 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$V_{0.5}$: Generalist Value Model as a Prior for Sparse RL Rollouts
Mar 11, 2026In Reinforcement Learning with Verifiable Rewards (RLVR), constructing a robust advantage baseline is critical for policy gradients, effectively guiding the policy model to reinforce desired behaviors. Recent research has introduced Generalist Value Models (such as $V_0$), which achieve pre-trained value estimation by explicitly encoding model capabilities in-context, eliminating the need to synchronously update the value model alongside the policy model. In this paper, we propose $V_{0.5}$, which adaptively fuses the baseline predicted by such value model (acting as a prior) with the empirical mean derived from sparse rollouts. This constructs a robust baseline that balances computational efficiency with extremely low variance. Specifically, we introduce a real-time statistical testing and dynamic budget allocation. This balances the high variance caused by sparse sampling against the systematic bias (or hallucinations) inherent in the value model's prior. By constructing a hypothesis test to evaluate the prior's reliability in real-time, the system dynamically allocates additional rollout budget on demand. This mechanism minimizes the baseline estimator's Mean Squared Error (MSE), guaranteeing stable policy gradients, even under extreme sparsity with a group size of 4. Extensive evaluations across six mathematical reasoning benchmarks demonstrate that $V_{0.5}$ significantly outperforms GRPO and DAPO, achieving faster convergence and over some 10% performance improvement.
ScaleEnv: Scaling Environment Synthesis from Scratch for Generalist Interactive Tool-Use Agent Training
Feb 06, 2026Training generalist agents capable of adapting to diverse scenarios requires interactive environments for self-exploration. However, interactive environments remain critically scarce, and existing synthesis methods suffer from significant limitations regarding environmental diversity and scalability. To address these challenges, we introduce ScaleEnv, a framework that constructs fully interactive environments and verifiable tasks entirely from scratch. Specifically, ScaleEnv ensures environment reliability through procedural testing, and guarantees task completeness and solvability via tool dependency graph expansion and executable action verification. By enabling agents to learn through exploration within ScaleEnv, we demonstrate significant performance improvements on unseen, multi-turn tool-use benchmarks such as $τ^2$-Bench and VitaBench, highlighting strong generalization capabilities. Furthermore, we investigate the relationship between increasing number of domains and model generalization performance, providing empirical evidence that scaling environmental diversity is critical for robust agent learning.
$V_0$: A Generalist Value Model for Any Policy at State Zero
Feb 03, 2026Policy gradient methods rely on a baseline to measure the relative advantage of an action, ensuring the model reinforces behaviors that outperform its current average capability. In the training of Large Language Models (LLMs) using Actor-Critic methods (e.g., PPO), this baseline is typically estimated by a Value Model (Critic) often as large as the policy model itself. However, as the policy continuously evolves, the value model requires expensive, synchronous incremental training to accurately track the shifting capabilities of the policy. To avoid this overhead, Group Relative Policy Optimization (GRPO) eliminates the coupled value model by using the average reward of a group of rollouts as the baseline; yet, this approach necessitates extensive sampling to maintain estimation stability. In this paper, we propose $V_0$, a Generalist Value Model capable of estimating the expected performance of any model on unseen prompts without requiring parameter updates. We reframe value estimation by treating the policy's dynamic capability as an explicit context input; specifically, we leverage a history of instruction-performance pairs to dynamically profile the model, departing from the traditional paradigm that relies on parameter fitting to perceive capability shifts. Focusing on value estimation at State Zero (i.e., the initial prompt, hence $V_0$), our model serves as a critical resource scheduler. During GRPO training, $V_0$ predicts success rates prior to rollout, allowing for efficient sampling budget allocation; during deployment, it functions as a router, dispatching instructions to the most cost-effective and suitable model. Empirical results demonstrate that $V_0$ significantly outperforms heuristic budget allocation and achieves a Pareto-optimal trade-off between performance and cost in LLM routing tasks.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
VitaBench: Benchmarking LLM Agents with Versatile Interactive Tasks in Real-world Applications
Sep 30, 2025As LLM-based agents are increasingly deployed in real-life scenarios, existing benchmarks fail to capture their inherent complexity of handling extensive information, leveraging diverse resources, and managing dynamic user interactions. To address this gap, we introduce VitaBench, a challenging benchmark that evaluates agents on versatile interactive tasks grounded in real-world settings. Drawing from daily applications in food delivery, in-store consumption, and online travel services, VitaBench presents agents with the most complex life-serving simulation environment to date, comprising 66 tools. Through a framework that eliminates domain-specific policies, we enable flexible composition of these scenarios and tools, yielding 100 cross-scenario tasks (main results) and 300 single-scenario tasks. Each task is derived from multiple real user requests and requires agents to reason across temporal and spatial dimensions, utilize complex tool sets, proactively clarify ambiguous instructions, and track shifting user intent throughout multi-turn conversations. Moreover, we propose a rubric-based sliding window evaluator, enabling robust assessment of diverse solution pathways in complex environments and stochastic interactions. Our comprehensive evaluation reveals that even the most advanced models achieve only 30% success rate on cross-scenario tasks, and less than 50% success rate on others. Overall, we believe VitaBench will serve as a valuable resource for advancing the development of AI agents in practical real-world applications. The code, dataset, and leaderboard are available at https://vitabench.github.io/
Prompt-augmented Temporal Point Process for Streaming Event Sequence
Oct 13, 2023


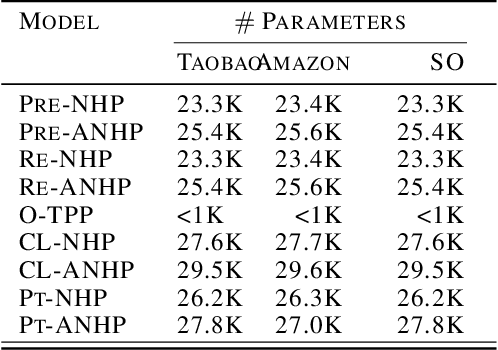
Neural Temporal Point Processes (TPPs) are the prevalent paradigm for modeling continuous-time event sequences, such as user activities on the web and financial transactions. In real-world applications, event data is typically received in a \emph{streaming} manner, where the distribution of patterns may shift over time. Additionally, \emph{privacy and memory constraints} are commonly observed in practical scenarios, further compounding the challenges. Therefore, the continuous monitoring of a TPP to learn the streaming event sequence is an important yet under-explored problem. Our work paper addresses this challenge by adopting Continual Learning (CL), which makes the model capable of continuously learning a sequence of tasks without catastrophic forgetting under realistic constraints. Correspondingly, we propose a simple yet effective framework, PromptTPP\footnote{Our code is available at {\small \url{ https://github.com/yanyanSann/PromptTPP}}}, by integrating the base TPP with a continuous-time retrieval prompt pool. The prompts, small learnable parameters, are stored in a memory space and jointly optimized with the base TPP, ensuring that the model learns event streams sequentially without buffering past examples or task-specific attributes. We present a novel and realistic experimental setup for modeling event streams, where PromptTPP consistently achieves state-of-the-art performance across three real user behavior datasets.
Enhancing Event Sequence Modeling with Contrastive Relational Inference
Sep 06, 2023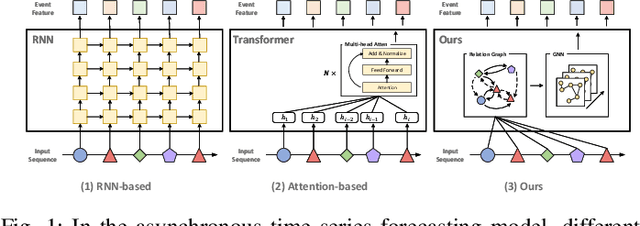
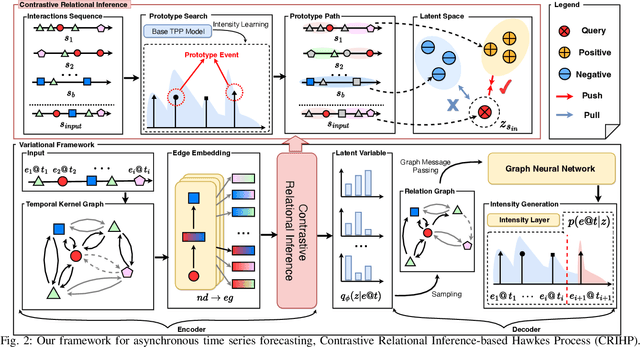
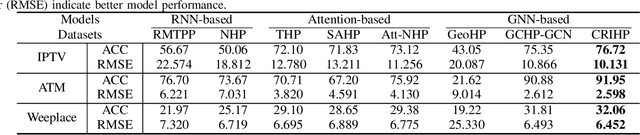
Neural temporal point processes(TPPs) have shown promise for modeling continuous-time event sequences. However, capturing the interactions between events is challenging yet critical for performing inference tasks like forecasting on event sequence data. Existing TPP models have focused on parameterizing the conditional distribution of future events but struggle to model event interactions. In this paper, we propose a novel approach that leverages Neural Relational Inference (NRI) to learn a relation graph that infers interactions while simultaneously learning the dynamics patterns from observational data. Our approach, the Contrastive Relational Inference-based Hawkes Process (CRIHP), reasons about event interactions under a variational inference framework. It utilizes intensity-based learning to search for prototype paths to contrast relationship constraints. Extensive experiments on three real-world datasets demonstrate the effectiveness of our model in capturing event interactions for event sequence modeling tasks.
Enhancing Recommender Systems with Large Language Model Reasoning Graphs
Aug 21, 2023



Recommendation systems aim to provide users with relevant suggestions, but often lack interpretability and fail to capture higher-level semantic relationships between user behaviors and profiles. In this paper, we propose a novel approach that leverages large language models (LLMs) to construct personalized reasoning graphs. These graphs link a user's profile and behavioral sequences through causal and logical inferences, representing the user's interests in an interpretable way. Our approach, LLM reasoning graphs (LLMRG), has four components: chained graph reasoning, divergent extension, self-verification and scoring, and knowledge base self-improvement. The resulting reasoning graph is encoded using graph neural networks, which serves as additional input to improve conventional recommender systems, without requiring extra user or item information. Our approach demonstrates how LLMs can enable more logical and interpretable recommender systems through personalized reasoning graphs. LLMRG allows recommendations to benefit from both engineered recommendation systems and LLM-derived reasoning graphs. We demonstrate the effectiveness of LLMRG on benchmarks and real-world scenarios in enhancing base recommendation models.
Leveraging Large Language Models for Pre-trained Recommender Systems
Aug 21, 2023



Recent advancements in recommendation systems have shifted towards more comprehensive and personalized recommendations by utilizing large language models (LLM). However, effectively integrating LLM's commonsense knowledge and reasoning abilities into recommendation systems remains a challenging problem. In this paper, we propose RecSysLLM, a novel pre-trained recommendation model based on LLMs. RecSysLLM retains LLM reasoning and knowledge while integrating recommendation domain knowledge through unique designs of data, training, and inference. This allows RecSysLLM to leverage LLMs' capabilities for recommendation tasks in an efficient, unified framework. We demonstrate the effectiveness of RecSysLLM on benchmarks and real-world scenarios. RecSysLLM provides a promising approach to developing unified recommendation systems by fully exploiting the power of pre-trained language models.
Continual Learning in Predictive Autoscaling
Aug 14, 2023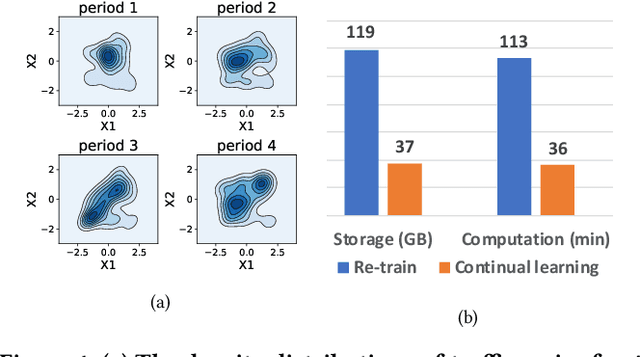
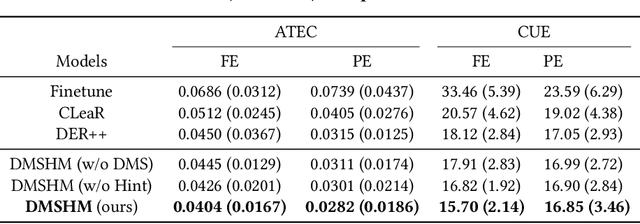
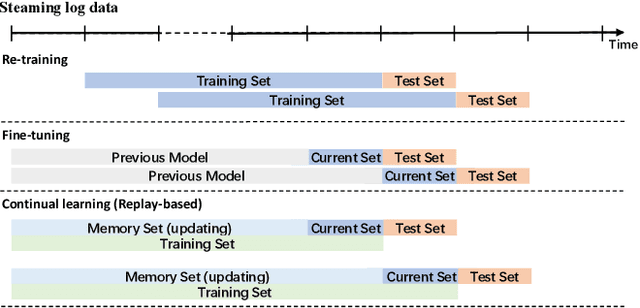
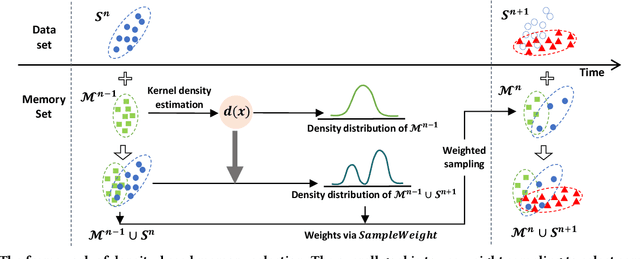
Predictive Autoscaling is used to forecast the workloads of servers and prepare the resources in advance to ensure service level objectives (SLOs) in dynamic cloud environments. However, in practice, its prediction task often suffers from performance degradation under abnormal traffics caused by external events (such as sales promotional activities and applications re-configurations), for which a common solution is to re-train the model with data of a long historical period, but at the expense of high computational and storage costs. To better address this problem, we propose a replay-based continual learning method, i.e., Density-based Memory Selection and Hint-based Network Learning Model (DMSHM), using only a small part of the historical log to achieve accurate predictions. First, we discover the phenomenon of sample overlap when applying replay-based continual learning in prediction tasks. In order to surmount this challenge and effectively integrate new sample distribution, we propose a density-based sample selection strategy that utilizes kernel density estimation to calculate sample density as a reference to compute sample weight, and employs weight sampling to construct a new memory set. Then we implement hint-based network learning based on hint representation to optimize the parameters. Finally, we conduct experiments on public and industrial datasets to demonstrate that our proposed method outperforms state-of-the-art continual learning methods in terms of memory capacity and prediction accuracy. Furthermore, we demonstrate remarkable practicability of DMSHM in real industrial applications.