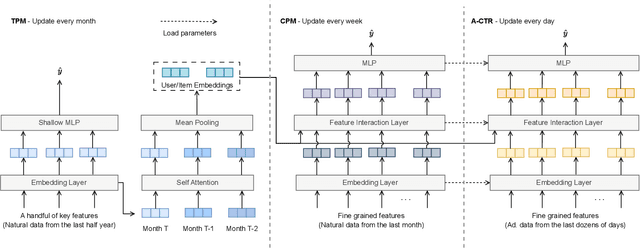
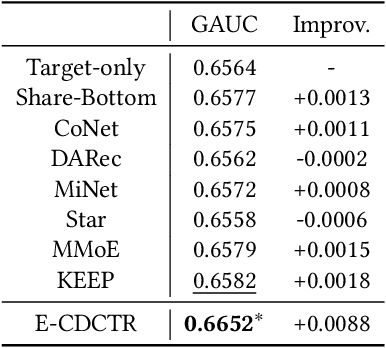
Natural content and advertisement coexist in industrial recommendation systems but differ in data distribution. Concretely, traffic related to the advertisement is considerably sparser compared to that of natural content, which motivates the development of transferring knowledge from the richer source natural content domain to the sparser advertising domain. The challenges include the inefficiencies arising from the management of extensive source data and the problem of 'catastrophic forgetting' that results from the CTR model's daily updating. To this end, we propose a novel tri-level asynchronous framework, i.e., Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction (E-CDCTR), to transfer comprehensive knowledge of natural content to advertisement CTR models. This framework consists of three key components: Tiny Pre-training Model ((TPM), which trains a tiny CTR model with several basic features on long-term natural data; Complete Pre-training Model (CPM), which trains a CTR model holding network structure and input features the same as target advertisement on short-term natural data; Advertisement CTR model (A-CTR), which derives its parameter initialization from CPM together with multiple historical embeddings from TPM as extra feature and then fine-tunes on advertisement data. TPM provides richer representations of user and item for both the CPM and A-CTR, effectively alleviating the forgetting problem inherent in the daily updates. CPM further enhances the advertisement model by providing knowledgeable initialization, thereby alleviating the data sparsity challenges typically encountered by advertising CTR models. Such a tri-level cross-domain transfer learning framework offers an efficient solution to address both data sparsity and `catastrophic forgetting', yielding remarkable improvements.
Invariant Representation Learning via Decoupling Style and Spurious Features
Dec 11, 2023



This paper considers the out-of-distribution (OOD) generalization problem under the setting that both style distribution shift and spurious features exist and domain labels are missing. This setting frequently arises in real-world applications and is underlooked because previous approaches mainly handle either of these two factors. The critical challenge is decoupling style and spurious features in the absence of domain labels. To address this challenge, we first propose a structural causal model (SCM) for the image generation process, which captures both style distribution shift and spurious features. The proposed SCM enables us to design a new framework called IRSS, which can gradually separate style distribution and spurious features from images by introducing adversarial neural networks and multi-environment optimization, thus achieving OOD generalization. Moreover, it does not require additional supervision (e.g., domain labels) other than the images and their corresponding labels. Experiments on benchmark datasets demonstrate that IRSS outperforms traditional OOD methods and solves the problem of Invariant risk minimization (IRM) degradation, enabling the extraction of invariant features under distribution shift.
When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities
Jul 31, 2023The advent of large language models marks a revolutionary breakthrough in artificial intelligence. With the unprecedented scale of training and model parameters, the capability of large language models has been dramatically improved, leading to human-like performances in understanding, language synthesizing, and common-sense reasoning, etc. Such a major leap-forward in general AI capacity will change the pattern of how personalization is conducted. For one thing, it will reform the way of interaction between humans and personalization systems. Instead of being a passive medium of information filtering, large language models present the foundation for active user engagement. On top of such a new foundation, user requests can be proactively explored, and user's required information can be delivered in a natural and explainable way. For another thing, it will also considerably expand the scope of personalization, making it grow from the sole function of collecting personalized information to the compound function of providing personalized services. By leveraging large language models as general-purpose interface, the personalization systems may compile user requests into plans, calls the functions of external tools to execute the plans, and integrate the tools' outputs to complete the end-to-end personalization tasks. Today, large language models are still being developed, whereas the application in personalization is largely unexplored. Therefore, we consider it to be the right time to review the challenges in personalization and the opportunities to address them with LLMs. In particular, we dedicate this perspective paper to the discussion of the following aspects: the development and challenges for the existing personalization system, the newly emerged capabilities of large language models, and the potential ways of making use of large language models for personalization.