 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting
May 23, 2024



Time series forecasting is widely used in extensive applications, such as traffic planning and weather forecasting. However, real-world time series usually present intricate temporal variations, making forecasting extremely challenging. Going beyond the mainstream paradigms of plain decomposition and multiperiodicity analysis, we analyze temporal variations in a novel view of multiscale-mixing, which is based on an intuitive but important observation that time series present distinct patterns in different sampling scales. The microscopic and the macroscopic information are reflected in fine and coarse scales respectively, and thereby complex variations can be inherently disentangled. Based on this observation, we propose TimeMixer as a fully MLP-based architecture with Past-Decomposable-Mixing (PDM) and Future-Multipredictor-Mixing (FMM) blocks to take full advantage of disentangled multiscale series in both past extraction and future prediction phases. Concretely, PDM applies the decomposition to multiscale series and further mixes the decomposed seasonal and trend components in fine-to-coarse and coarse-to-fine directions separately, which successively aggregates the microscopic seasonal and macroscopic trend information. FMM further ensembles multiple predictors to utilize complementary forecasting capabilities in multiscale observations. Consequently, TimeMixer is able to achieve consistent state-of-the-art performances in both long-term and short-term forecasting tasks with favorable run-time efficiency.
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Oct 10, 2023



The recent boom of linear forecasting models questions the ongoing passion for architectural modifications of Transformer-based forecasters. These forecasters leverage Transformers to model the global dependencies over temporal tokens of time series, with each token formed by multiple variates of the same timestamp. However, Transformer is challenged in forecasting series with larger lookback windows due to performance degradation and computation explosion. Besides, the unified embedding for each temporal token fuses multiple variates with potentially unaligned timestamps and distinct physical measurements, which may fail in learning variate-centric representations and result in meaningless attention maps. In this work, we reflect on the competent duties of Transformer components and repurpose the Transformer architecture without any adaptation on the basic components. We propose iTransformer that simply inverts the duties of the attention mechanism and the feed-forward network. Specifically, the time points of individual series are embedded into variate tokens which are utilized by the attention mechanism to capture multivariate correlations; meanwhile, the feed-forward network is applied for each variate token to learn nonlinear representations. The iTransformer model achieves consistent state-of-the-art on several real-world datasets, which further empowers the Transformer family with promoted performance, generalization ability across different variates, and better utilization of arbitrary lookback windows, making it a nice alternative as the fundamental backbone of time series forecasting.
Solving High-Dimensional PDEs with Latent Spectral Models
Jan 30, 2023



Deep models have achieved impressive progress in solving partial differential equations (PDEs). A burgeoning paradigm is learning neural operators to approximate the input-output mappings of PDEs. While previous deep models have explored the multiscale architectures and elaborative operator designs, they are limited to learning the operators as a whole in the coordinate space. In real physical science problems, PDEs are complex coupled equations with numerical solvers relying on discretization into high-dimensional coordinate space, which cannot be precisely approximated by a single operator nor efficiently learned for the curse of dimensionality. We present Latent Spectral Models (LSM) toward an efficient and precise solver for high-dimensional PDEs. Going beyond the coordinate space, LSM enables an attention-based hierarchical projection network to reduce the high-dimensional data into a compact latent space in linear time. Inspired by classical spectral methods in numerical analysis, we design a neural spectral block to solve PDEs in the latent space that well approximates complex input-output mappings via learning multiple basis operators, enjoying nice theoretical guarantees for convergence and approximation. Experimentally, LSM achieves consistent state-of-the-art and yields a relative gain of 11.5% averaged on seven benchmarks covering both solid and fluid physics.
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
Oct 05, 2022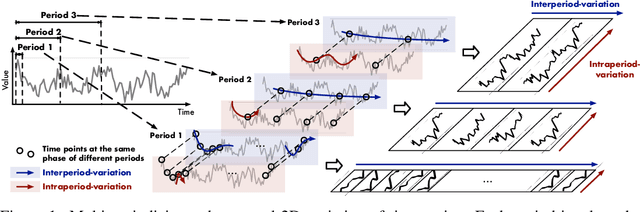
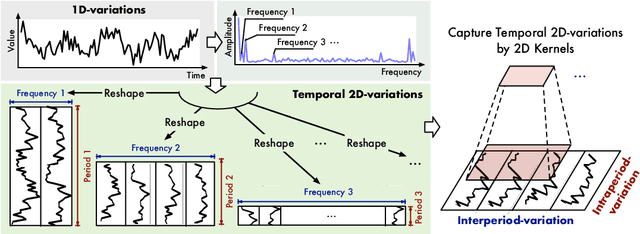

Time series analysis is of immense importance in extensive applications, such as weather forecasting, anomaly detection, and action recognition. This paper focuses on temporal variation modeling, which is the common key problem of extensive analysis tasks. Previous methods attempt to accomplish this directly from the 1D time series, which is extremely challenging due to the intricate temporal patterns. Based on the observation of multi-periodicity in time series, we ravel out the complex temporal variations into the multiple intraperiod- and interperiod-variations. To tackle the limitations of 1D time series in representation capability, we extend the analysis of temporal variations into the 2D space by transforming the 1D time series into a set of 2D tensors based on multiple periods. This transformation can embed the intraperiod- and interperiod-variations into the columns and rows of the 2D tensors respectively, making the 2D-variations to be easily modeled by 2D kernels. Technically, we propose the TimesNet with TimesBlock as a task-general backbone for time series analysis. TimesBlock can discover the multi-periodicity adaptively and extract the complex temporal variations from transformed 2D tensors by a parameter-efficient inception block. Our proposed TimesNet achieves consistent state-of-the-art in five mainstream time series analysis tasks, including short- and long-term forecasting, imputation, classification, and anomaly detection.