 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
Jun 02, 2026Reward models (RMs) provide critical feedback signals for LLM post-training, notably in reinforced fine-tuning (RFT) and reinforcement learning (RL) pipelines. However, current reward evaluation relies on heterogeneous criteria such as rule-based verifiers, ground-truth references, procedural checklists, and complex rubrics, where a unified mechanism to integrate all types of evidence remains unexplored. To this end, we propose Skill Reward Model (Skill-RM), a unified framework that reformulates reward modeling as the execution of a reusable Reward-Evaluation Skill. By treating reward computation as a structured agentic task, Skill-RM provides a consistent interface to orchestrate heterogeneous resources, dynamically selecting and aggregating evidence tailored to the specific requirements of each input. This approach enables the reward model to move beyond static evaluation, ensuring consistency and transparency across diverse tasks. Extensive experiments on reward benchmarks and downstream applications, including best-of-N selection and reinforcement learning, demonstrate that Skill-RM consistently outperforms traditional judge baselines. Our findings suggest that Skill-RM not only provides a unified solution for reward modeling but also achieves superior performance through the strategic and dynamic orchestration of evidence. The code is at https://github.com/Qwen-Applications/Skill-RM.
On the Role of Reasoning Patterns in the Generalization Discrepancy of Long Chain-of-Thought Supervised Fine-Tuning
Apr 02, 2026Supervised Fine-Tuning (SFT) on long Chain-of-Thought (CoT) trajectories has become a pivotal phase in building large reasoning models. However, how CoT trajectories from different sources influence the generalization performance of models remains an open question. In this paper, we conduct a comparative study using two sources of verified CoT trajectories generated by two competing models, \texttt{DeepSeek-R1-0528} and \texttt{gpt-oss-120b}, with their problem sets controlled to be identical. Despite their comparable performance, we uncover a striking paradox: lower training loss does not translate to better generalization. SFT on \texttt{DeepSeek-R1-0528} data achieves remarkably lower training loss, yet exhibits significantly worse generalization performance on reasoning benchmarks compared to those trained on \texttt{gpt-oss-120b}. To understand this paradox, we perform a multi-faceted analysis probing token-level SFT loss and step-level reasoning behaviors. Our analysis reveals a difference in reasoning patterns. \texttt{gpt-oss-120b} exhibits highly convergent and deductive trajectories, whereas \texttt{DeepSeek-R1-0528} favors a divergent and branch-heavy exploration pattern. Consequently, models trained with \texttt{DeepSeek-R1} data inherit inefficient exploration behaviors, often getting trapped in redundant exploratory branches that hinder them from reaching correct solutions. Building upon this insight, we propose a simple yet effective remedy of filtering out frequently branching trajectories to improve the generalization of SFT. Experiments show that training on selected \texttt{DeepSeek-R1-0528} subsets surprisingly improves reasoning performance by up to 5.1% on AIME25, 5.5% on BeyondAIME, and on average 3.6% on five benchmarks.
Scaling Reasoning Hop Exposes Weaknesses: Demystifying and Improving Hop Generalization in Large Language Models
Jan 29, 2026Chain-of-thought (CoT) reasoning has become the standard paradigm for enabling Large Language Models (LLMs) to solve complex problems. However, recent studies reveal a sharp performance drop in reasoning hop generalization scenarios, where the required number of reasoning steps exceeds training distributions while the underlying algorithm remains unchanged. The internal mechanisms driving this failure remain poorly understood. In this work, we conduct a systematic study on tasks from multiple domains, and find that errors concentrate at token positions of a few critical error types, rather than being uniformly distributed. Closer inspection reveals that these token-level erroneous predictions stem from internal competition mechanisms: certain attention heads, termed erroneous processing heads (ep heads), tip the balance by amplifying incorrect reasoning trajectories while suppressing correct ones. Notably, removing individual ep heads during inference can often restore the correct predictions. Motivated by these insights, we propose test-time correction of reasoning, a lightweight intervention method that dynamically identifies and deactivates ep heads in the reasoning process. Extensive experiments across different tasks and LLMs show that it consistently improves reasoning hop generalization, highlighting both its effectiveness and potential.
Klear-AgentForge: Forging Agentic Intelligence through Posttraining Scaling
Nov 08, 2025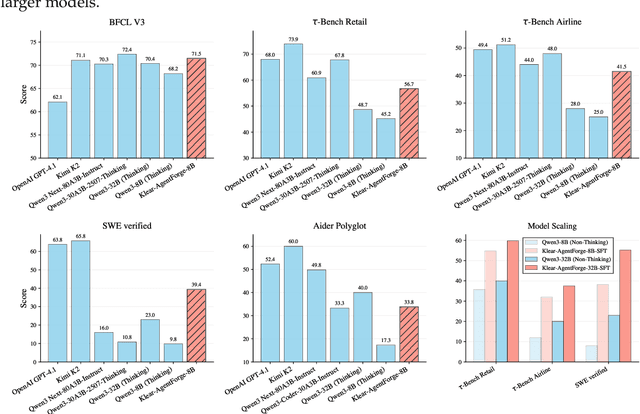
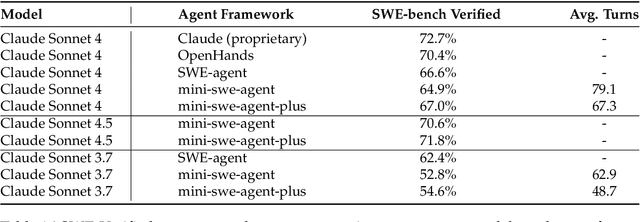
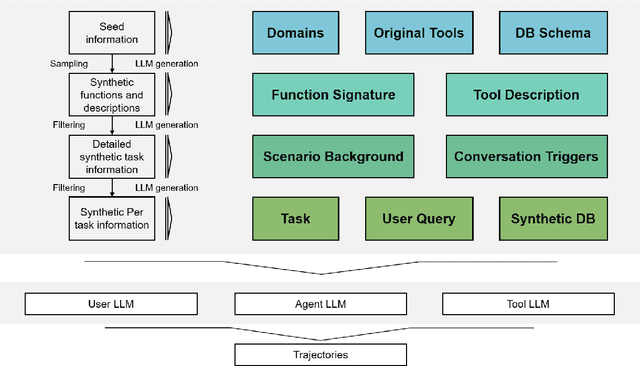
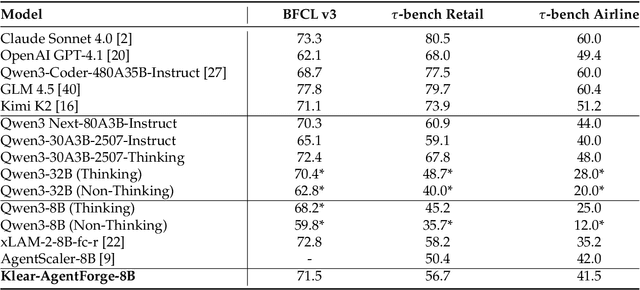
Despite the proliferation of powerful agentic models, the lack of critical post-training details hinders the development of strong counterparts in the open-source community. In this study, we present a comprehensive and fully open-source pipeline for training a high-performance agentic model for interacting with external tools and environments, named Klear-Qwen3-AgentForge, starting from the Qwen3-8B base model. We design effective supervised fine-tuning (SFT) with synthetic data followed by multi-turn reinforcement learning (RL) to unlock the potential for multiple diverse agentic tasks. We perform exclusive experiments on various agentic benchmarks in both tool use and coding domains. Klear-Qwen3-AgentForge-8B achieves state-of-the-art performance among LLMs of similar size and remains competitive with significantly larger models.
What Makes a Good Reasoning Chain? Uncovering Structural Patterns in Long Chain-of-Thought Reasoning
May 28, 2025



Recent advances in reasoning with large language models (LLMs) have popularized Long Chain-of-Thought (LCoT), a strategy that encourages deliberate and step-by-step reasoning before producing a final answer. While LCoTs have enabled expert-level performance in complex tasks, how the internal structures of their reasoning chains drive, or even predict, the correctness of final answers remains a critical yet underexplored question. In this work, we present LCoT2Tree, an automated framework that converts sequential LCoTs into hierarchical tree structures and thus enables deeper structural analysis of LLM reasoning. Using graph neural networks (GNNs), we reveal that structural patterns extracted by LCoT2Tree, including exploration, backtracking, and verification, serve as stronger predictors of final performance across a wide range of tasks and models. Leveraging an explainability technique, we further identify critical thought patterns such as over-branching that account for failures. Beyond diagnostic insights, the structural patterns by LCoT2Tree support practical applications, including improving Best-of-N decoding effectiveness. Overall, our results underscore the critical role of internal structures of reasoning chains, positioning LCoT2Tree as a powerful tool for diagnosing, interpreting, and improving reasoning in LLMs.
Learning to Substitute Components for Compositional Generalization
Feb 28, 2025Despite the rising prevalence of neural language models, recent empirical evidence suggests their deficiency in compositional generalization. One of the current de-facto solutions to this problem is compositional data augmentation, which aims to introduce additional compositional inductive bias. However, existing handcrafted augmentation strategies offer limited improvement when systematic generalization of neural language models requires multi-grained compositional bias (i.e., not limited to either lexical or structural biases alone) or when training sentences have an imbalanced difficulty distribution. To address these challenges, we first propose a novel compositional augmentation strategy called Component Substitution (CompSub), which enables multi-grained composition of substantial substructures across the entire training set. Furthermore, we introduce the Learning Component Substitution (LCS) framework. This framework empowers the learning of component substitution probabilities in CompSub in an end-to-end manner by maximizing the loss of neural language models, thereby prioritizing challenging compositions with elusive concepts and novel contexts. We extend the key ideas of CompSub and LCS to the recently emerging in-context learning scenarios of pre-trained large language models (LLMs), proposing the LCS-ICL algorithm to enhance the few-shot compositional generalization of state-of-the-art (SOTA) LLMs. Theoretically, we provide insights into why applying our algorithms to language models can improve compositional generalization performance. Empirically, our results on four standard compositional generalization benchmarks(SCAN, COGS, GeoQuery, and COGS-QL) demonstrate the superiority of CompSub, LCS, and LCS-ICL, with improvements of up to 66.5%, 10.3%, 1.4%, and 8.8%, respectively.
General Time-series Model for Universal Knowledge Representation of Multivariate Time-Series data
Feb 05, 2025



Universal knowledge representation is a central problem for multivariate time series(MTS) foundation models and yet remains open. This paper investigates this problem from the first principle and it makes four folds of contributions. First, a new empirical finding is revealed: time series with different time granularities (or corresponding frequency resolutions) exhibit distinct joint distributions in the frequency domain. This implies a crucial aspect of learning universal knowledge, one that has been overlooked by previous studies. Second, a novel Fourier knowledge attention mechanism is proposed to enable learning time granularity-aware representations from both the temporal and frequency domains. Third, an autoregressive blank infilling pre-training framework is incorporated to time series analysis for the first time, leading to a generative tasks agnostic pre-training strategy. To this end, we develop the General Time-series Model (GTM), a unified MTS foundation model that addresses the limitation of contemporary time series models, which often require token, pre-training, or model-level customizations for downstream tasks adaption. Fourth, extensive experiments show that GTM outperforms state-of-the-art (SOTA) methods across all generative tasks, including long-term forecasting, anomaly detection, and imputation.
Interpretable Catastrophic Forgetting of Large Language Model Fine-tuning via Instruction Vector
Jun 18, 2024



Fine-tuning large language models (LLMs) can cause them to lose their general capabilities. However, the intrinsic mechanisms behind such forgetting remain unexplored. In this paper, we begin by examining this phenomenon by focusing on knowledge understanding and instruction following, with the latter identified as the main contributor to forgetting during fine-tuning. Consequently, we propose the Instruction Vector (IV) framework to capture model representations highly related to specific instruction-following capabilities, thereby making it possible to understand model-intrinsic forgetting. Through the analysis of IV dynamics pre and post-training, we suggest that fine-tuning mostly adds specialized reasoning patterns instead of erasing previous skills, which may appear as forgetting. Building on this insight, we develop IV-guided training, which aims to preserve original computation graph, thereby mitigating catastrophic forgetting. Empirical tests on three benchmarks confirm the efficacy of this new approach, supporting the relationship between IVs and forgetting. Our code will be made available soon.
Mitigate Negative Transfer with Similarity Heuristic Lifelong Prompt Tuning
Jun 18, 2024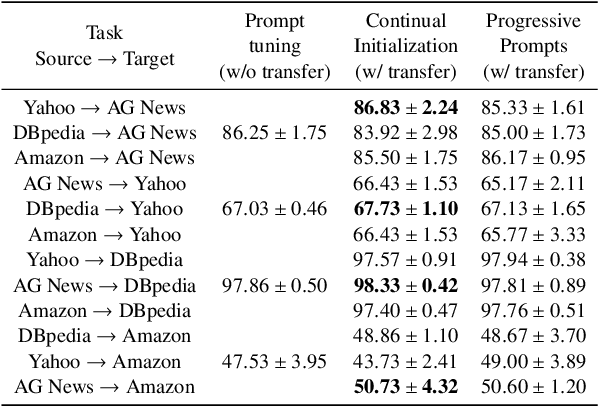
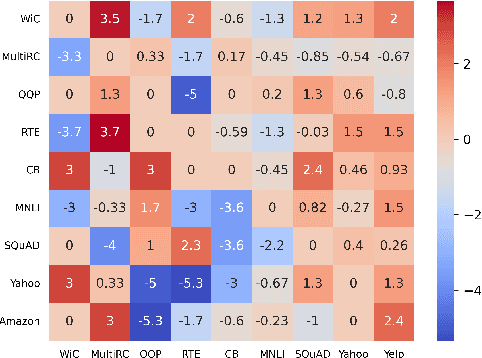

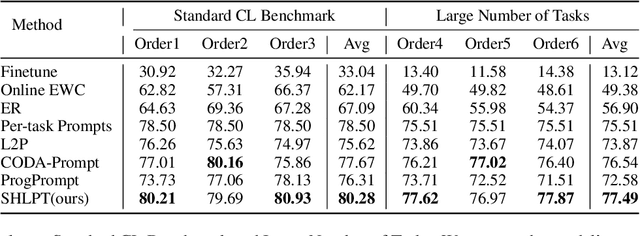
Lifelong prompt tuning has significantly advanced parameter-efficient lifelong learning with its efficiency and minimal storage demands on various tasks. Our empirical studies, however, highlights certain transferability constraints in the current methodologies: a universal algorithm that guarantees consistent positive transfer across all tasks is currently unattainable, especially when dealing dissimilar tasks that may engender negative transfer. Identifying the misalignment between algorithm selection and task specificity as the primary cause of negative transfer, we present the Similarity Heuristic Lifelong Prompt Tuning (SHLPT) framework. This innovative strategy partitions tasks into two distinct subsets by harnessing a learnable similarity metric, thereby facilitating fruitful transfer from tasks regardless of their similarity or dissimilarity. Additionally, SHLPT incorporates a parameter pool to combat catastrophic forgetting effectively. Our experiments shows that SHLPT outperforms state-of-the-art techniques in lifelong learning benchmarks and demonstrates robustness against negative transfer in diverse task sequences.
Understanding and Patching Compositional Reasoning in LLMs
Feb 22, 2024



LLMs have marked a revolutonary shift, yet they falter when faced with compositional reasoning tasks. Our research embarks on a quest to uncover the root causes of compositional reasoning failures of LLMs, uncovering that most of them stem from the improperly generated or leveraged implicit reasoning results. Inspired by our empirical findings, we resort to Logit Lens and an intervention experiment to dissect the inner hidden states of LLMs. This deep dive reveals that implicit reasoning results indeed surface within middle layers and play a causative role in shaping the final explicit reasoning results. Our exploration further locates multi-head self-attention (MHSA) modules within these layers, which emerge as the linchpins in accurate generation and leveraing of implicit reasoning results. Grounded on the above findings, we develop CREME, a lightweight method to patch errors in compositional reasoning via editing the located MHSA modules. Our empirical evidence stands testament to CREME's effectiveness, paving the way for autonomously and continuously enhancing compositional reasoning capabilities in language models.