 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting
May 23, 2024



Time series forecasting is widely used in extensive applications, such as traffic planning and weather forecasting. However, real-world time series usually present intricate temporal variations, making forecasting extremely challenging. Going beyond the mainstream paradigms of plain decomposition and multiperiodicity analysis, we analyze temporal variations in a novel view of multiscale-mixing, which is based on an intuitive but important observation that time series present distinct patterns in different sampling scales. The microscopic and the macroscopic information are reflected in fine and coarse scales respectively, and thereby complex variations can be inherently disentangled. Based on this observation, we propose TimeMixer as a fully MLP-based architecture with Past-Decomposable-Mixing (PDM) and Future-Multipredictor-Mixing (FMM) blocks to take full advantage of disentangled multiscale series in both past extraction and future prediction phases. Concretely, PDM applies the decomposition to multiscale series and further mixes the decomposed seasonal and trend components in fine-to-coarse and coarse-to-fine directions separately, which successively aggregates the microscopic seasonal and macroscopic trend information. FMM further ensembles multiple predictors to utilize complementary forecasting capabilities in multiscale observations. Consequently, TimeMixer is able to achieve consistent state-of-the-art performances in both long-term and short-term forecasting tasks with favorable run-time efficiency.
Towards Anytime Fine-tuning: Continually Pre-trained Language Models with Hypernetwork Prompt
Oct 19, 2023


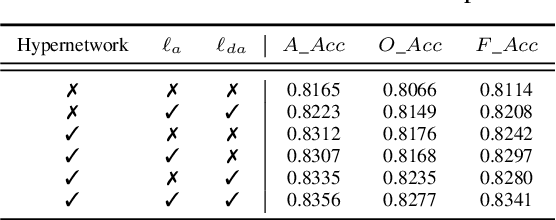
Continual pre-training has been urgent for adapting a pre-trained model to a multitude of domains and tasks in the fast-evolving world. In practice, a continually pre-trained model is expected to demonstrate not only greater capacity when fine-tuned on pre-trained domains but also a non-decreasing performance on unseen ones. In this work, we first investigate such anytime fine-tuning effectiveness of existing continual pre-training approaches, concluding with unanimously decreased performance on unseen domains. To this end, we propose a prompt-guided continual pre-training method, where we train a hypernetwork to generate domain-specific prompts by both agreement and disagreement losses. The agreement loss maximally preserves the generalization of a pre-trained model to new domains, and the disagreement one guards the exclusiveness of the generated hidden states for each domain. Remarkably, prompts by the hypernetwork alleviate the domain identity when fine-tuning and promote knowledge transfer across domains. Our method achieved improvements of 3.57% and 3.4% on two real-world datasets (including domain shift and temporal shift), respectively, demonstrating its efficacy.
Prompt-augmented Temporal Point Process for Streaming Event Sequence
Oct 13, 2023


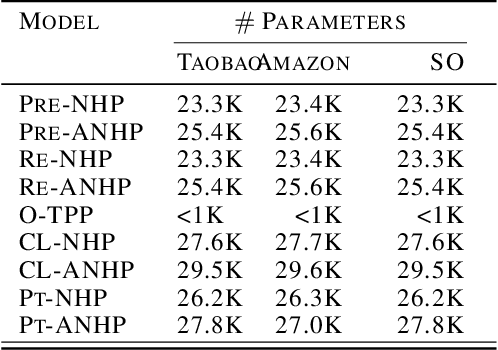
Neural Temporal Point Processes (TPPs) are the prevalent paradigm for modeling continuous-time event sequences, such as user activities on the web and financial transactions. In real-world applications, event data is typically received in a \emph{streaming} manner, where the distribution of patterns may shift over time. Additionally, \emph{privacy and memory constraints} are commonly observed in practical scenarios, further compounding the challenges. Therefore, the continuous monitoring of a TPP to learn the streaming event sequence is an important yet under-explored problem. Our work paper addresses this challenge by adopting Continual Learning (CL), which makes the model capable of continuously learning a sequence of tasks without catastrophic forgetting under realistic constraints. Correspondingly, we propose a simple yet effective framework, PromptTPP\footnote{Our code is available at {\small \url{ https://github.com/yanyanSann/PromptTPP}}}, by integrating the base TPP with a continuous-time retrieval prompt pool. The prompts, small learnable parameters, are stored in a memory space and jointly optimized with the base TPP, ensuring that the model learns event streams sequentially without buffering past examples or task-specific attributes. We present a novel and realistic experimental setup for modeling event streams, where PromptTPP consistently achieves state-of-the-art performance across three real user behavior datasets.
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Oct 03, 2023



Time series forecasting holds significant importance in many real-world dynamic systems and has been extensively studied. Unlike natural language process (NLP) and computer vision (CV), where a single large model can tackle multiple tasks, models for time series forecasting are often specialized, necessitating distinct designs for different tasks and applications. While pre-trained foundation models have made impressive strides in NLP and CV, their development in time series domains has been constrained by data sparsity. Recent studies have revealed that large language models (LLMs) possess robust pattern recognition and reasoning abilities over complex sequences of tokens. However, the challenge remains in effectively aligning the modalities of time series data and natural language to leverage these capabilities. In this work, we present Time-LLM, a reprogramming framework to repurpose LLMs for general time series forecasting with the backbone language models kept intact. We begin by reprogramming the input time series with text prototypes before feeding it into the frozen LLM to align the two modalities. To augment the LLM's ability to reason with time series data, we propose Prompt-as-Prefix (PaP), which enriches the input context and directs the transformation of reprogrammed input patches. The transformed time series patches from the LLM are finally projected to obtain the forecasts. Our comprehensive evaluations demonstrate that Time-LLM is a powerful time series learner that outperforms state-of-the-art, specialized forecasting models. Moreover, Time-LLM excels in both few-shot and zero-shot learning scenarios.
EasyTPP: Towards Open Benchmarking the Temporal Point Processes
Jul 16, 2023Continuous-time event sequences play a vital role in real-world domains such as healthcare, finance, online shopping, social networks, and so on. To model such data, temporal point processes (TPPs) have emerged as the most advanced generative models, making a significant impact in both academic and application communities. Despite the emergence of many powerful models in recent years, there is still no comprehensive benchmark to evaluate them. This lack of standardization impedes researchers and practitioners from comparing methods and reproducing results, potentially slowing down progress in this field. In this paper, we present EasyTPP, which aims to establish a central benchmark for evaluating TPPs. Compared to previous work that also contributed datasets, our EasyTPP has three unique contributions to the community: (i) a comprehensive implementation of eight highly cited neural TPPs with the integration of commonly used evaluation metrics and datasets; (ii) a standardized benchmarking pipeline for a transparent and thorough comparison of different methods on different datasets; (iii) a universal framework supporting multiple ML libraries (e.g., PyTorch and TensorFlow) as well as custom implementations. Our benchmark is open-sourced: all the data and implementation can be found at this \href{https://github.com/ant-research/EasyTemporalPointProcess}{\textcolor{blue}{Github repository}}\footnote{\url{https://github.com/ant-research/EasyTemporalPointProcess}.}. We will actively maintain this benchmark and welcome contributions from other researchers and practitioners. Our benchmark will help promote reproducible research in this field, thus accelerating research progress as well as making more significant real-world impacts.
Language Models Can Improve Event Prediction by Few-Shot Abductive Reasoning
May 26, 2023

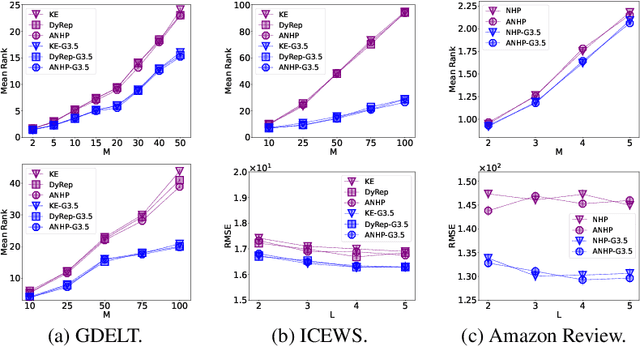
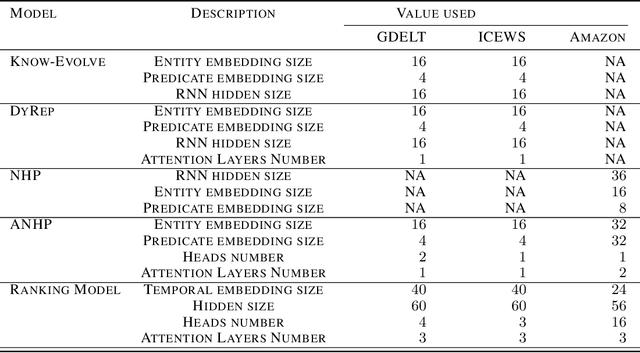
Large language models have shown astonishing performance on a wide range of reasoning tasks. In this paper, we investigate whether they could reason about real-world events and help improve the prediction accuracy of event sequence models. We design a modeling and prediction framework where a large language model performs abductive reasoning to assist an event sequence model: the event model proposes predictions on future events given the past; instructed by a few expert-annotated demonstrations, the language model learns to suggest possible causes for each proposal; a search module finds out the previous events that match the causes; a scoring function learns to examine whether the retrieved events could actually cause the proposal. Through extensive experiments on two challenging real-world datasets (Amazon Review and GDELT), we demonstrate that our framework -- thanks to the reasoning ability of language models -- could significantly outperform the state-of-the-art event sequence models.